



1.XML编程
XML编程,就是对XML文件进行crud操作。
那么为什么要用java或者C/C++对XML进行crud操作呢?
1.XML作为数据传递需要解析
2.XML作为配置文件需要读取
3.XML作为小型数据库,需要进行crud操作
w3C组织为了大家解析XML方便,定义了一套规范(API)
1.1.XML解析技术介绍
1.XML解析分为:dom解析和sax解析
dom:(Document Object Model,即文档对象模型),是W3C组织推荐的处理XML的一种方式
sax:(Simple API for XML),不是官方标准,但它是XML社区事实上的标准,几乎所有的XML解析器都支持它
SAX解析采用事件驱动模型边读边解析:从上到下一行一行解析,解析到某一元素,调用相应的解析方法。
DOM根据XML层级结构在内存中分配一个树形结构,把XML的标签,属性和文本等元素都封装成树的节点对象。
不同的公司和组织提供了针对DOM和SAX两种方式的解析器:
Sun的JAXP
Dom4j组织的dom4j(最常用,例如hibernate)
JDom组织的jdom
其中的JASP是J2SE的一部分,它分别针对DOM和SAX提供了DOM和SAX解析器。
在这里也主要介绍三种解析:dom、sax和dom4j
1.2.JAXP介绍
Sun公司提供了Java API for XML Parsing(JAXP)接口来使用SAX和DOM,通过JAXP,我们可以使用任何与JAXP兼容的XML解析器。
JAXP开发包是J2SE的一部分,它由javax.xml、org.w3c.dom、org.xml.sax包及其子包组成
在javax.xml.parsers包中,定义了几个工厂类,程序员调用这些工厂类,可以得到对xml文档进行解析的DOM或SAX的解析器对象。
2.JAXP之DOM解析
2.1.XML DOM节点树
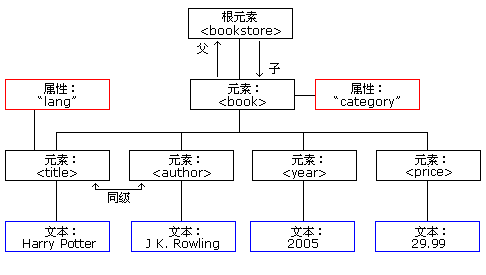
首先说明JAXP解析XML的DOM对象的原理,XML DOM把XML文档视为一颗节点树(node-tree),树中的所有节点彼此之间都有关系。可通过这棵树访问所有的节点。可以修改或者删除它们的内容,也可以创建新的元素。
比如,现在的XML文档如下(该例子来自w3cschool在线教程):
<bookstore>
<book category="children">
<title lang="en">Harry Potter</title>
<author>J K. Rowling</author>
<year>2005</year>
<price>29.99</price>
</book>
<book category="cooking">
<title lang="en">Everyday Italian</title>
<author>Giada De Laurentiis</author>
<year>2005</year>
<price>30.00</price>
</book>
<book category="web" cover="paperback">
<title lang="en">Learning XML</title>
<author>Erik T. Ray</author>
<year>2003</year>
<price>39.95</price>
</book>
<book category="web">
<title lang="en">XQuery Kick Start</title>
<author>James McGovern</author>
<author>Per Bothner</author>
<author>Kurt Cagle</author>
<author>James Linn</author>
<author>Vaidyanathan Nagarajan</author>
<year>2003</year>
<price>49.99</price>
</book></bookstore>这棵树从根节点开始,在树的最低层级向文本节点长出枝条:
【要知道的几个知识点】:
1.dom会把xml文件看做一棵树,并加载到内存
2.dom特别适合做crud操作
3.dom不太适合去操作比较大的xml文件(占用内存)
4.dom会把xml文件中每一个元素、属性、文本都映射成对应的Node对象。
2.2.获得JAXP中的DOM解析器步骤
1.调用DocumentBuilderFactory.newInstance()方法得到创建DOM解析器的工厂
2.调用工厂对象的newDocumentBuilder方法得到DOM解析器对象
3.调用DOM解析器对象的parse()方法解析XML文档,得到代表整个文档的Document对象,进行可以利用DOM特性对整个XML文档进行操作了。
2.3.JAXP之DOM解析实例:
XML文档如下:
<?xml version="1.0" encoding="utf-8"?><班级>
<学生 地址="香港">
<名字>周小星</名字>
<年龄>23</年龄>
<介绍>学习刻苦</介绍>
</学生>
<学生 地址="澳门">
<名字>林晓</名字>
<年龄>25</年龄>
<介绍>是一个好学生</介绍>
</学生> </班级>2.3.1.读取XML文档
首先使用2.2中介绍了三个步骤得到代表整个文档的document对象,并调用我们所写的read(Document document)方法,如下:
// 1.创建一个DocumentBuilderFactoryDocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
// 2.通过工厂实例得到DocumentBuilder对象DocumentBuilder builder = factory.newDocumentBuilder();
// 3.指定要解析的xml文件,返回document对象Document document = builder.parse(new File("src/myClass.xml"));
read(document);其中的read方法是这么写的:
/**
* 显示所有学生的所有信息
* @param document
*/public static void read(Document document){ // 通过学生这个标签名字得到NodeList
NodeList nodeList = document.getElementsByTagName("学生");
for(int i=0;i<nodeList.getLength();i++){ // 因为Element是Node的子接口,所有这里可以转换成Element
// 从而可以使用更多的方法
Element student = (Element)nodeList.item(i); // 获取属性
String address = student.getAttribute("地址");
System.out.println(address); // 得到学生的所有子节点,并循环输出
NodeList childList = student.getChildNodes(); for(int j=0;j<childList.getLength();j++){
Node node = childList.item(j); if(node.getNodeType() == Node.ELEMENT_NODE)
System.out.println(node.getNodeName()+":"+node.getTextContent());
}
System.out.println("-------------");
} // 这样一层一层向下查询也可以
//Element name = (Element)student.getElementsByTagName("名字").item(0);
//System.out.println(name.getTextContent()); }最后的运行结果如下所示:

2.3.2.更新XML文档
利用DOM更新XML文档一定要使用Transformer类将更改写入文件,否则只是更改了在内存中的XML文档对象。
javax.xml.transform包中的Transformer类用于把代表XML文件的Document对象转换为某种格式后进行输出,例如把xml文件应用样式表后转成一个html文档。利用这个对象,当然也可以把Document对象又重新写回到一个XML文件中
Transformer类通过transform方法完成转换操作,该方法接收一个源和一个目的地。我们可以通过:
javax.xml.transform.dom.DOMSource类来关联要转换的document对象
用javax.xml.transform.stream.StreamResult对象来表示数据的目的地
Transformer对象通过TransformerFactory获得
【1】添加元素
我们可以向上述XML中添加一个学生子节点,如下:
/**
* 添加学生
*
* @param document
* @throws Exception
*/public static void add(Document document) throws Exception { // 创建一个新的学生节点
Element newStudent = document.createElement("学生"); // 给新的学生添加地址属性
newStudent.setAttribute("地址", "旧金山"); // 创建学生的子节点
Element newStudent_name = document.createElement("名字");
newStudent_name.setTextContent("小明");
Element newStudent_age = document.createElement("年龄");
newStudent_age.setTextContent("25");
Element newStudent_intro = document.createElement("介绍");
newStudent_intro.setTextContent("这是一个好孩子"); // 将子节点添加到学生节点上
newStudent.appendChild(newStudent_name);
newStudent.appendChild(newStudent_age);
newStudent.appendChild(newStudent_intro); // 把新的学生节点添加到根节点下
document.getDocumentElement().appendChild(newStudent); // 更新XML文档
// 得到TransformerFactory
TransformerFactory tff = TransformerFactory.newInstance(); // 通过TransformerFactory得到一个转换器
Transformer tf = tff.newTransformer(); // 更新当前的XML文件
tf.transform(new DOMSource(document), new StreamResult(new File( "src/myClass.xml")));
}【2】删除元素
同样的,我们也可以删除一个学生节点,如下:
/**
* 删除第一个学生节点
*
* @param document
*/public static void delete(Document document) throws Exception { // 首先找到这个学生,这里可以不用转为Element
Node student = document.getElementsByTagName("学生").item(0); // 通过它的父节点来删除
student.getParentNode().removeChild(student); // 更新这个文档
TransformerFactory tff = TransformerFactory.newInstance();
Transformer tf = tff.newTransformer();
tf.transform(new DOMSource(document), new StreamResult(new File( "src/myClass.xml")));
}【3】更改元素的值
比如,我们也可以将第一个学生的名字改为松江,如下:
/**
* 把第一个学生的元素名字改为宋江
*
* @param document
*/public static void update_name(Document document) throws Exception{
Element student = (Element) document.getElementsByTagName("学生").item(0);
Element name = (Element) student.getElementsByTagName("名字").item(0);
name.setTextContent("宋江"); // 更新这个文档
TransformerFactory tff = TransformerFactory.newInstance();
Transformer tf = tff.newTransformer();
tf.transform(new DOMSource(document), new StreamResult(new File( "src/myClass.xml")));
}【4】更改或删除元素的属性
/**
* 删除第一个学生节点的属性
*
* @param document
*/public static void delete_attribute(Document document) throws Exception { // 首先找到这个学生
Element student = (Element) document.getElementsByTagName("学生").item(0); // 删除student的地址属性
student.removeAttribute("地址"); // 更新属性
// student.setAttribute("地址", "新地址");
// 更新这个文档
TransformerFactory tff = TransformerFactory.newInstance();
Transformer tf = tff.newTransformer();
tf.transform(new DOMSource(document), new StreamResult(new File( "src/myClass.xml")));
}上述列举了几个更新元素(节点)的例子,更一般的需求是这样的:将名字是周小星的同学的年龄改为30,这时候我们需要去遍历XML文档,找到对应的节点,再进行修改。
另外,所有关于更新的方法中都用到了TransformerFactory来进行实际的更新,所以,我们可以把这三句话写成一个函数,从而避免代码冗余,如下:
public static void update(Document document, String path) throws Exception {
TransformerFactory tff = TransformerFactory.newInstance();
Transformer tf = tff.newTransformer();
tf.transform(new DOMSource(document), new StreamResult(new File(path)));
}1.XML编程
XML编程,就是对XML文件进行crud操作。
那么为什么要用java或者C/C++对XML进行crud操作呢?
1.XML作为数据传递需要解析
2.XML作为配置文件需要读取
3.XML作为小型数据库,需要进行crud操作
w3C组织为了大家解析XML方便,定义了一套规范(API)
1.1.XML解析技术介绍
1.XML解析分为:dom解析和sax解析
dom:(Document Object Model,即文档对象模型),是W3C组织推荐的处理XML的一种方式
sax:(Simple API for XML),不是官方标准,但它是XML社区事实上的标准,几乎所有的XML解析器都支持它
SAX解析采用事件驱动模型边读边解析:从上到下一行一行解析,解析到某一元素,调用相应的解析方法。
DOM根据XML层级结构在内存中分配一个树形结构,把XML的标签,属性和文本等元素都封装成树的节点对象。
不同的公司和组织提供了针对DOM和SAX两种方式的解析器:
Sun的JAXP
Dom4j组织的dom4j(最常用,例如hibernate)
JDom组织的jdom
其中的JASP是J2SE的一部分,它分别针对DOM和SAX提供了DOM和SAX解析器。
在这里也主要介绍三种解析:dom、sax和dom4j
1.2.JAXP介绍
Sun公司提供了Java API for XML Parsing(JAXP)接口来使用SAX和DOM,通过JAXP,我们可以使用任何与JAXP兼容的XML解析器。
JAXP开发包是J2SE的一部分,它由javax.xml、org.w3c.dom、org.xml.sax包及其子包组成
在javax.xml.parsers包中,定义了几个工厂类,程序员调用这些工厂类,可以得到对xml文档进行解析的DOM或SAX的解析器对象。
2.JAXP之DOM解析
2.1.XML DOM节点树
首先说明JAXP解析XML的DOM对象的原理,XML DOM把XML文档视为一颗节点树(node-tree),树中的所有节点彼此之间都有关系。可通过这棵树访问所有的节点。可以修改或者删除它们的内容,也可以创建新的元素。
比如,现在的XML文档如下(该例子来自w3cschool在线教程):
<bookstore>
<book category="children">
<title lang="en">Harry Potter</title>
<author>J K. Rowling</author>
<year>2005</year>
<price>29.99</price>
</book>
<book category="cooking">
<title lang="en">Everyday Italian</title>
<author>Giada De Laurentiis</author>
<year>2005</year>
<price>30.00</price>
</book>
<book category="web" cover="paperback">
<title lang="en">Learning XML</title>
<author>Erik T. Ray</author>
<year>2003</year>
<price>39.95</price>
</book>
<book category="web">
<title lang="en">XQuery Kick Start</title>
<author>James McGovern</author>
<author>Per Bothner</author>
<author>Kurt Cagle</author>
<author>James Linn</author>
<author>Vaidyanathan Nagarajan</author>
<year>2003</year>
<price>49.99</price>
</book></bookstore>这棵树从根节点开始,在树的最低层级向文本节点长出枝条:
【要知道的几个知识点】:
1.dom会把xml文件看做一棵树,并加载到内存
2.dom特别适合做crud操作
3.dom不太适合去操作比较大的xml文件(占用内存)
4.dom会把xml文件中每一个元素、属性、文本都映射成对应的Node对象。
2.2.获得JAXP中的DOM解析器步骤
1.调用DocumentBuilderFactory.newInstance()方法得到创建DOM解析器的工厂
2.调用工厂对象的newDocumentBuilder方法得到DOM解析器对象
3.调用DOM解析器对象的parse()方法解析XML文档,得到代表整个文档的Document对象,进行可以利用DOM特性对整个XML文档进行操作了。
2.3.JAXP之DOM解析实例:
XML文档如下:
<?xml version="1.0" encoding="utf-8"?><班级>
<学生 地址="香港">
<名字>周小星</名字>
<年龄>23</年龄>
<介绍>学习刻苦</介绍>
</学生>
<学生 地址="澳门">
<名字>林晓</名字>
<年龄>25</年龄>
<介绍>是一个好学生</介绍>
</学生> </班级>2.3.1.读取XML文档
首先使用2.2中介绍了三个步骤得到代表整个文档的document对象,并调用我们所写的read(Document document)方法,如下:
// 1.创建一个DocumentBuilderFactoryDocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
// 2.通过工厂实例得到DocumentBuilder对象DocumentBuilder builder = factory.newDocumentBuilder();
// 3.指定要解析的xml文件,返回document对象Document document = builder.parse(new File("src/myClass.xml"));
read(document);其中的read方法是这么写的:
/**
* 显示所有学生的所有信息
* @param document
*/public static void read(Document document){ // 通过学生这个标签名字得到NodeList
NodeList nodeList = document.getElementsByTagName("学生");
for(int i=0;i<nodeList.getLength();i++){ // 因为Element是Node的子接口,所有这里可以转换成Element
// 从而可以使用更多的方法
Element student = (Element)nodeList.item(i); // 获取属性
String address = student.getAttribute("地址");
System.out.println(address); // 得到学生的所有子节点,并循环输出
NodeList childList = student.getChildNodes(); for(int j=0;j<childList.getLength();j++){
Node node = childList.item(j); if(node.getNodeType() == Node.ELEMENT_NODE)
System.out.println(node.getNodeName()+":"+node.getTextContent());
}
System.out.println("-------------");
} // 这样一层一层向下查询也可以
//Element name = (Element)student.getElementsByTagName("名字").item(0);
//System.out.println(name.getTextContent()); }最后的运行结果如下所示:
2.3.2.更新XML文档
利用DOM更新XML文档一定要使用Transformer类将更改写入文件,否则只是更改了在内存中的XML文档对象。
javax.xml.transform包中的Transformer类用于把代表XML文件的Document对象转换为某种格式后进行输出,例如把xml文件应用样式表后转成一个html文档。利用这个对象,当然也可以把Document对象又重新写回到一个XML文件中
Transformer类通过transform方法完成转换操作,该方法接收一个源和一个目的地。我们可以通过:
javax.xml.transform.dom.DOMSource类来关联要转换的document对象
用javax.xml.transform.stream.StreamResult对象来表示数据的目的地
Transformer对象通过TransformerFactory获得
【1】添加元素
我们可以向上述XML中添加一个学生子节点,如下:
/**
* 添加学生
*
* @param document
* @throws Exception
*/public static void add(Document document) throws Exception { // 创建一个新的学生节点
Element newStudent = document.createElement("学生"); // 给新的学生添加地址属性
newStudent.setAttribute("地址", "旧金山"); // 创建学生的子节点
Element newStudent_name = document.createElement("名字");
newStudent_name.setTextContent("小明");
Element newStudent_age = document.createElement("年龄");
newStudent_age.setTextContent("25");
Element newStudent_intro = document.createElement("介绍");
newStudent_intro.setTextContent("这是一个好孩子"); // 将子节点添加到学生节点上
newStudent.appendChild(newStudent_name);
newStudent.appendChild(newStudent_age);
newStudent.appendChild(newStudent_intro); // 把新的学生节点添加到根节点下
document.getDocumentElement().appendChild(newStudent); // 更新XML文档
// 得到TransformerFactory
TransformerFactory tff = TransformerFactory.newInstance(); // 通过TransformerFactory得到一个转换器
Transformer tf = tff.newTransformer(); // 更新当前的XML文件
tf.transform(new DOMSource(document), new StreamResult(new File( "src/myClass.xml")));
}【2】删除元素
同样的,我们也可以删除一个学生节点,如下:
/**
* 删除第一个学生节点
*
* @param document
*/public static void delete(Document document) throws Exception { // 首先找到这个学生,这里可以不用转为Element
Node student = document.getElementsByTagName("学生").item(0); // 通过它的父节点来删除
student.getParentNode().removeChild(student); // 更新这个文档
TransformerFactory tff = TransformerFactory.newInstance();
Transformer tf = tff.newTransformer();
tf.transform(new DOMSource(document), new StreamResult(new File( "src/myClass.xml")));
}【3】更改元素的值
比如,我们也可以将第一个学生的名字改为松江,如下:
/**
* 把第一个学生的元素名字改为宋江
*
* @param document
*/public static void update_name(Document document) throws Exception{
Element student = (Element) document.getElementsByTagName("学生").item(0);
Element name = (Element) student.getElementsByTagName("名字").item(0);
name.setTextContent("宋江"); // 更新这个文档
TransformerFactory tff = TransformerFactory.newInstance();
Transformer tf = tff.newTransformer();
tf.transform(new DOMSource(document), new StreamResult(new File( "src/myClass.xml")));
}【4】更改或删除元素的属性
/**
* 删除第一个学生节点的属性
*
* @param document
*/public static void delete_attribute(Document document) throws Exception { // 首先找到这个学生
Element student = (Element) document.getElementsByTagName("学生").item(0); // 删除student的地址属性
student.removeAttribute("地址"); // 更新属性
// student.setAttribute("地址", "新地址");
// 更新这个文档
TransformerFactory tff = TransformerFactory.newInstance();
Transformer tf = tff.newTransformer();
tf.transform(new DOMSource(document), new StreamResult(new File( "src/myClass.xml")));
}上述列举了几个更新元素(节点)的例子,更一般的需求是这样的:将名字是周小星的同学的年龄改为30,这时候我们需要去遍历XML文档,找到对应的节点,再进行修改。
另外,所有关于更新的方法中都用到了TransformerFactory来进行实际的更新,所以,我们可以把这三句话写成一个函数,从而避免代码冗余,如下:
public static void update(Document document, String path) throws Exception {
TransformerFactory tff = TransformerFactory.newInstance();
Transformer tf = tff.newTransformer();
tf.transform(new DOMSource(document), new StreamResult(new File(path)));
} 以上就是XML—XML解析之DOM的内容,更多相关内容请关注PHP中文网(www.php.cn)!

 RSS文档格式:探索RSS 2.0及以后Apr 26, 2025 am 12:22 AM
RSS文档格式:探索RSS 2.0及以后Apr 26, 2025 am 12:22 AMRSS2.0是一种开放标准,允许内容发布者以结构化的方式分发内容。它包含了丰富的元数据,如标题、链接、描述、发布日期等,使得订阅者能够快速浏览和访问内容。RSS2.0的优势在于其简洁和扩展性。例如,它允许自定义元素,这意味着开发者可以根据需求添加额外的信息,如作者、分类等。
 理解RSS:XML观点Apr 25, 2025 am 12:14 AM
理解RSS:XML观点Apr 25, 2025 am 12:14 AMRSS是一种基于XML的格式,用于发布经常更新的内容。1.RSSfeed通过XML结构化组织信息,包括标题、链接、描述等。2.创建RSSfeed需按照XML结构编写,添加元数据如语言和发布日期。3.高级用法可包含多媒体文件和分类信息。4.调试时使用XML验证工具,确保必需元素存在且编码正确。5.优化RSSfeed可通过分页、缓存和保持结构简洁来实现。通过理解和应用这些知识,可以有效管理和分发内容。
 XML中的RSS:解码标签,属性和结构Apr 24, 2025 am 12:09 AM
XML中的RSS:解码标签,属性和结构Apr 24, 2025 am 12:09 AMRSS是一种基于XML的格式,用于发布和订阅内容。RSS文件的XML结构包括根元素、元素和多个元素,每个代表一个内容条目。通过XML解析器读取和解析RSS文件,用户可以订阅并获取最新内容。
 XML在RSS中的优势:技术深度潜水Apr 23, 2025 am 12:02 AM
XML在RSS中的优势:技术深度潜水Apr 23, 2025 am 12:02 AMXML在RSS中具有结构化数据、可扩展性、跨平台兼容性和解析验证的优势。1)结构化数据确保内容的一致性和可靠性;2)可扩展性允许添加自定义标签以适应内容需求;3)跨平台兼容性使其在不同设备上无缝工作;4)解析和验证工具确保Feed的质量和完整性。
 XML中的RSS:揭示内容联合的核心Apr 22, 2025 am 12:08 AM
XML中的RSS:揭示内容联合的核心Apr 22, 2025 am 12:08 AMRSS在XML中的实现方式是通过结构化的XML格式来组织内容。1)RSS使用XML作为数据交换格式,包含频道信息和项目列表等元素。2)生成RSS文件需按规范组织内容,发布到服务器供订阅。3)RSS文件可通过阅读器或插件订阅,实现内容自动更新。
 超越基础:高级RSS文档功能Apr 21, 2025 am 12:03 AM
超越基础:高级RSS文档功能Apr 21, 2025 am 12:03 AMRSS的高级功能包括内容命名空间、扩展模块和条件订阅。1)内容命名空间扩展RSS功能,2)扩展模块如DublinCore或iTunes添加元数据,3)条件订阅根据特定条件筛选条目。这些功能通过添加XML元素和属性实现,提升信息获取效率。
 XML主链:RSS提要如何结构Apr 20, 2025 am 12:02 AM
XML主链:RSS提要如何结构Apr 20, 2025 am 12:02 AMrssfeedsusexmltoStructureContentUpdates.1)xmlProvidesHierarchicalStructurefordata.2)theelementDefinestHefEed'sIdentityAndContainsElements.3)ElementsRementsRementsRepresSentividividividualContentpieces.4)rsssissisexisextensible,允许custemements.5)5)
 RSS和XML:了解Web内容的动态二重奏Apr 19, 2025 am 12:03 AM
RSS和XML:了解Web内容的动态二重奏Apr 19, 2025 am 12:03 AMRSS和XML是用于网络内容管理的工具。RSS用于发布和订阅内容,XML用于存储和传输数据。它们的工作原理包括内容发布、订阅和更新推送。使用示例包括RSS发布博客文章和XML存储书籍信息。


热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

Video Face Swap
使用我们完全免费的人工智能换脸工具轻松在任何视频中换脸!

热门文章
热工具

安全考试浏览器
Safe Exam Browser是一个安全的浏览器环境,用于安全地进行在线考试。该软件将任何计算机变成一个安全的工作站。它控制对任何实用工具的访问,并防止学生使用未经授权的资源。

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)

DVWA
Damn Vulnerable Web App (DVWA) 是一个PHP/MySQL的Web应用程序,非常容易受到攻击。它的主要目标是成为安全专业人员在合法环境中测试自己的技能和工具的辅助工具,帮助Web开发人员更好地理解保护Web应用程序的过程,并帮助教师/学生在课堂环境中教授/学习Web应用程序安全。DVWA的目标是通过简单直接的界面练习一些最常见的Web漏洞,难度各不相同。请注意,该软件中

EditPlus 中文破解版
体积小,语法高亮,不支持代码提示功能

VSCode Windows 64位 下载
微软推出的免费、功能强大的一款IDE编辑器

