



一、进行迁移的原因
由于业务的发展,使用mysql进行建立索引进行搜索已经造成数据流的瓶颈卡在了数据库io,例如每次dump全表的时候,会造成压力过大,造成耗时很长,并且当前的数据量基本上已经达到了亿级别的数据量,如果希望mysql能更好的提供服务,下一步必须考虑分库分表才可以;基于这种情况下,考虑使用hbase用来进行数据的存储,因为hbase所能承受的数据量远大于mysql,并且对列的扩展也很方便
二、关系型数据库与Nosql的一些区别
(1)存储方式的区别
在类似mysql,sqlserver,oracle等关系型数据库,数据的存储是按照行进行存储的,如下图所示:
但是在hbase里面,所有的数据是基于列进行存储的,如下所示:

其中hbase的逻辑模型如下所示:
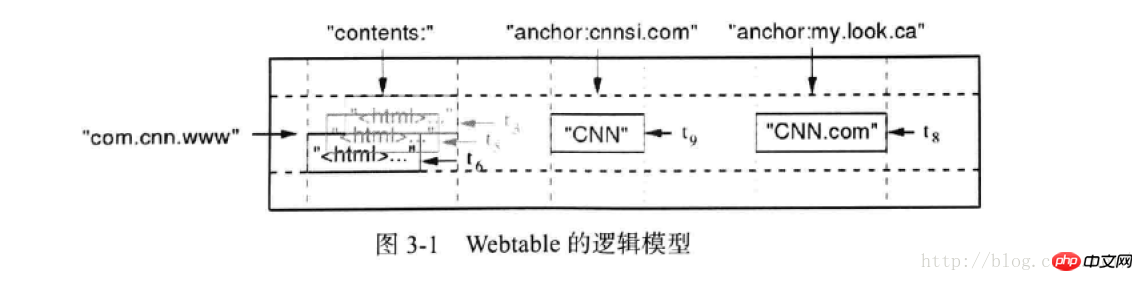
其中:com.cnn.ww对应的是rowkey,相当于mysql的主键的概念
contents,anchor:这两个对应的是列族的概念,在物理的存储上,同一个列族的数据存储在相同文件
cnnsi.com,mylook.ca:对应的是列族下面的列,在hbase中列是可以动态增加的
对应的方格数据表示的是单元数据,即对应rowkey,cf:column下面的具体的值
其中tn:表示的是时间戳,单元数据的不同版本
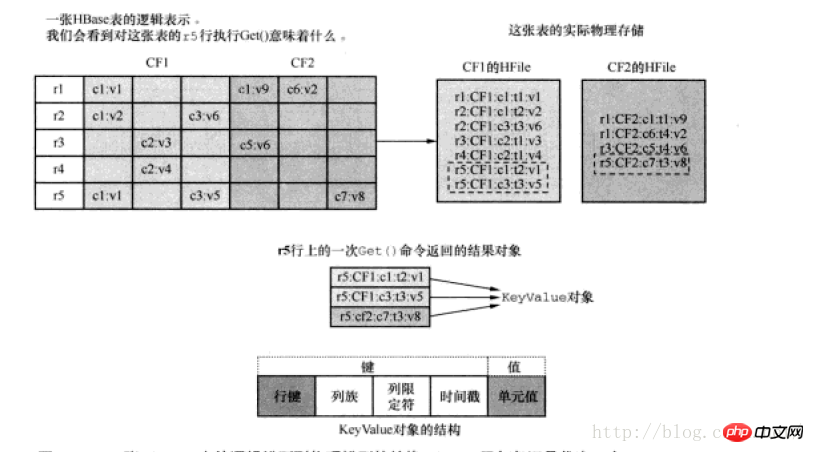
其中有一张存储结构如下:
(2)CRUD一些区别
CRUD是数据库的最基本也是最常用的操作,在hbase里面也有对应的命令,例如建表语句对于mysql的在此不详述,对于hbase shell的如下所示
create ‘table’,‘columnfamily’
即可以创建一个名为table,列族为columnfamily的表,其他的一些blocksize,version数据为默认
读取数据的时候,在hbase语句如:get ‘table’,'row',‘cf:column’即可得到对应的数据
更新数据的时候,在hbase中没有对应更新的概念,只是会有一个新的版本,从时间戳上可以体现出来,所用的语句为
put ‘table’,‘row’,‘cf:name’,‘value’
即可将value的值赋给对应cf列族,name的列
删除数据的区别,在mysql中删除数据只能是直接删除一行,或者将某一列置为空,在hbase里面可以直接删除某一列
(3)索引的区别
在mysql中可以建立索引,或者过滤查询,但是在hbase中,只支持按照rowkey进行查询速率最快
(4)从mysql到nosql的发展的思考
关系型数据库的历史已经很久,但是当数据量膨胀之后,例如对于mysql数据库,当数据量为上亿或者更多的时候,如果按照索引进行查询,可能效果 也不是特别的明显,最后只能按照主键进行查询,或者逐渐发展为分库分表的模式,但是分库分表又给运维以及使用带来了很大的麻烦;于是这个时候,nosql数据库主键发展,nosql简称not only sql,是在数据量暴增的当前逐渐发展壮大起来,以nosql里面的hbase作为例子,支持TB以及PB的数据,并且列的扩展特别的灵活
(5)hbase为什么可以存储海量的数据呢
其实hbase可以看做是mysql分库分表后的结果,只是不同的是mysql分库分表后支持索引等,但是对于hbase仅仅支持rowkey作为主键索引,从书中可以知道,hbase的数据是按照列进行存储的,并且当数据过大的时候,会按照行进行分裂,如下如所示:
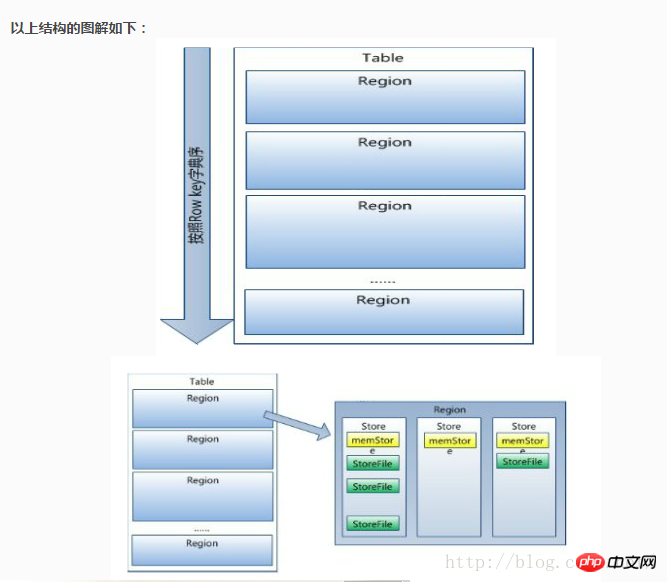
把不同的region放到了不同的机器,并且最后还有master进行管理,即相当于对行列进行了一个划分,从而存储大量的数据
三、数据迁移遇到的一些问题
(1)联合索引的问题
在mysql中会有一些联合索引的情况,例如存在一个商品与分类对应关系的表,需要得到某一个商品的所有分类,也希望可以得到某一个分类的所有商品,在mysql中直接按照联合索引可以达到要求,但是在hbase的时候只能按照rowkey查询如何办呢
经过阅读相关的数据得到有如下两种的解决办法
1、构建宽表
在hbase中,允许行跟行之间的列是不同的,只要有共同的列族即可,那么对于上述的情况,可以构建一个按照分类为rowkey的宽表,如下所示
分类id,作为rowkey
product_id,作为列名字
value存储为是否删除

上述即可rowkey为分类id,可以直接从row得到所有的product_id,然后自己过滤是否删除
2、构建高表
什么是构建高表呢,也就是说不需要那么多的列,只是存储多行,因为在hbase里面是按照字典顺序排序的,因此可以进行如下的设计
分类id_商品id,作为rowkey

只要scan以1开头的行,就可以得到所有的数据
上述两种办法从本质上来说,都是构建了一个二级索引来存储数据
以上就是数据从mysql迁移到hbase的一些思考及设计的内容,更多相关内容请关注PHP中文网(www.php.cn)!

 MySQL的许可与其他数据库系统相比如何?Apr 25, 2025 am 12:26 AM
MySQL的许可与其他数据库系统相比如何?Apr 25, 2025 am 12:26 AMMySQL使用的是GPL许可证。1)GPL许可证允许自由使用、修改和分发MySQL,但修改后的分发需遵循GPL。2)商业许可证可避免公开修改,适合需要保密的商业应用。
 您什么时候选择InnoDB而不是Myisam,反之亦然?Apr 25, 2025 am 12:22 AM
您什么时候选择InnoDB而不是Myisam,反之亦然?Apr 25, 2025 am 12:22 AM选择InnoDB而不是MyISAM的情况包括:1)需要事务支持,2)高并发环境,3)需要高数据一致性;反之,选择MyISAM的情况包括:1)主要是读操作,2)不需要事务支持。InnoDB适合需要高数据一致性和事务处理的应用,如电商平台,而MyISAM适合读密集型且无需事务的应用,如博客系统。
 在MySQL中解释外键的目的。Apr 25, 2025 am 12:17 AM
在MySQL中解释外键的目的。Apr 25, 2025 am 12:17 AM在MySQL中,外键的作用是建立表与表之间的关系,确保数据的一致性和完整性。外键通过引用完整性检查和级联操作维护数据的有效性,使用时需注意性能优化和避免常见错误。
 MySQL中有哪些不同类型的索引?Apr 25, 2025 am 12:12 AM
MySQL中有哪些不同类型的索引?Apr 25, 2025 am 12:12 AMMySQL中有四种主要的索引类型:B-Tree索引、哈希索引、全文索引和空间索引。1.B-Tree索引适用于范围查询、排序和分组,适合在employees表的name列上创建。2.哈希索引适用于等值查询,适合在MEMORY存储引擎的hash_table表的id列上创建。3.全文索引用于文本搜索,适合在articles表的content列上创建。4.空间索引用于地理空间查询,适合在locations表的geom列上创建。
 您如何在MySQL中创建索引?Apr 25, 2025 am 12:06 AM
您如何在MySQL中创建索引?Apr 25, 2025 am 12:06 AMtoCreateAnIndexinMysql,usethecReateIndexStatement.1)forasingLecolumn,使用“ createIndexIdx_lastNameEnemployees(lastName); 2)foracompositeIndex,使用“ createIndexIndexIndexIndexIndexDx_nameOmplayees(lastName,firstName,firstName);” 3)forauniqe instex,creationexexexexex,
 MySQL与Sqlite有何不同?Apr 24, 2025 am 12:12 AM
MySQL与Sqlite有何不同?Apr 24, 2025 am 12:12 AMMySQL和SQLite的主要区别在于设计理念和使用场景:1.MySQL适用于大型应用和企业级解决方案,支持高性能和高并发;2.SQLite适合移动应用和桌面软件,轻量级且易于嵌入。
 MySQL中的索引是什么?它们如何提高性能?Apr 24, 2025 am 12:09 AM
MySQL中的索引是什么?它们如何提高性能?Apr 24, 2025 am 12:09 AMMySQL中的索引是数据库表中一列或多列的有序结构,用于加速数据检索。1)索引通过减少扫描数据量提升查询速度。2)B-Tree索引利用平衡树结构,适合范围查询和排序。3)创建索引使用CREATEINDEX语句,如CREATEINDEXidx_customer_idONorders(customer_id)。4)复合索引可优化多列查询,如CREATEINDEXidx_customer_orderONorders(customer_id,order_date)。5)使用EXPLAIN分析查询计划,避
 说明如何使用MySQL中的交易来确保数据一致性。Apr 24, 2025 am 12:09 AM
说明如何使用MySQL中的交易来确保数据一致性。Apr 24, 2025 am 12:09 AM在MySQL中使用事务可以确保数据一致性。1)通过STARTTRANSACTION开始事务,执行SQL操作后用COMMIT提交或ROLLBACK回滚。2)使用SAVEPOINT可以设置保存点,允许部分回滚。3)性能优化建议包括缩短事务时间、避免大规模查询和合理使用隔离级别。


热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

Video Face Swap
使用我们完全免费的人工智能换脸工具轻松在任何视频中换脸!

热门文章
热工具

WebStorm Mac版
好用的JavaScript开发工具

Dreamweaver CS6
视觉化网页开发工具

适用于 Eclipse 的 SAP NetWeaver 服务器适配器
将Eclipse与SAP NetWeaver应用服务器集成。

EditPlus 中文破解版
体积小,语法高亮,不支持代码提示功能

安全考试浏览器
Safe Exam Browser是一个安全的浏览器环境,用于安全地进行在线考试。该软件将任何计算机变成一个安全的工作站。它控制对任何实用工具的访问,并防止学生使用未经授权的资源。

