



版主,又来求助了。。。这回事是网页返回的XML数据,我不知道为什么不能用simplexml读取,var_dump显示false
echo '#########################'.'</br></br>'; var_dump($xml); echo '#########################'; echo '<br>'.'<br>'.'<br>'.$xml->xsm->nickname;
如果用上面这段直接打印是这样子的:
echo '#########################'.'</br></br>'; var_dump(simplexml_load_string($xml); echo '#########################'; echo '<br>'.'<br>'.'<br>'.$xml->xsm->nickname;
用这段代码打印就会显示bool(false)
求解决
回复讨论(解决方案)
$xml = preg_replace('/!|--/', '', $xml);var_dump(simplexml_load_string($xml));
$xml = preg_replace('/!|--/', '', $xml);var_dump(simplexml_load_string($xml)); //$xml='<!--?xml version="1.0" encoding="gbk"?-->'; $xml = preg_replace('/!--\?|--/','', $xml); var_dump($xml); 这样我试了,单独一行可以正匹配,但是在这段代码里无效。在网页元素查看器里看到返回的数值还是有注释符
你为什么要自作聪明呢
$xml = preg_replace('/!|--/', '', $xml);var_dump(simplexml_load_string($xml)); 之前我不懂那个是xml里的注释,现在明白了,所以想到了另一种方法,可是还是失败了,能告诉我下原因吗?
$xml = '<xml version="1.0" encoding="gbk"?>'.$xml; var_dump(simplexml_load_string($xml));
我是用字符串运算符加了一行xml的文件标记,可是用simplexml_load_string的时候依然显示失败
还是那话,你为什么要自作聪明呢
你为什么要自作聪明呢
你给我的代码贴上去也是无法载入...
那是因为你不给我你的数据
还是那话,你为什么要自作聪明呢
这是直接复制给我的代码贴上去运行后的结果...
依然得去掉simplexml载入的语句才能dump出来
你光截图是没有用的!
你怎么知道其中没有不可打印的字符呢?
那是因为你不给我你的数据
<?xml version="1.0" encoding="gbk"?><xsm code="0000" msg="验证成功abc" trans_time="20140808162708"><userId>114</userId><nickName>wedc</nickName><userType>2</userType><comId>116</comId><saledptId>11601</saledptId><refId>1062014</refId><comName></comName><domainUrl>v=2014080600</domainUrl><comType>02</comType><comShort></comShort><parentComId>11620001</parentComId><expirationTime>1407488228735</expirationTime><planText>10116226011162288228735</planText><signatureValue>c6959b4eacf7b2f</signatureValue></xsm>
这是我用fwrite写入的$xml值
里面没有注释掉文件标记,可不知道问什么不能载入
你光截图是没有用的!
你怎么知道其中没有不可打印的字符呢?
在IE下查看会显示
结束标记 'xsm' 与开始标记 'comShort' 不匹配。
SimpleXMLElement Object( [@attributes] => Array ( [code] => 0000 [msg] => 验证成功abc [trans_time] => 20140808162708 ) [userId] => 114 [nickName] => wedc [userType] => 2 [comId] => 116 [saledptId] => 11601 [refId] => 1062014 [comName] => SimpleXMLElement Object ( ) [domainUrl] => v=2014080600 [comType] => 02 [comShort] => SimpleXMLElement Object ( ) [parentComId] => 11620001 [expirationTime] => 1407488228735 [planText] => 10116226011162288228735 [signatureValue] => c6959b4eacf7b2f)这不是可以吗?
你截图中显示字符串长度为 984 字节,而你贴出的只有 509 字节。
还有四百多字节到哪里去了?
你光截图是没有用的!
你怎么知道其中没有不可打印的字符呢?
版主,我知道,原因是里面有中文所以不能载入,这个如何才能解决?因为数据不是我自己的所以我也没法改
SimpleXMLElement Object( [@attributes] => Array ( [code] => 0000 [msg] => 验证成功abc [trans_time] => 20140808162708 ) [userId] => 114 [nickName] => wedc [userType] => 2 [comId] => 116 [saledptId] => 11601 [refId] => 1062014 [comName] => SimpleXMLElement Object ( ) [domainUrl] => v=2014080600 [comType] => 02 [comShort] => SimpleXMLElement Object ( ) [parentComId] => 11620001 [expirationTime] => 1407488228735 [planText] => 10116226011162288228735 [signatureValue] => c6959b4eacf7b2f)这不是可以吗?
你截图中显示字符串长度为 984 字节,而你贴出的只有 509 字节。
还有四百多字节到哪里去了?
还有400字节是一长串字符串太长我就删了半截
谢谢你,我发现原因了,是因为PHP用utf8编码的,而获取的xml数据时gbk的,把文件里的gbk改成utf8就解决了
SimpleXMLElement Object( [@attributes] => Array ( [code] => 0000 [msg] => 验证成功abc [trans_time] => 20140808162708 ) [userId] => 114 [nickName] => wedc [userType] => 2 [comId] => 116 [saledptId] => 11601 [refId] => 1062014 [comName] => SimpleXMLElement Object ( ) [domainUrl] => v=2014080600 [comType] => 02 [comShort] => SimpleXMLElement Object ( ) [parentComId] => 11620001 [expirationTime] => 1407488228735 [planText] => 10116226011162288228735 [signatureValue] => c6959b4eacf7b2f)这不是可以吗?
你截图中显示字符串长度为 984 字节,而你贴出的只有 509 字节。
还有四百多字节到哪里去了?
成功了 ~~~~~~[]

 XML外部实体注入漏洞的示例分析May 11, 2023 pm 04:55 PM
XML外部实体注入漏洞的示例分析May 11, 2023 pm 04:55 PM一、XML外部实体注入XML外部实体注入漏洞也就是我们常说的XXE漏洞。XML作为一种使用较为广泛的数据传输格式,很多应用程序都包含有处理xml数据的代码,默认情况下,许多过时的或配置不当的XML处理器都会对外部实体进行引用。如果攻击者可以上传XML文档或者在XML文档中添加恶意内容,通过易受攻击的代码、依赖项或集成,就能够攻击包含缺陷的XML处理器。XXE漏洞的出现和开发语言无关,只要是应用程序中对xml数据做了解析,而这些数据又受用户控制,那么应用程序都可能受到XXE攻击。本篇文章以java
 如何用PHP和XML实现网站的分页和导航Jul 28, 2023 pm 12:31 PM
如何用PHP和XML实现网站的分页和导航Jul 28, 2023 pm 12:31 PM如何用PHP和XML实现网站的分页和导航导言:在开发一个网站时,分页和导航功能是很常见的需求。本文将介绍如何使用PHP和XML来实现网站的分页和导航功能。我们会先讨论分页的实现,然后再介绍导航的实现。一、分页的实现准备工作在开始实现分页之前,需要准备一个XML文件,用来存储网站的内容。XML文件的结构如下:<articles><art
 php如何将xml转为json格式?3种方法分享Mar 22, 2023 am 10:38 AM
php如何将xml转为json格式?3种方法分享Mar 22, 2023 am 10:38 AM当我们处理数据时经常会遇到将XML格式转换为JSON格式的需求。PHP有许多内置函数可以帮助我们执行这个操作。在本文中,我们将讨论将XML格式转换为JSON格式的不同方法。
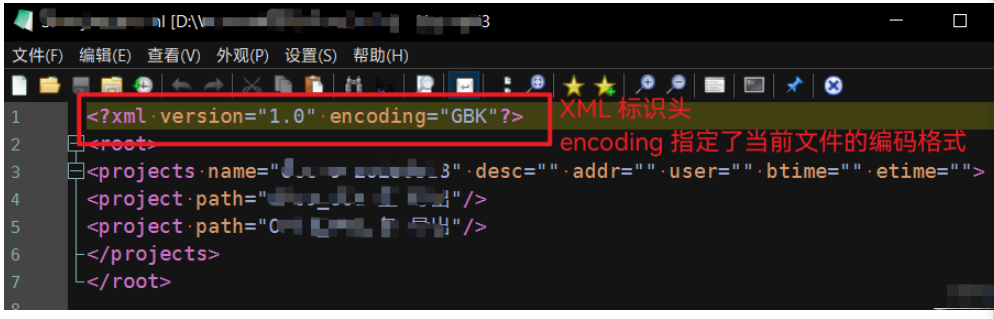 Python中怎么对XML文件的编码进行转换May 21, 2023 pm 12:22 PM
Python中怎么对XML文件的编码进行转换May 21, 2023 pm 12:22 PM1.在Python中XML文件的编码问题1.Python使用的xml.etree.ElementTree库只支持解析和生成标准的UTF-8格式的编码2.常见GBK或GB2312等中文编码的XML文件,用以在老旧系统中保证XML对中文字符的记录能力3.XML文件开头有标识头,标识头指定了程序处理XML时应该使用的编码4.要修改编码,不仅要修改文件整体的编码,还要将标识头中encoding部分的值修改2.处理PythonXML文件的思路1.读取&解码:使用二进制模式读取XML文件,将文件变为
 Python中xmltodict对xml的操作方式是什么May 04, 2023 pm 06:04 PM
Python中xmltodict对xml的操作方式是什么May 04, 2023 pm 06:04 PMPythonxmltodict对xml的操作xmltodict是另一个简易的库,它致力于将XML变得像JSON.下面是一个简单的示例XML文件:elementsmoreelementselementaswell这是第三方包,在处理前先用pip来安装pipinstallxmltodict可以像下面这样访问里面的元素,属性及值:importxmltodictwithopen("test.xml")asfd:#将XML文件装载到dict里面doc=xmltodict.parse(f
 使用nmap-converter将nmap扫描结果XML转化为XLS实战的示例分析May 17, 2023 pm 01:04 PM
使用nmap-converter将nmap扫描结果XML转化为XLS实战的示例分析May 17, 2023 pm 01:04 PM使用nmap-converter将nmap扫描结果XML转化为XLS实战1、前言作为网络安全从业人员,有时候需要使用端口扫描利器nmap进行大批量端口扫描,但Nmap的输出结果为.nmap、.xml和.gnmap三种格式,还有夹杂很多不需要的信息,处理起来十分不方便,而将输出结果转换为Excel表格,方面处理后期输出。因此,有技术大牛分享了将nmap报告转换为XLS的Python脚本。2、nmap-converter1)项目地址:https://github.com/mrschyte/nmap-
 xml中node和element的区别是什么Apr 19, 2022 pm 06:06 PM
xml中node和element的区别是什么Apr 19, 2022 pm 06:06 PMxml中node和element的区别是:Element是元素,是一个小范围的定义,是数据的组成部分之一,必须是包含完整信息的结点才是元素;而Node是节点,是相对于TREE数据结构而言的,一个结点不一定是一个元素,一个元素一定是一个结点。
 深度使用Scrapy:如何爬取HTML、XML、JSON数据?Jun 22, 2023 pm 05:58 PM
深度使用Scrapy:如何爬取HTML、XML、JSON数据?Jun 22, 2023 pm 05:58 PMScrapy是一款强大的Python爬虫框架,可以帮助我们快速、灵活地获取互联网上的数据。在实际爬取过程中,我们会经常遇到HTML、XML、JSON等各种数据格式。在这篇文章中,我们将介绍如何使用Scrapy分别爬取这三种数据格式的方法。一、爬取HTML数据创建Scrapy项目首先,我们需要创建一个Scrapy项目。打开命令行,输入以下命令:scrapys


热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

WebStorm Mac版
好用的JavaScript开发工具

适用于 Eclipse 的 SAP NetWeaver 服务器适配器
将Eclipse与SAP NetWeaver应用服务器集成。

螳螂BT
Mantis是一个易于部署的基于Web的缺陷跟踪工具,用于帮助产品缺陷跟踪。它需要PHP、MySQL和一个Web服务器。请查看我们的演示和托管服务。

SublimeText3汉化版
中文版,非常好用

Dreamweaver Mac版
视觉化网页开发工具

