



HelloWorld
简介
RabbitMQ:接受消息再传递消息,可以视为一个“邮局”。发送者和接受者通过队列来进行交互,队列的大小可以视为无限的,多个发送者可以发生给一个队列,多个接收者也可以从一个队列中接受消息。
code
rabbitmq使用的协议是amqp,用于python的推荐客户端是pika
pip install pika -i https://pypi.douban.com/simple/
send.py
# coding: utf8 import pika # 建立一个连接 connection = pika.BlockingConnection(pika.ConnectionParameters( 'localhost')) # 连接本地的RabbitMQ服务器 channel = connection.channel() # 获得channel
这里链接的是本机的,如果想要连接其他机器上的服务器,只要填入地址或主机名即可。
接下来我们开始发送消息了,注意要确保接受消息的队列是存在的,否则rabbitmq就丢弃掉该消息
channel.queue_declare(queue='hello') # 在RabbitMQ中创建hello这个队列 channel.basic_publish(exchange='', # 使用默认的exchange来发送消息到队列 routing_key='hello', # 发送到该队列 hello 中 body='Hello World!') # 消息内容 connection.close() # 关闭 同时flush
RabbitMQ默认需要1GB的空闲磁盘空间,否则发送会失败。
这时已在本地队列hello中存放了一个消息,如果使用 rabbitmqctl list_queues 可看到
hello 1
说明有一个hello队列 里面存放了一个消息
receive.py
# coding: utf8 import pika connection = pika.BlockingConnection(pika.ConnectionParameters( 'localhost')) channel = connection.channel()
还是先链接到服务器,和之前发送时相同
channel.queue_declare(queue='hello') # 此处就是声明了 来确保该队列 hello 存在 可以多次声明 这里主要是为了防止接受程序先运行时出错
def callback(ch, method, properties, body): # 用于接收到消息后的回调
print(" [x] Received %r" % body)
channel.basic_consume(callback,
queue='hello', # 收指定队列hello的消息
no_ack=True) #在处理完消息后不发送ack给服务器
channel.start_consuming() # 启动消息接受 这会进入一个死循环
工作队列(任务队列)
工作队列是用于分发耗时任务给多个工作进程的。不立即做那些耗费资源的任务(需要等待这些任务完成),而是安排这些任务之后执行。例如我们把task作为message发送到队列里,启动工作进程来接受并最终执行,且可启动多个工作进程来工作。这适用于web应用,即不应在一个http请求的处理窗口内完成复杂任务。
channel.basic_publish(exchange='', routing_key='task_queue', body=message, properties=pika.BasicProperties( delivery_mode = 2, # 使得消息持久化 ))
分配消息的方式为 轮询 即每个工作进程获得相同的消息数。
消息ack
如果消息分配给某个工作进程,但是该工作进程未处理完成就崩溃了,可能该消息就丢失了,因为rabbitmq一旦把一个消息分发给工作进程,它就把该消息删掉了。
为了预防消息丢失,rabbitmq提供了ack,即工作进程在收到消息并处理后,发送ack给rabbitmq,告知rabbitmq这时候可以把该消息从队列中删除了。如果工作进程挂掉 了,rabbitmq没有收到ack,那么会把该消息 重新分发给其他工作进程。不需要设置timeout,即使该任务需要很长时间也可以处理。
ack默认是开启的,之前我们的工作进程显示指定了no_ack=True
channel.basic_consume(callback, queue='hello') # 会启用ack
带ack的callback:
def callback(ch, method, properties, body):
print " [x] Received %r" % (body,)
time.sleep( body.count('.') )
print " [x] Done"
ch.basic_ack(delivery_tag = method.delivery_tag) # 发送ack
消息持久化
但是,有时RabbitMQ重启了,消息也会丢失。可在创建队列时设置持久化:
(队列的性质一旦确定无法改变)
channel.queue_declare(queue='task_queue', durable=True)
同时在发送消息时也得设置该消息的持久化属性:
channel.basic_publish(exchange='',
routing_key="task_queue", body=message, properties=pika.BasicProperties( delivery_mode = 2, # make message persistent ))
但是,如果在RabbitMQ刚接收到消息还没来得及存储,消息还是会丢失。同时,RabbitMQ也不是在接受到每个消息都进行存盘操作。如果还需要更完善的保证,需要使用publisher confirm。
公平的消息分发
轮询模式的消息分发可能并不公平,例如奇数的消息都是繁重任务的话,某些进程则会一直运行繁 重任务。即使某工作进程上有积压的消息未处理,如很多都没发ack,但是RabbitMQ还是会按照顺序发消息给它。可以在接受进程中加设置:
channel.basic_qos(prefetch_count=1)
告知RabbitMQ,这样在一个工作进程没回发ack情况下是不会再分配消息给它。
群发
一般情况下,一条消息是发送给一个工作进程,然后完成,有时想把一条消息同时发送给多个进程:
exchange
发送者是不是直接发送消息到队列中的,事实上发生者根本不知道消息会发送到那个队列,发送者只能把消息发送到exchange里。exchange一方面收生产者的消息,另一方面把他们推送到队列中。所以作为exchange,它需要知道当收到消息时它需要做什么,是应该把它加到一个特殊的队列中还是放到很多的队列中,或者丢弃。exchange有direct、topic、headers、fanout等种类,而群发使用的即fanout。之前在发布消息时,exchange的值为 '' 即使用default exchange。
channel.exchange_declare(exchange='logs', type='fanout') # 该exchange会把消息发送给所有它知道的队列中
临时队列
result = channel.queue_declare() # 创建一个随机队列 result = channel.queue_declare(exclusive=True) # 创建一个随机队列,同时在没有接收者连接该队列后则销毁它 queue_name = result.method.queue
这样result.method.queue即是队列名称,在发送或接受时即可使用。
绑定exchange 和 队列
channel.queue_bind(exchange='logs', queue='hello')
logs在发送消息时给hello也发一份。
在发送消息是使用刚刚创建的 logs exchange
channel.basic_publish(exchange='logs', routing_key='', body=message)
路由
之前已经使用过bind,即建立exchange和queue的关系(该队列对来自该exchange的消息有兴趣),bind时可另外指定routing_key选项。
使用direct exchange
将对应routing key的消息发送到绑定相同routing key的队列中
channel.exchange_declare(exchange='direct_logs', type='direct')
发送函数,发布不同severity的消息:
channel.basic_publish(exchange='direct_logs', routing_key=severity, body=message)
接受函数中绑定对应severity的:
channel.queue_bind(exchange='direct_logs', queue=queue_name, routing_key=severity)
使用topic exchange
之前使用的direct exchange 只能绑定一个routing key,可以使用这种可以拿.隔开routing key的topic exchange,例如:
"stock.usd.nyse" "nyse.vmw"
和direct exchange一样,在接受者那边绑定的key与发送时指定的routing key相同即可,另外有些特殊的值:
* 代表1个单词 # 代表0个或多个单词
如果发送者发出的routing key都是3个部分的,如:celerity.colour.species。
Q1: *.orange.* 对应的是中间的colour都为orange的 Q2: *.*.rabbit 对应的是最后部分的species为rabbit的 lazy.# 对应的是第一部分是lazy的
qucik.orange.rabbit Q1 Q2都可接收到,quick.orange.fox 只有Q1能接受到,对于lazy.pink.rabbit虽然匹配到了Q2两次,但是只会发送一次。如果绑定时直接绑定#,则会收到所有的。
RPC
在远程机器上运行一个函数然后获得结果。
1、客户端启动 同时设置一个临时队列用于接受回调,绑定该队列
self.connection = pika.BlockingConnection(pika.ConnectionParameters( host='localhost')) self.channel = self.connection.channel() result = self.channel.queue_declare(exclusive=True) self.callback_queue = result.method.queue self.channel.basic_consume(self.on_response, no_ack=True, queue=self.callback_queue)
2、客户端发送rpc请求,同时附带reply_to对应回调队列,correlation_id设置为每个请求的唯一id(虽然说可以为每一次RPC请求都创建一个回调队列,但是这样效率不高,如果一个客户端只使用一个队列,则需要使用correlation_id来匹配是哪个请求),之后阻塞在回调队列直到收到回复
注意:如果收到了非法的correlation_id直接丢弃即可,因为有这种情况--服务器已经发了响应但是还没发ack就挂了,等一会服务器重启了又会重新处理该任务,又发了一遍相应,但是这时那个请求已经被处理掉了
channel.basic_publish(exchange='', routing_key='rpc_queue', properties=pika.BasicProperties( reply_to = self.callback_queue, correlation_id = self.corr_id, ), body=str(n)) # 发出调用 while self.response is None: # 这边就相当于阻塞了 self.connection.process_data_events() # 查看回调队列 return int(self.response)
3、请求会发送到rpc_queue队列
4、RPC服务器从rpc_queue中取出,执行,发送回复
channel.basic_consume(on_request, queue='rpc_queue') # 绑定 等待请求 # 处理之后: ch.basic_publish(exchange='', routing_key=props.reply_to, properties=pika.BasicProperties(correlation_id = \ props.correlation_id), body=str(response)) # 发送回复到回调队列 ch.basic_ack(delivery_tag = method.delivery_tag) # 发送ack
5、客户端从回调队列中取出数据,检查correlation_id,执行相应操作
if self.corr_id == props.correlation_id: self.response = body
以上是RabbitMQ快速入门python教程的详细内容。更多信息请关注PHP中文网其他相关文章!

 如何在PHP中使用RabbitMQ实现分布式消息处理Jul 18, 2023 am 11:00 AM
如何在PHP中使用RabbitMQ实现分布式消息处理Jul 18, 2023 am 11:00 AM如何在PHP中使用RabbitMQ实现分布式消息处理引言:在大规模应用程序开发中,分布式系统已成为一个常见的需求。分布式消息处理是这样的一种模式,通过将任务分发到多个处理节点,可以提高系统的效率和可靠性。RabbitMQ是一个开源的,可靠的消息队列系统,它采用AMQP协议来实现消息的传递和处理。在本文中,我们将介绍如何在PHP中使用RabbitMQ来实现分布
 SpringBoot怎么整合RabbitMQ实现延迟队列May 16, 2023 pm 08:31 PM
SpringBoot怎么整合RabbitMQ实现延迟队列May 16, 2023 pm 08:31 PM如何保证消息不丢失rabbitmq消息投递路径生产者->交换机->队列->消费者总的来说分为三个阶段。1.生产者保证消息投递可靠性。2.mq内部消息不丢失。3.消费者消费成功。什么是消息投递可靠性简单点说就是消息百分百发送到消息队列中。我们可以开启confirmCallback生产者投递消息后,mq会给生产者一个ack.根据ack,生产者就可以确认这条消息是否发送到mq.开启confirmCallback修改配置文件#NONE:禁用发布确认模式,是默认值,CORRELATED:
 在Go语言中使用RabbitMQ:完整指南Jun 19, 2023 am 08:10 AM
在Go语言中使用RabbitMQ:完整指南Jun 19, 2023 am 08:10 AM随着现代应用程序的复杂性增加,消息传递已成为一种强大的工具。在这个领域,RabbitMQ已成为一个非常受欢迎的消息代理,可以用于在不同的应用程序之间传递消息。在这篇文章中,我们将探讨如何在Go语言中使用RabbitMQ。本指南将涵盖以下内容:RabbitMQ简介RabbitMQ安装RabbitMQ基础概念Go语言中的RabbitMQ入门RabbitMQ和Go
 go-zero与RabbitMQ的应用实践Jun 23, 2023 pm 12:54 PM
go-zero与RabbitMQ的应用实践Jun 23, 2023 pm 12:54 PM现在越来越多的企业开始采用微服务架构模式,而在这个架构中,消息队列成为一种重要的通信方式,其中RabbitMQ被广泛应用。而在go语言中,go-zero是近年来崛起的一种框架,它提供了很多实用的工具和方法,让开发者更加轻松地使用消息队列,下面我们将结合实际应用,来介绍go-zero和RabbitMQ的使用方法和应用实践。1.RabbitMQ概述Rabbit
 Swoole与RabbitMQ集成实践:打造高可用性消息队列系统Jun 14, 2023 pm 12:56 PM
Swoole与RabbitMQ集成实践:打造高可用性消息队列系统Jun 14, 2023 pm 12:56 PM随着互联网时代的到来,消息队列系统变得越来越重要。它可以使不同的应用之间实现异步操作、降低耦合度、提高可扩展性,进而提升整个系统的性能和用户体验。在消息队列系统中,RabbitMQ是一个强大的开源消息队列软件,它支持多种消息协议、被广泛应用于金融交易、电子商务、在线游戏等领域。在实际应用中,往往需要将RabbitMQ和其他系统进行集成。本文将介绍如何使用sw
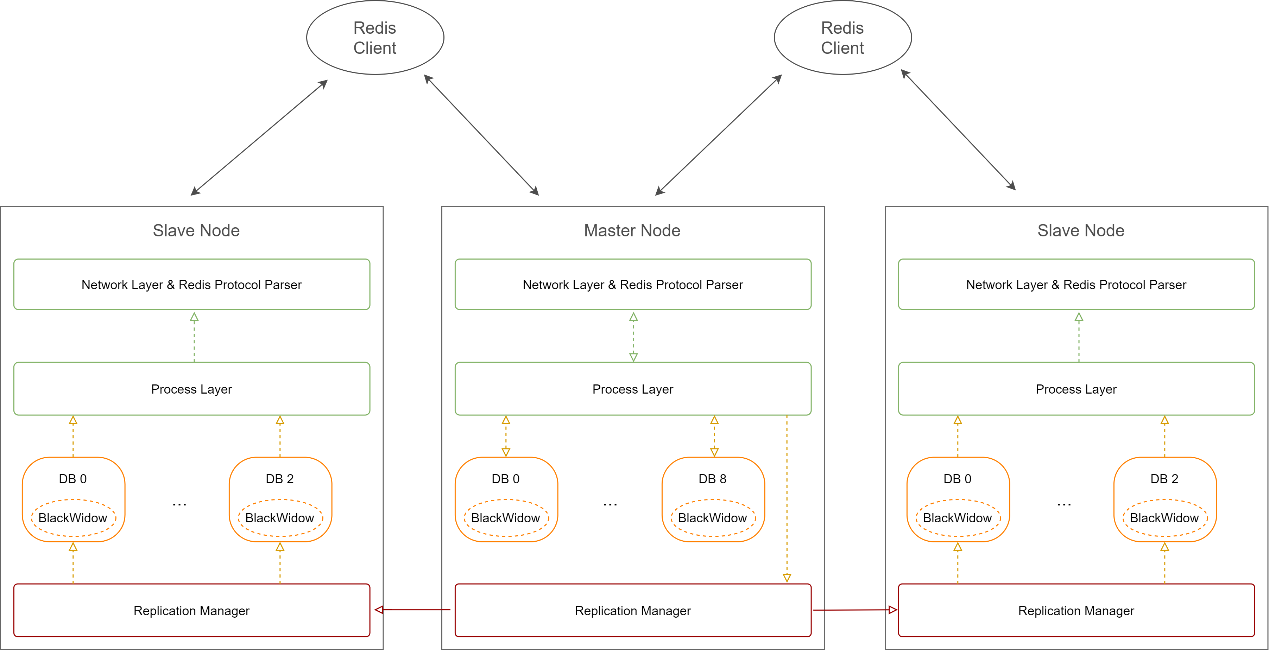 Redis存储系统Pika架构设计的方法是什么May 29, 2023 pm 08:07 PM
Redis存储系统Pika架构设计的方法是什么May 29, 2023 pm 08:07 PMPika是360基础架构团队和DBA团队联合研发的一款高效、稳定、简单可依赖的开源的NoSQL数据库产品。完全兼容Redis协议,支持5种数据结构(string,hash,list,set,zset),数据持久化到RocksDB,相比于Redis内存的存储方式,能极大减少服务器资源的占用,增强了数据的可靠性。可以采用单机和集群两种模式部署。Pika项目2015年启动,随后在Github上开源,现有3700stars,35个contributors,社区有大量的线上业务使Pika。对比Redis存
 SpringBoot怎么整合RabbitMQ处理死信队列和延迟队列May 15, 2023 pm 03:28 PM
SpringBoot怎么整合RabbitMQ处理死信队列和延迟队列May 15, 2023 pm 03:28 PM简介RabbitMQ消息简介RabbitMQ的消息默认不会超时。什么是死信队列?什么是延迟队列?死信队列:DLX,全称为Dead-Letter-Exchange,可以称之为死信交换器,也有人称之为死信邮箱。当消息在一个队列中变成死信(deadmessage)之后,它能被重新被发送到另一个交换器中,这个交换器就是DLX,绑定DLX的队列就称之为死信队列。以下几种情况会导致消息变成死信:消息被拒绝(Basic.Reject/Basic.Nack),并且设置requeue参数为false;消息过期;队
 Pika推出音画同步新功能一天后,翻车视频来了Mar 11, 2024 pm 04:10 PM
Pika推出音画同步新功能一天后,翻车视频来了Mar 11, 2024 pm 04:10 PMPika的音效新功能「SoundEffects」,有大大的惊喜,也有小小的「惊吓」。Sora的出现让文生视频模型及应用火了起来。不过,此类模型生成的视频大多数都是无声的。因此,人们开始探索为AI生成的视频「配音」。这一领域的代表有AI语音克隆初创公司ElevenLab,此前该公司为Sora的演示视频生成配音,音效与视频画面几乎没有违和感。现在,曾经引爆了AI圈的视频生成初创公司Pika终于有了新动作——推出SoundEffects,可以为Pika生成的视频无缝加音效了。Pika生成


热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

WebStorm Mac版
好用的JavaScript开发工具

Dreamweaver Mac版
视觉化网页开发工具

安全考试浏览器
Safe Exam Browser是一个安全的浏览器环境,用于安全地进行在线考试。该软件将任何计算机变成一个安全的工作站。它控制对任何实用工具的访问,并防止学生使用未经授权的资源。

VSCode Windows 64位 下载
微软推出的免费、功能强大的一款IDE编辑器

记事本++7.3.1
好用且免费的代码编辑器

