



mixer 结构分析[uavcan为例]
mixer指令为系统的app命令,位置在Firmware/src/systemcmds/mixer目录下面,其功能是装载mix文件中的有效内容到具体的设备中,然后由具体的设备中的MixerGroups来解析这些定义.本例是以uvacan为例, 系统运行后,设备的名称为:/dev/uavcan/esc.
uavcan的定义中有MixerGroup实例,Output实例.
MIXER的种类一共有三个:NullMixer, SimpleMixer 和MultirotorMixer.
NullMixer:用来为未分组的输出通道点位;
SimpleMixer:0或多个输入融合成一个输出;
MultirotorMixer:将输入量(ROLL,PITCH,RAW,Thrusttle)融合成一组基于 预先定义的geometry的输出量.


读取mix文件的函数位于Firmware/src/modules/systemlib/mixwr/mixer_load.c中的函数:
<ol style="margin:0 1px 0 0px;padding-left:40px;" start="1" class="dp-css"><li>int load_mixer_file(const char *fname, char *buf, unsigned maxlen) </li></ol>参数fname为mix文件在系统中的位置,buf为读取文件数据存放的缓冲区,maxlen为buf的最大长度。
该函数会剔除符合下面任何一条的行:
1.行长度小于2个字符的行
2.行的首字符不是大写字母的行
3.第二个字符不是':'的行
剔除这些非法内容的数据后,剩余的全部为格式化的内容,会被全部存入buf缓冲区中。
所以这要求在写mix文件时要遵循mix和格式。
这些格式化的mix内容被读取缓冲区后,就会通过函数
<ol style="margin:0 1px 0 0px;padding-left:40px;" start="1" class="dp-css"><li>int ret = ioctl(dev, MIXERIOCLOADBUF, (unsigned long)buf); </li></ol>来交给具体的设备处理。
相关结构的定义:
<ol style="margin:0 1px 0 0px;padding-left:40px;" start="1" class="dp-css"><li>/** simple channel scaler */<br /> </li><li>struct mixer_scaler_s {<br /></li><li>floatnegative_scale;//负向缩放, MIX文件中 O: 后面的第1个整数/10000.0f<br /></li><li>floatpositive_scale;//正向缩放, MIX文件中 O: 后面的第2个整数/10000.0f<br /></li><li>floatoffset; //偏移 , MIX文件中 O: 后面的第3个整数/10000.0f<br /></li><li>floatmin_output;//最小输出值 , MIX文件中 O: 后面的第4个整数/10000.0f<br /></li><li>floatmax_output;//最大输出值 , MIX文件中 O: 后面的第5个整数/10000.0f<br /></li><li>};//该结构定义了单个控制量的结构<br /></li><li><br /></li><li>/** mixer input */<br /></li><li>struct mixer_control_s {<br /></li><li>uint8_tcontrol_group;/**< group from which the input reads */<br /></li><li>uint8_tcontrol_index;/**< index within the control group */<br /></li><li>struct mixer_scaler_s scaler;/**< scaling applied to the input before use */<br /></li><li>};//定义输入量的结构<br /></li><li><br /></li><li>/** simple mixer */<br /></li><li>struct mixer_simple_s {<br /></li><li>uint8_tcontrol_count;/**< number of inputs */<br /></li><li>struct mixer_scaler_soutput_scaler;/**< scaling for the output */<br /></li><li>struct mixer_control_scontrols[0];/**< actual size of the array is set by control_count */<br /></li><li>};//定义了一个控制实体的控制体,包括输入的信号数量,输入信号控制集,输出信号控制。 </li><li>//因为一个mixer只有一个输出,可以有0到多个输入,所以control_count指明了这个mixer所需要的输入信号数量,而具体的信号都存放在数组controls[0]中。 </li><li>//输出则由output_scaler来控制. </li><li>//从这些结构体的定义,可以对照起来mix文件语法的定义.<br /> </li></ol>uavcan_main.cpp:
该文件中有解析上面提到的缓冲数据
- int UavcanNode::ioctl(file *filp, int cmd, unsigned long arg)
- {
- ...
- case MIXERIOCLOADBUF: {
const char *buf = (const char *)arg;
unsigned buflen = strnlen(buf, 1024);
if (_mixers == nullptr) {
_mixers = new MixerGroup(control_callback, (uintptr_t)_controls);
}
if (_mixers == nullptr) {
_groups_required = 0;
ret = -ENOMEM;
} else {
ret = _mixers->load_from_buf(buf, buflen);//这里开始解析数据
if (ret != 0) {
warnx("mixer load failed with %d", ret);
delete _mixers;
_mixers = nullptr;
_groups_required = 0;
ret = -EINVAL;
} else {
_mixers->groups_required(_groups_required);
}
}
break;
}
...
- }
<ol style="margin:0 1px 0 0px;padding-left:40px;" start="1" class="dp-css"><li>int MixerGroup::load_from_buf(const char *buf, unsigned &buflen)<br /></li><li>{<br /></li><li>int ret = -1;<br /></li><li>const char *end = buf + buflen;<br /></li><li><br /></li><li>/*<br /></li><li> * Loop until either we have emptied the buffer, or we have failed to<br /></li><li> * allocate something when we expected to.<br /></li><li> */<br /></li><li>while (buflen > 0) {<br /></li><li>Mixer *m = nullptr;<br /></li><li>const char *p = end - buflen;<br /></li><li>unsigned resid = buflen;<br /></li><li><br /></li><li>/*<br /></li><li> * Use the next character as a hint to decide which mixer class to construct.<br /></li><li> */<br /></li><li>switch (*p) {//首先看该行的第一个字母,来确定数据的类别.<br /></li><li>case 'Z':<br /></li><li>m = NullMixer::from_text(p, resid);<br /></li><li>break;<br /></li><li><br /></li><li>case 'M':<br /></li><li>m = SimpleMixer::from_text(_control_cb, _cb_handle, p, resid);<br /></li><li>break;<br /></li><li><br /></li><li>case 'R':<br /></li><li>m = MultirotorMixer::from_text(_control_cb, _cb_handle, p, resid);<br /></li><li>break;<br /></li><li><br /></li><li>default:<br /></li><li>/* it's probably junk or whitespace, skip a byte and retry */<br /></li><li>buflen--;<br /></li><li>continue;<br /></li><li>}<br /></li><li><br /></li><li>/*<br /></li><li> * If we constructed something, add it to the group.<br /></li><li> */<br /></li><li>if (m != nullptr) {<br /></li><li>add_mixer(m);<br /></li><li><br /></li><li>/* we constructed something */<br /></li><li>ret = 0;<br /></li><li><br /></li><li>/* only adjust buflen if parsing was successful */<br /></li><li>buflen = resid;<br /></li><li>debug("SUCCESS - buflen: %d", buflen);<br /></li><li><br /></li><li>} else {<br /></li><li><br /></li><li>/*<br /></li><li> * There is data in the buffer that we expected to parse, but it didn't,<br /></li><li> * so give up for now.<br /></li><li> */<br /></li><li>break;<br /></li><li>}<br /></li><li>}<br /></li><li><br /></li><li>/* nothing more in the buffer for us now */<br /></li><li>return ret;<br /></li><li>} </li></ol>下面这个函数用来 处理 M: 开头的定义, 格式规定该字符后面只能有一个数字,用来指明input信号源的数量,即S类型数量的数量,联系到结构体的定义,则为 struct mixer_control_s 的数量.
<ol style="margin:0 1px 0 0px;padding-left:40px;" start="1" class="dp-css"><li>SimpleMixer *<br /> </li><li>SimpleMixer::from_text(Mixer::ControlCallback control_cb, uintptr_t cb_handle, const char *buf, unsigned &buflen)<br /></li><li>{<br /></li><li>SimpleMixer *sm = nullptr;<br /></li><li>mixer_simple_s *mixinfo = nullptr;<br /></li><li>unsigned inputs;<br /></li><li>int used;<br /></li><li>const char *end = buf + buflen;<br /></li><li><br /></li><li>/* get the base info for the mixer */<br /></li><li>if (sscanf(buf, "M: %u%n", &inputs, &used) != 1) {<br /></li><li>debug("simple parse failed on '%s'", buf);<br /></li><li>goto out;<br /></li><li>}//复制M:后面第一个数值到无符号整型数据到变量inputs中,并将已经处理的字条数目赋值给used<br /></li><li><br /></li><li>buf = skipline(buf, buflen);//让buf指定下一行<br /></li><li><br /></li><li>if (buf == nullptr) {<br /></li><li>debug("no line ending, line is incomplete");<br /></li><li>goto out;<br /></li><li>}<br /></li><li><br /></li><li>mixinfo = (mixer_simple_s *)malloc(MIXER_SIMPLE_SIZE(inputs)); </li><li> //M:后面的数字为struct mixer_control_s 结构的数量.MIXER_SIMPLE_SIZE的字义为sizeof(mixer_simple_s) + inputs*sizeof(mixer_control_s), </li><li> //即一个完整的mixer_simple_s的定义,controls[0]一共有inputs个.<br /> </li><li><br /></li><li>if (mixinfo == nullptr) {<br /></li><li>debug("could not allocate memory for mixer info");<br /></li><li>goto out;<br /></li><li>}<br /></li><li><br /></li><li>mixinfo->control_count = inputs;//input 信号的数量<br /></li><li><br /></li><li>if (parse_output_scaler(end - buflen, buflen, mixinfo->output_scaler)) {<br /></li><li>debug("simple mixer parser failed parsing out scaler tag, ret: '%s'", buf);<br /></li><li>goto out;<br /></li><li>}//该函数解析输出域,并将期填充到mixinfo的output_scaler字段中.<br /><p></p><pre class="code"><ol style="margin:0 1px 0 0px;padding-left:40px;" start="1" class="dp-css"><li>int SimpleMixer::parse_output_scaler(const char *buf, unsigned &buflen, mixer_scaler_s &scaler)<br /></li><li>{<br /></li><li>int ret;<br /></li><li>int s[5];<br /></li><li>int n = -1;<br /></li><li><br /></li><li>buf = findtag(buf, buflen, 'O');//寻找"O:"这样的控制符,返回指针指向输出格式域定义的首字符'O'.<br /></li></ol><ol style="margin:0 1px 0 0px;padding-left:40px;" start="1" class="dp-css"><li>if ((buf == nullptr) || (buflen < 12)) {<br /></li><li>debug("output parser failed finding tag, ret: '%s'", buf);<br /></li><li>return -1;<br /></li><li>}//12,表示O:这行的定义至少有12个字符(O:和五个1位长的整数),例如最短的定义为: O: 0 0 0 0 0<br /></li><li><br /></li><li>if ((ret = sscanf(buf, "O: %d %d %d %d %d %n",//O:后面必须有5个整数,且整数间用至少一个空格分开,此处是取出O:后面的5个整数值.<br /></li><li> &s[0], &s[1], &s[2], &s[3], &s[4], &n)) != 5) {<br /></li><li>debug("out scaler parse failed on '%s' (got %d, consumed %d)", buf, ret, n);<br /></li><li>return -1;<br /></li><li>}<br /></li><li><br /></li><li>buf = skipline(buf, buflen);<br /></li><li><br /></li><li>if (buf == nullptr) {<br /></li><li>debug("no line ending, line is incomplete");<br /></li><li>return -1;<br /></li><li>}<br /></li><li> //从下面的赋值操作可以得出 O:后面5个数值的字义.,分别为 [negative_scale] [positive_scale] [offset] [min_output] [max_output] </li><li> //并且每个这都做了除10000的操作,所以MIX格式定义中说这些值都是被放大10000倍后的数值.<br /> </li><li>scaler.negative_scale= s[0] / 10000.0f;<br /></li><li>scaler.positive_scale= s[1] / 10000.0f;<br /></li><li>scaler.offset= s[2] / 10000.0f;<br /></li><li>scaler.min_output= s[3] / 10000.0f;<br /></li><li>scaler.max_output= s[4] / 10000.0f;<br /></li><li><br /></li><li>return 0;<br /></li><li>} </li></ol>//上面解析了MIXER的输出量,下面开始解析输入量,因为我们已经读取了输入信号的数量("M: n"中n定义的数值),所以要循环n次.
<ol style="margin:0 1px 0 0px;padding-left:40px;" start="1" class="dp-css"><li>int SimpleMixer::parse_control_scaler(const char *buf, unsigned &buflen, mixer_scaler_s &scaler, uint8_t &control_group,<br /></li><li> uint8_t &control_index)<br /></li><li>{<br /></li><li>unsigned u[2];<br /></li><li>int s[5];<br /></li><li><br /></li><li>buf = findtag(buf, buflen, 'S');//找到剩余缓冲区中的第一个'S',并让buf指向该行的行首; </li><li> //<br /> </li><li> //16表示该S:行至少有16个字符,即至少有7个整数(因为整数间至少有1个空格分隔)<br /></li><li>if ((buf == nullptr) || (buflen < 16)) {<br /></li><li>debug("control parser failed finding tag, ret: '%s'", buf);<br /></li><li>return -1;<br /></li><li>}<br /></li><li> //读取S:后面的7个整数.<br /></li><li>if (sscanf(buf, "S: %u %u %d %d %d %d %d",<br /></li><li> &u[0], &u[1], &s[0], &s[1], &s[2], &s[3], &s[4]) != 7) {<br /></li><li>debug("control parse failed on '%s'", buf);<br /></li><li>return -1;<br /></li><li>}<br /></li><li><br /></li><li>buf = skipline(buf, buflen);<br /></li><li><br /></li><li>if (buf == nullptr) {<br /></li><li>debug("no line ending, line is incomplete");<br /></li><li>return -1;<br /></li><li>} </li><li><br /> </li><li> //从下面的赋值可以看出MIXER文件S:定义的格式,S:后面的整数分别为 </li><li> // [control_group] [ontrol_index] [negative_scale] [positive_scale] [offset] [min_output] [max_output]<br /> </li><li> // 可以看出,输入信号的定义比输入出信号的定义多了两个整数,用来表示当前输入信号所在的组和组内的序号. 第1和第2个整就是用来 </li><li> // 说明组号和组内序号.而后面5个整数的定义和输入信号的定义一样,且也要除以10000.<br /> </li><li>control_group= u[0];<br /></li><li>control_index= u[1];<br /></li><li>scaler.negative_scale= s[0] / 10000.0f;<br /></li><li>scaler.positive_scale= s[1] / 10000.0f;<br /></li><li>scaler.offset= s[2] / 10000.0f;<br /></li><li>scaler.min_output= s[3] / 10000.0f;<br /></li><li>scaler.max_output= s[4] / 10000.0f;<br /></li><li><br /></li><li>return 0;<br /></li><li>} </li></ol>
 如何在 iPhone 和 Android 上关闭蓝色警报Feb 29, 2024 pm 10:10 PM
如何在 iPhone 和 Android 上关闭蓝色警报Feb 29, 2024 pm 10:10 PM根据美国司法部的解释,蓝色警报旨在提供关于可能对执法人员构成直接和紧急威胁的个人的重要信息。这种警报的目的是及时通知公众,并让他们了解与这些罪犯相关的潜在危险。通过这种主动的方式,蓝色警报有助于增强社区的安全意识,促使人们采取必要的预防措施以保护自己和周围的人。这种警报系统的建立旨在提高对潜在威胁的警觉性,并加强执法机构与公众之间的沟通,以共尽管这些紧急通知对我们社会至关重要,但有时可能会对日常生活造成干扰,尤其是在午夜或重要活动时收到通知时。为了确保安全,我们建议您保持这些通知功能开启,但如果
 在Android中实现轮询的方法是什么?Sep 21, 2023 pm 08:33 PM
在Android中实现轮询的方法是什么?Sep 21, 2023 pm 08:33 PMAndroid中的轮询是一项关键技术,它允许应用程序定期从服务器或数据源检索和更新信息。通过实施轮询,开发人员可以确保实时数据同步并向用户提供最新的内容。它涉及定期向服务器或数据源发送请求并获取最新信息。Android提供了定时器、线程、后台服务等多种机制来高效地完成轮询。这使开发人员能够设计与远程数据源保持同步的响应式动态应用程序。本文探讨了如何在Android中实现轮询。它涵盖了实现此功能所涉及的关键注意事项和步骤。轮询定期检查更新并从服务器或源检索数据的过程在Android中称为轮询。通过
 如何在Android中实现按下返回键再次退出的功能?Aug 30, 2023 am 08:05 AM
如何在Android中实现按下返回键再次退出的功能?Aug 30, 2023 am 08:05 AM为了提升用户体验并防止数据或进度丢失,Android应用程序开发者必须避免意外退出。他们可以通过加入“再次按返回退出”功能来实现这一点,该功能要求用户在特定时间内连续按两次返回按钮才能退出应用程序。这种实现显著提升了用户参与度和满意度,确保他们不会意外丢失任何重要信息Thisguideexaminesthepracticalstepstoadd"PressBackAgaintoExit"capabilityinAndroid.Itpresentsasystematicguid
 Android逆向中smali复杂类实例分析May 12, 2023 pm 04:22 PM
Android逆向中smali复杂类实例分析May 12, 2023 pm 04:22 PM1.java复杂类如果有什么地方不懂,请看:JAVA总纲或者构造方法这里贴代码,很简单没有难度。2.smali代码我们要把java代码转为smali代码,可以参考java转smali我们还是分模块来看。2.1第一个模块——信息模块这个模块就是基本信息,说明了类名等,知道就好对分析帮助不大。2.2第二个模块——构造方法我们来一句一句解析,如果有之前解析重复的地方就不再重复了。但是会提供链接。.methodpublicconstructor(Ljava/lang/String;I)V这一句话分为.m
 如何在2023年将 WhatsApp 从安卓迁移到 iPhone 15?Sep 22, 2023 pm 02:37 PM
如何在2023年将 WhatsApp 从安卓迁移到 iPhone 15?Sep 22, 2023 pm 02:37 PM如何将WhatsApp聊天从Android转移到iPhone?你已经拿到了新的iPhone15,并且你正在从Android跳跃?如果是这种情况,您可能还对将WhatsApp从Android转移到iPhone感到好奇。但是,老实说,这有点棘手,因为Android和iPhone的操作系统不兼容。但不要失去希望。这不是什么不可能完成的任务。让我们在本文中讨论几种将WhatsApp从Android转移到iPhone15的方法。因此,坚持到最后以彻底学习解决方案。如何在不删除数据的情况下将WhatsApp
 同样基于linux为什么安卓效率低Mar 15, 2023 pm 07:16 PM
同样基于linux为什么安卓效率低Mar 15, 2023 pm 07:16 PM原因:1、安卓系统上设置了一个JAVA虚拟机来支持Java应用程序的运行,而这种虚拟机对硬件的消耗是非常大的;2、手机生产厂商对安卓系统的定制与开发,增加了安卓系统的负担,拖慢其运行速度影响其流畅性;3、应用软件太臃肿,同质化严重,在一定程度上拖慢安卓手机的运行速度。
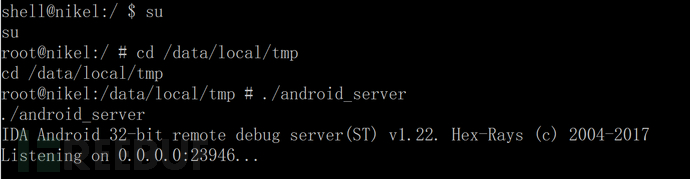 Android中动态导出dex文件的方法是什么May 30, 2023 pm 04:52 PM
Android中动态导出dex文件的方法是什么May 30, 2023 pm 04:52 PM1.启动ida端口监听1.1启动Android_server服务1.2端口转发1.3软件进入调试模式2.ida下断2.1attach附加进程2.2断三项2.3选择进程2.4打开Modules搜索artPS:小知识Android4.4版本之前系统函数在libdvm.soAndroid5.0之后系统函数在libart.so2.5打开Openmemory()函数在libart.so中搜索Openmemory函数并且跟进去。PS:小知识一般来说,系统dex都会在这个函数中进行加载,但是会出现一个问题,后
 Android APP测试流程和常见问题是什么May 13, 2023 pm 09:58 PM
Android APP测试流程和常见问题是什么May 13, 2023 pm 09:58 PM1.自动化测试自动化测试主要包括几个部分,UI功能的自动化测试、接口的自动化测试、其他专项的自动化测试。1.1UI功能自动化测试UI功能的自动化测试,也就是大家常说的自动化测试,主要是基于UI界面进行的自动化测试,通过脚本实现UI功能的点击,替代人工进行自动化测试。这个测试的优势在于对高度重复的界面特性功能测试的测试人力进行有效的释放,利用脚本的执行,实现功能的快速高效回归。但这种测试的不足之处也是显而易见的,主要包括维护成本高,易发生误判,兼容性不足等。因为是基于界面操作,界面的稳定程度便成了


热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

Dreamweaver CS6
视觉化网页开发工具

禅工作室 13.0.1
功能强大的PHP集成开发环境

EditPlus 中文破解版
体积小,语法高亮,不支持代码提示功能

SublimeText3 英文版
推荐:为Win版本,支持代码提示!

ZendStudio 13.5.1 Mac
功能强大的PHP集成开发环境

