


这个Java内存模型指定的是Java虚拟机如何跟计算机内存(RAM)一起工作。这个Java虚拟机是整个计算机的模型,以至于这个模型自然的包括的一个内存模型----也叫作Java内存模型。
理解Java内存模型是很重要的,如果你想正确的设计并发程序。这个Java内存模型指的是如何以及什么时间不同的线程可以看到被其他线程写入的共享变量的值,以及如何同步的访问共享变量。
最初的Java内存模型是不足的,以至于在Java1.5版本中Java内存模型被改进了。这个Java内存模型的版本在Java8中仍然被使用。
内部的Java内存模型
Java内存模型在JVM内部的使用,是通过划分为线程栈和堆来使用的。这个图示是通过逻辑的角度来看内存模型的:
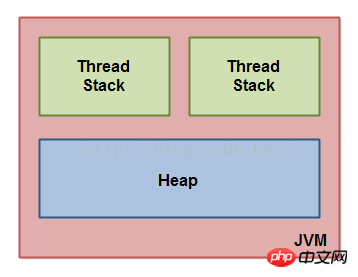
每一个运行在Java虚拟机的线程都有它自己的线程栈。这个线程栈包含了关于这个线程已经调用达到当前执行的点的方法的信息。我们也会称之为“调用栈”。随着线程执行它的代码,这个调用栈就会改变。
这个线程栈也会包含对于正在执行的每一个方法的所有的本地变量(在调用栈上的所有方法)。一个线程只能访问它自己的线程栈。被一个线程创建的本地变量对于其他所有的线程是不可见的。甚至如果两个线程正在执行完全相同的代码,这两个线程仍然是创建他们各自的本地变量。因此,每一个线程都有它们自己的本地变量的版本。
所有基本类型的本地变量(boolean,byte,short,char,int,long,float,double)是完全的存储在线程栈中,因此对其他线程是不可见的。一个线程可能会传递一个基本类型变量的拷贝给另外一个线程,但是它仍然不能共享这个基础类型的本地变量。
这个堆包含了你的应用中创建的所有的对象,不管什么线程创建了这个对象。这个包括了基本类型的对象版本(例如,Byte,Integer,Long等等)。不管是否一个对象被创建,并且分配给一个本地变量,或者创建一个另一个对象的成员变量,这个对象仍然存储在堆中。
这里有一个图示显示这个调用栈和本地变量存储在线程栈中,以及对象存储在堆中:
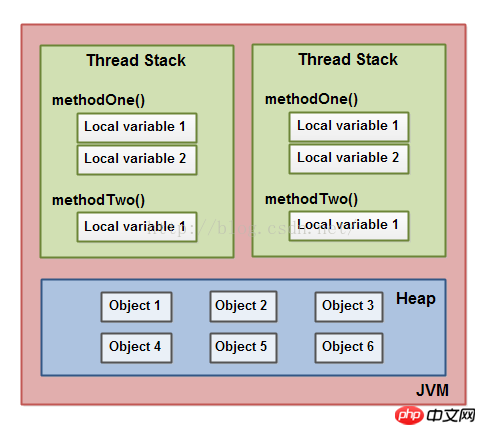
一个本地变量可能是一个基本类型,这样的话它就会完全的保存在线程栈中。
一个本地变量可能是一个对象引用。在这种场景下这个引用(本地变量)存储在线程栈中,但是这个对象自己存储在堆中。
一个对象可能包含方法,以及这些方法包含本地变量。这些本地变量也是存储在线程栈中,甚至如果这个方法属于的对象存储在堆中。
一个对象的成员变量伴随着对象自己存储在堆中。不仅这个成员变量是基本类型的时候,而且如果它是一个对象的引用。
静态类变量也会存储在堆中。
在堆中的对象可以被有这个对象引用的所有线程访问。当一个线程访问一个对象的时候,它也可以访问这个对象的成员变量。如果两个线程同时调用相同对象的一个方法,他们将会同时访问这个对象的成员变量,但是每一个线程都会有他们自己的本地变量的拷贝。
这里有一个基于上面说明的一个图示:
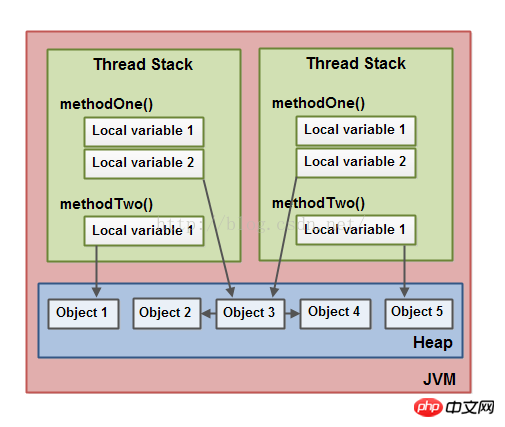
两个线程有一个本地变量集。本地变量中的一个(Locale Variable 2)指向了堆中的共同的对象(Object 3)。这两个线程每一个都有一个相同对象的不同的引用。他们引用的本地变量都是存储在线程栈中,但是这两个不同的引用指向的相同对象是在堆中。
注意这个共享对象(Object 3)是怎样引用对象2和对象4作为成员变量(图示中的箭头所示)。通过Object3中的这些变量的引用,两个线程也可以访问对象2和对象4。
这个图示也显示了一个本地变量指向了堆中的两个不同的对象。在这种场景下这个引用就会指向两个不同的对象(对象1和对象5),不是相同的对象。理论上两个对象既能访问对象1,也能访问对象5,如果两个线程都有这两个对象的引用的话。但是在图示中每一个线程只是有这两个对象的一个引用。
所以什么样的代码会出现上图的内存结构呢?好吧,就像下面的代码那样简答:
public class MyRunnable implements Runnable() {
public void run() {
methodOne();
}
public void methodOne() {
int localVariable1 = 45;
MySharedObject localVariable2 =
MySharedObject.sharedInstance;
//... do more with local variables.
methodTwo();
}
public void methodTwo() {
Integer localVariable1 = new Integer(99);
//... do more with local variable.
}
}public class MySharedObject {
//static variable pointing to instance of MySharedObject
public static final MySharedObject sharedInstance =
new MySharedObject();
//member variables pointing to two objects on the heap
public Integer object2 = new Integer(22);
public Integer object4 = new Integer(44);
public long member1 = 12345;
public long member1 = 67890;
}如果两个线程正在执行这个run方法,然后这个图示将会更早的显示这个结果。这个run方法调用methodOne方法,以及methodOne方法调用methodTwo方法。
methodOne方法声明了一个基本类型的本地变量(int类型),以及一个对象引用的本地变量。
每一个线程执行methodOne方法的时候,在他们各自的线程栈中创建它们自己的localVariable1和localVariable2的拷贝。这个localVariable1将会彼此完全的分离,只是存活在各自的线程栈中,一个线程不能看到另外一个线程对localVariable1的改变。
每一个线程执行methodOne方法也会创建localVariable2它们自己的拷贝。然而,这两个localVariable2的不同拷贝都是指向堆中相同的对象。这个代码设置localVariable2通过一个静态变量去指向一个对象的引用。这里只有一个静态变量的拷贝,并且这个拷贝是在堆中。因此,localVariable2中的两个拷贝都是以指向相同实例而结束。这个MySharedObject也是存储在堆中。它相当于上面图中的对象3。
注意,这个MySharedObject类也包含了两个成员变量。这个成员变量他们自己伴随着对象存储在堆中。这两个成员变量指向了两个其他的Integer对象。这些Integer对象相当于上图中的对象2和对象4。
也要注意methodTwo方法是如何创建了一个localVariable1的本地变量。这个本地变量是一个指向Integer对象的一个引用。这个方法设置这个localVariable1引用指向一个新的Integer实例。这个localVariable1引用将会存储在正在执行的methodTwo方法中每一个线程的一个拷贝。这两个实例化的Integer对象将会存储在堆中,但是这个方法每次执行的时候都会创建一个新的Integer对象,执行这个方法的两个线程将会创建分离的Integer实例。在methodTwo方法内部创建的Integer对象相当于上图中的对象1和对象5。
也要注意在MySharedObject类中的long类型的两个成员变量,是基本类型的。因为这些变量是成员变量,他们仍然伴随着对象存储在堆中。只是本地变量会存储在线程栈中。
硬件内存体系结构
现在的硬件内存体系结构跟内部的Java内存模型是稍微不同的。理解硬件内存体系结构也是重要的,去理解Java内存模型如何工作是有帮助的。这个部分描述公共的硬件内存框架,以及后面的部分介绍Java内存模型是如何跟它工作的。
这里有一个现代计算机硬件结构的简化图示:
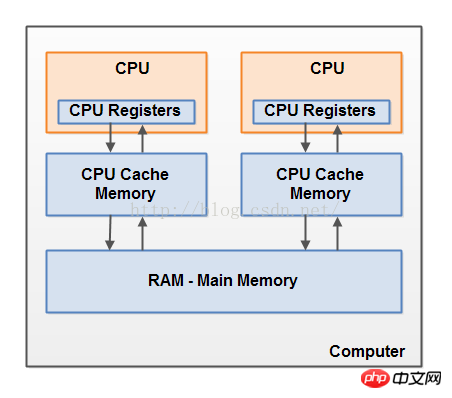
现在的计算机经常有两个或者更多的CPU。这些CPU中的一些可能有多核。要点是,有两个或者更多CPU的计算机可能有不止一个线程同时在运行。每一个CPU在任何给予的时间能运行一个线程,在你的Java应用中可能一个CPU一个线程在同时运行。
每一个CPU包含一系列的寄存器,这个实质上是CPU内存。这个CPU在寄存器上执行相对于在主内存上执行来说会更快一些。那是因为CPU访问寄存器比访问主内存更快一些。
每一个CPU可能也有一个CPU缓存的内存层。事实上,大部分现在的CPU都有一定大小的缓存内存层。这个CPU访问缓存内存层比主内存快多了,但是不会和访问内部的寄存器一样快。以至于,这个CPU缓存内存的访问速度是介于内部寄存器和主内存之间的。一些CPU可能有多级缓存(级别1和级别2),但是这个是不重要的去知道理解Java内存模型与内存的相互作用。重要的是知道CPU可能有一个缓存内存层。
一个计算机也包含一个主内存区域(RAM)。所有的CPU都可以访问这个主内存。这个主内存典型的比CPU的缓存内存更大。
作为代表性的,当CPU需要访问主内存的时候,它将会读取主内存的部分进入CPU缓存。它可能甚至读取缓存的部分进去寄存器,然后在这里执行操作。当这个CPU需要把结果写回到主内存的时候,他将会从内部的寄存器中冲刷到缓存内存中,并且在某个点上把这个值冲刷到主内存中。
存储在缓存内存中的这些值当CPU需要在此存储一些其他东西的时候会被冲刷到主内存。这个CPU缓存有时候可能被写到他的部分内存中,并且有的时候会冲刷他的部分内存。她不需要每次都去读和写这个完整缓存。典型的,这个缓存在更小的内存块中被更新称之为“缓存行”。一个或者更多的缓存行可能会读取到缓存内存中,并且一个或者更多的缓存行会再一次被刷新到主内存中。
在Java内存模型和硬件内存结构之间缩小差距
正如已经提到的,Java内存模型和硬件内存结构是不同的。这个硬件内存结构不会区分线程栈和堆。在硬件中,线程栈和堆都位于主内存中。线程栈和堆得部分可能有的时候会呈现在CPU缓存中和内部的CPU寄存器中,如下图所示:
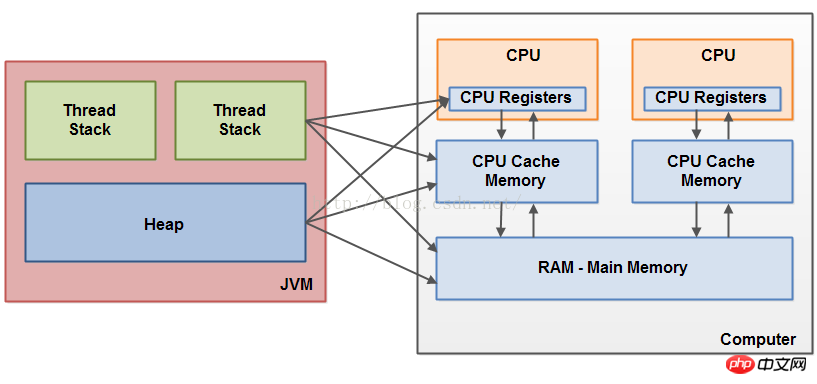
当对象和变量可以被存储在计算机中各种不同的内存区域的时候,某些问题可能会发生。主要的两个问题就是:
线程对于共享变量更新的可见性
当读取,检查,以及写共享变量的竞态条件
这些问题将会在下面的部分解释到。
共享对象的可见性
如果两个或者更多的线程共享一个对象,没有正确的使用volatile声明或者同步,被一个线程更新的共享变量可能对其它线程是不可见的。
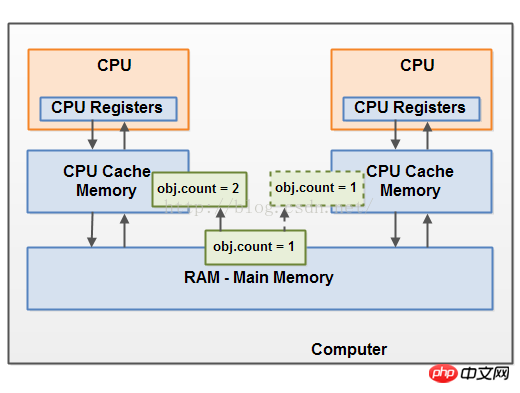
想象下共享对象初始存储在主内存中。运行在CPU上的一个线程读取这个共享对象进入它的CPU缓存中。这里它做了一个共享对象的一个改变。只要CPU缓存没有刷新到主内存,这个共享对象的改变版本对于运行在其他CPU上的线程是不可见的。这种方式每一个线程可能都是以他们自己的共享对象的拷贝而结束,每一个拷贝都位于不同的CPU缓存中。
下面的图表说明了示意图的情况。运行在左边CPU的一个线程拷贝这个共享变量进入CPU缓存,并且改变他的值为2。这个改变对于运行在右边的CPU的其他线程是不可见的,因为对于count的更新仍然还没有刷回主内存。
为了解决这个问题,你可以使用Java的volatile关键字。这个关键字可以确保一个给予的变量直接从主内存读取,并且当更新的时候直接写会到主内存。
竞态条件
如果两个或者更多的线程共享一个对象,并且不止一个线程更新这个共享对象中的变量,竞态条件可能会发生。
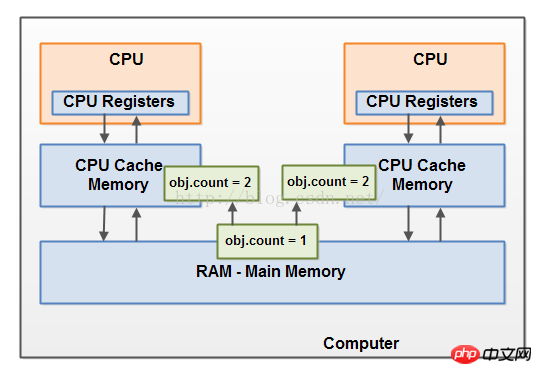
想象下如果线程A读取一个共享对象的count变量进入他的CPU缓存。同时,线程B做相同的事情,但是进入不同的CPU缓存。现在线程给count加一,并且线程B做同样的事情。现在这个变量增加了两次。
如果这些增量按顺序执行,这个count变量将会被增加两次并且在原始值的基础上加2写会到主内存。
然后,这两个增量没有正确的同步,导致并发的执行。不管线程A还是线程B写他们的更新到主内存中,这个更新的值只是加1,而不是加2。
这个图表显示了上面所描述的竞态条件的问题:
为了解决这个问题,你可以使用Java同步锁。一个同步锁可以保证在任何时间内只能一个线程进入代码的临界区域。同步锁也会保证所有的变量的访问都会从主内存中读取,并且当线程离开同步代码块的时候,所有更新的变量将会再次刷回主内存,不管这个变量是否声明为volatile。
以上就是Java内存模型的详细介绍的内容,更多相关内容请关注PHP中文网(www.php.cn)!

 Java平台独立性:OS之间的差异May 16, 2025 am 12:18 AM
Java平台独立性:OS之间的差异May 16, 2025 am 12:18 AMJava在不同操作系统上的表现存在细微差异。1)JVM实现不同,如HotSpot、OpenJDK,影响性能和垃圾回收。2)文件系统结构和路径分隔符不同,需使用Java标准库处理。3)网络协议实现差异影响网络性能。4)GUI组件外观和行为在不同系统上有别。通过使用标准库和虚拟机测试,可减少这些差异的影响,确保Java程序稳定运行。
 Java的最佳功能:从面向对象的编程到安全性May 16, 2025 am 12:15 AM
Java的最佳功能:从面向对象的编程到安全性May 16, 2025 am 12:15 AMjavaoffersrobustobject-IentiendedProgrammming(OOP)和Top-Notchsecurityfeatures.1)OopinjavainCludesClasses,对象,继承,多态性,和列出,andeclingfleximaintainablesys.ss.2)SecurityFeateTuersLudEtersludEterMachine(
 JavaScript与Java的最佳功能May 16, 2025 am 12:13 AM
JavaScript与Java的最佳功能May 16, 2025 am 12:13 AMJavaScriptandJavahavedistinctstrengths:JavaScriptexcelsindynamictypingandasynchronousprogramming,whileJavaisrobustwithstrongOOPandtyping.1)JavaScript'sdynamicnatureallowsforrapiddevelopmentandprototyping,withasync/awaitfornon-blockingI/O.2)Java'sOOPf
 Java平台独立性:收益,限制和实施May 16, 2025 am 12:12 AM
Java平台独立性:收益,限制和实施May 16, 2025 am 12:12 AMJAVAACHIEVESPLATFORMINDEPENTENCETHROUGHJAVAVIRTAILMACHINE(JVM)和BYTECODE.1)THEJVMINTERPRETSBBYTECODE,允许theingthesmecodetorunonanyanyanyanyplatformwithajvm.2)
 Java:真实词的平台独立性May 16, 2025 am 12:07 AM
Java:真实词的平台独立性May 16, 2025 am 12:07 AMJava'splatFormIndependecemeanSapplicationsCanrunonAnyPlatFormWithAjvm,使“ Writeonce,RunanyWhere”。
 JVM性能与其他语言May 14, 2025 am 12:16 AM
JVM性能与其他语言May 14, 2025 am 12:16 AMJVM'SperformanceIsCompetitiveWithOtherRuntimes,operingabalanceOfspeed,安全性和生产性。1)JVMUSESJITCOMPILATIONFORDYNAMICOPTIMIZAIZATIONS.2)c提供NativePernativePerformanceButlanceButlactsjvm'ssafetyFeatures.3)
 Java平台独立性:使用示例May 14, 2025 am 12:14 AM
Java平台独立性:使用示例May 14, 2025 am 12:14 AMJavaachievesPlatFormIndependencEthroughTheJavavIrtualMachine(JVM),允许CodeTorunonAnyPlatFormWithAjvm.1)codeisscompiledIntobytecode,notmachine-specificodificcode.2)bytecodeisisteredbytheybytheybytheybythejvm,enablingcross-platerssectectectectectross-eenablingcrossectectectectectection.2)
 JVM架构:深入研究Java虚拟机May 14, 2025 am 12:12 AM
JVM架构:深入研究Java虚拟机May 14, 2025 am 12:12 AMTheJVMisanabstractcomputingmachinecrucialforrunningJavaprogramsduetoitsplatform-independentarchitecture.Itincludes:1)ClassLoaderforloadingclasses,2)RuntimeDataAreafordatastorage,3)ExecutionEnginewithInterpreter,JITCompiler,andGarbageCollectorforbytec


热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

Video Face Swap
使用我们完全免费的人工智能换脸工具轻松在任何视频中换脸!

热门文章
热工具

ZendStudio 13.5.1 Mac
功能强大的PHP集成开发环境

SecLists
SecLists是最终安全测试人员的伙伴。它是一个包含各种类型列表的集合,这些列表在安全评估过程中经常使用,都在一个地方。SecLists通过方便地提供安全测试人员可能需要的所有列表,帮助提高安全测试的效率和生产力。列表类型包括用户名、密码、URL、模糊测试有效载荷、敏感数据模式、Web shell等等。测试人员只需将此存储库拉到新的测试机上,他就可以访问到所需的每种类型的列表。

Atom编辑器mac版下载
最流行的的开源编辑器

MinGW - 适用于 Windows 的极简 GNU
这个项目正在迁移到osdn.net/projects/mingw的过程中,你可以继续在那里关注我们。MinGW:GNU编译器集合(GCC)的本地Windows移植版本,可自由分发的导入库和用于构建本地Windows应用程序的头文件;包括对MSVC运行时的扩展,以支持C99功能。MinGW的所有软件都可以在64位Windows平台上运行。

螳螂BT
Mantis是一个易于部署的基于Web的缺陷跟踪工具,用于帮助产品缺陷跟踪。它需要PHP、MySQL和一个Web服务器。请查看我们的演示和托管服务。

