



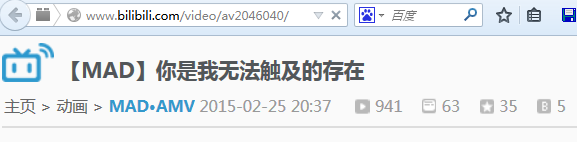
<i id="dianji" title="播放"></i><i id="dm_count" title="弹幕"></i><i id="stow_count" title="收藏"></i><i id="pt"><span class="v_ctimes" title="硬币数量"></span></i>
回复内容:
用av2047063举例,访问下面的网址:【网址已隐去】@妹空酱 提醒我才想起来。。。。
先去自己申请一个appkey。。。在这里:
bilibili - 提示
然后就可以对bilibiliapi为所欲为了。。。。
B站第三方客户端就是这么开发出来的。。。


可以看到最后两个参数id=av号&page=分p
play后面的18253即为播放数。
==============================
b站有公开api啊。。。。。。。那么麻烦干嘛。。。 答主的第一次就就交在这里了,,,
———————————————————————————————————————
前不久学习了python,正好复习一下
代码如下:
import re,urllib
page=urllib.urlopen('http://m.acg.tv/video/av2046040.html')
HTML=page.read()
re_times=r'
result = re.findall(re_times,HTML)
re_title=r'
(.*)
'title=re.findall(re_title,HTML)
print title[0],'的播放次数为',result[0]
下面以av2046040为例:http://www.bilibili.com/video/av2046040/
可以看到
 使用火狐查看选中部分源代码,如下
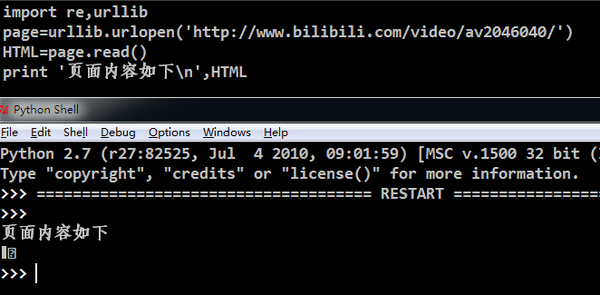
使用火狐查看选中部分源代码,如下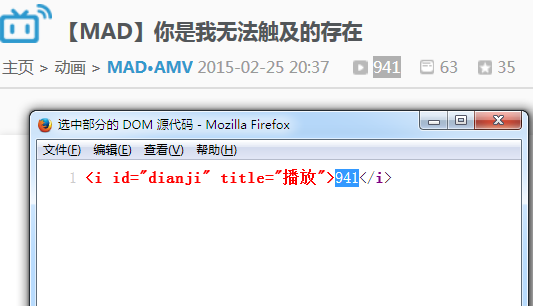 但是我通过python的urllib模块并没有获取到页面内容:
但是我通过python的urllib模块并没有获取到页面内容:page=urllib.urlopen('http://www.bilibili.com/video/av2046040/')
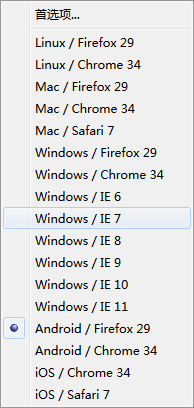
 于是我转换思路,貌似B站的手机版网页可以,
于是我转换思路,貌似B站的手机版网页可以,然后使用火狐的User-Agent Overrider修改浏览器UA为Android FireFox/29
 既可以获得如下界面:
既可以获得如下界面: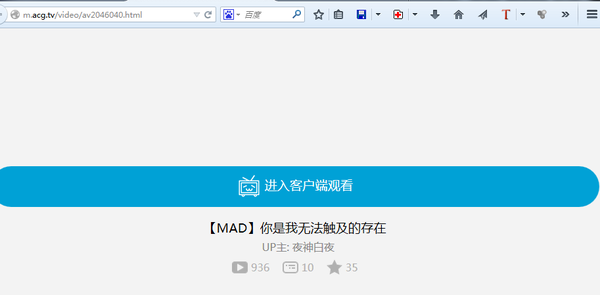 获取到页面实际地址后,就可以再次使用火狐查看源代码
获取到页面实际地址后,就可以再次使用火狐查看源代码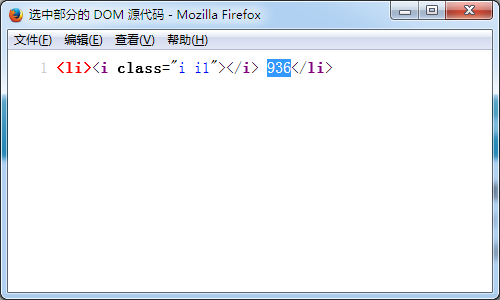 既可以写出正则表达式:
既可以写出正则表达式:re_times=r'
然后正则匹配就好了。
<span class="c"># encoding=utf8</span>
<span class="c"># author:shell-von</span>
<span class="kn">import</span> <span class="nn">requests</span>
<span class="kn">import</span> <span class="nn">re</span>
<span class="n">aid</span> <span class="o">=</span> <span class="s">'3210612'</span>
<span class="n">api_key</span> <span class="o">=</span> <span class="s">"http://interface.bilibili.com/count?key=27f582250563d5d6b11d6833&aid=</span><span class="si">%s</span><span class="s">"</span>
<span class="n">data</span> <span class="o">=</span> <span class="n">requests</span><span class="o">.</span><span class="n">get</span><span class="p">(</span><span class="n">api_key</span> <span class="o">%</span> <span class="n">aid</span><span class="p">)</span><span class="o">.</span><span class="n">content</span>
<span class="n">regex</span> <span class="o">=</span> <span class="s">r"\('(?:.|#)([\w_]+)'\)\.html\('?(\d+)'?\)"</span>
<span class="k">print</span> <span class="nb">dict</span><span class="p">(</span><span class="n">re</span><span class="o">.</span><span class="n">findall</span><span class="p">(</span><span class="n">regex</span><span class="p">,</span> <span class="n">data</span><span class="p">))</span>
以前写过一个。。。。 haogefeifei/get_bilibili_anime · GitHub
这是MATLAB的抓取,其中api可以利用Chrome的开发者工具获得:
haogefeifei/get_bilibili_anime · GitHub
这是MATLAB的抓取,其中api可以利用Chrome的开发者工具获得:<span class="n">aid</span> <span class="p">=</span> <span class="mi">3295561</span><span class="p">;</span>
<span class="n">api</span> <span class="p">=</span> <span class="s">'http://interface.bilibili.com/count?key=b9415053057bb00966665eaa'</span><span class="p">;</span>
<span class="n">data</span> <span class="p">=</span> <span class="n">regexp</span><span class="p">(</span><span class="n">webread</span><span class="p">(</span><span class="n">api</span><span class="p">,</span><span class="s">'aid'</span><span class="p">,</span><span class="n">aid</span><span class="p">),</span><span class="s">'#(\w)+\D*(\d)+'</span><span class="p">,</span><span class="s">'tokens'</span><span class="p">);</span>
<span class="n">data</span> <span class="p">=</span> <span class="p">[</span><span class="n">data</span><span class="p">{:}]</span>
说下大概的思路。0、打开特定的av页面,通过这条语句来找到CID和AID。注意:ctrl + u中能看到的源代码就是能匹配的源代码。
1、发送请求到interface.bilibili.com/player?id=cid:(匹配的CID,要前面的冒号)&aid=(匹配的AID)
2、从获取的xml文件中找到
=====================================================
实际上,我们ctrl + u看到的页面是网站发给我们的其中一个包而已,而最终的结果页面是网站发给我们的多个包组合的结果。
有时候,网站会将数据封装在json或者xml中,然后通过多个请求获取数据,最后在本地用js来进行最后的构建。
因此,页面上看到的内容是最后的结果,如果你要判断这个结果来自于源页面还是json还是xml,就需要通过开发者工具抓抓包,然后自己分析。
总之,逻辑就是:
0、这个数据哪来的? —— 通过抓包分析
1、模拟获取这个数据的过程。 —— 直接访问该数据的来源url
当然还要注意你要传的参数。这个参数从哪些地方获取也需要自己分析。
====================================================
还是举个例子吧。
注意:B站发回的数据是gzip,然而urllib2的urlopen不会自动解压,需要手动处理。
可以参考这个回答:
Does python urllib2 automatically uncompress gzip data fetched from webpage?
随便在首页找了个页面,地址如下:
【爱深黑切】路人女主的玩坏方法~第一弹
import urllib2
import re
from StringIO import StringIO
import gzip
def find_cid_aid(html):
target = re.compile('EmbedPlayer(?P<args>.*?)</script>',re.DOTALL)
cidaid = target.search(html)
cidaid = html[cidaid.start('args'):cidaid.end('args')]
cid = cidaid.find('cid=')
aid = cidaid.find('&aid=')
index = aid
while cidaid[index] != '"':
index += 1
return (cidaid[cid + 4:aid],cidaid[aid + 5:index])
def find_how_many(cid_aid):
target = re.compile(r'<click>(?P<result>.*?)</click>',re.DOTALL)
cid = cid_aid[0]
aid = cid_aid[1]
addr = r'http://interface.bilibili.com/player?id=cid:' + cid + '&aid=' + aid
f = urllib2.urlopen(addr)
res = f.read()
target = target.search(res)
return res[target.start('result'):target.end('result')]
headers = {'Accept':'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8', \
'Accept-Language':'zh-cn,zh;q=0.8,en-us;q=0.5,en;q=0.3', \
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; rv:28.0) Gecko/20100101 Firefox/28.0',\
'Host':'www.bilibili.com', \
'Accept-Encoding':'gzip, deflate', \
'Cache-Control':'max-age=0', \
'Connection':'keep-alive'}
request = urllib2.Request(r'http://www.bilibili.com/video/av2046145/', headers=headers)
html = urllib2.urlopen(request)
if html.info().get('Content-Encoding') == 'gzip':
buf = StringIO(html.read())
f = gzip.GzipFile(fileobj=buf)
html = f.read()
cid_aid = find_cid_aid(html)
print find_how_many(cid_aid)
获取cid aid请求http://interface.bilibili.com/player什么东西抓抓包就知道了
比如说如图一样的懒人眼镜,你懂的~~这里的源码直接可以直接用正则匹配到cid和aid,
cid=1511100&aid=1044050
然后请求
http://interface.bilibili.com/player?id=cid:1511100&aid=1044050
然后被
<click>4611</click>
你在电脑屏幕上面看到的一切都是数据来着啊。B站的网页也只不过是一堆代码而已。稍微获取一下源代码,解gzip压缩,转换一下编码,正则表达式搜索一下,就能出来了,很简单的。

 PHP的目的:构建动态网站Apr 15, 2025 am 12:18 AM
PHP的目的:构建动态网站Apr 15, 2025 am 12:18 AMPHP用于构建动态网站,其核心功能包括:1.生成动态内容,通过与数据库对接实时生成网页;2.处理用户交互和表单提交,验证输入并响应操作;3.管理会话和用户认证,提供个性化体验;4.优化性能和遵循最佳实践,提升网站效率和安全性。
 PHP:处理数据库和服务器端逻辑Apr 15, 2025 am 12:15 AM
PHP:处理数据库和服务器端逻辑Apr 15, 2025 am 12:15 AMPHP在数据库操作和服务器端逻辑处理中使用MySQLi和PDO扩展进行数据库交互,并通过会话管理等功能处理服务器端逻辑。1)使用MySQLi或PDO连接数据库,执行SQL查询。2)通过会话管理等功能处理HTTP请求和用户状态。3)使用事务确保数据库操作的原子性。4)防止SQL注入,使用异常处理和关闭连接来调试。5)通过索引和缓存优化性能,编写可读性高的代码并进行错误处理。
 您如何防止PHP中的SQL注入? (准备的陈述,PDO)Apr 15, 2025 am 12:15 AM
您如何防止PHP中的SQL注入? (准备的陈述,PDO)Apr 15, 2025 am 12:15 AM在PHP中使用预处理语句和PDO可以有效防范SQL注入攻击。1)使用PDO连接数据库并设置错误模式。2)通过prepare方法创建预处理语句,使用占位符和execute方法传递数据。3)处理查询结果并确保代码的安全性和性能。
 PHP和Python:代码示例和比较Apr 15, 2025 am 12:07 AM
PHP和Python:代码示例和比较Apr 15, 2025 am 12:07 AMPHP和Python各有优劣,选择取决于项目需求和个人偏好。1.PHP适合快速开发和维护大型Web应用。2.Python在数据科学和机器学习领域占据主导地位。
 PHP行动:现实世界中的示例和应用程序Apr 14, 2025 am 12:19 AM
PHP行动:现实世界中的示例和应用程序Apr 14, 2025 am 12:19 AMPHP在电子商务、内容管理系统和API开发中广泛应用。1)电子商务:用于购物车功能和支付处理。2)内容管理系统:用于动态内容生成和用户管理。3)API开发:用于RESTfulAPI开发和API安全性。通过性能优化和最佳实践,PHP应用的效率和可维护性得以提升。
 PHP:轻松创建交互式Web内容Apr 14, 2025 am 12:15 AM
PHP:轻松创建交互式Web内容Apr 14, 2025 am 12:15 AMPHP可以轻松创建互动网页内容。1)通过嵌入HTML动态生成内容,根据用户输入或数据库数据实时展示。2)处理表单提交并生成动态输出,确保使用htmlspecialchars防XSS。3)结合MySQL创建用户注册系统,使用password_hash和预处理语句增强安全性。掌握这些技巧将提升Web开发效率。
 PHP和Python:比较两种流行的编程语言Apr 14, 2025 am 12:13 AM
PHP和Python:比较两种流行的编程语言Apr 14, 2025 am 12:13 AMPHP和Python各有优势,选择依据项目需求。1.PHP适合web开发,尤其快速开发和维护网站。2.Python适用于数据科学、机器学习和人工智能,语法简洁,适合初学者。
 PHP的持久相关性:它还活着吗?Apr 14, 2025 am 12:12 AM
PHP的持久相关性:它还活着吗?Apr 14, 2025 am 12:12 AMPHP仍然具有活力,其在现代编程领域中依然占据重要地位。1)PHP的简单易学和强大社区支持使其在Web开发中广泛应用;2)其灵活性和稳定性使其在处理Web表单、数据库操作和文件处理等方面表现出色;3)PHP不断进化和优化,适用于初学者和经验丰富的开发者。


热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

SublimeText3汉化版
中文版,非常好用

Atom编辑器mac版下载
最流行的的开源编辑器

VSCode Windows 64位 下载
微软推出的免费、功能强大的一款IDE编辑器

禅工作室 13.0.1
功能强大的PHP集成开发环境

DVWA
Damn Vulnerable Web App (DVWA) 是一个PHP/MySQL的Web应用程序,非常容易受到攻击。它的主要目标是成为安全专业人员在合法环境中测试自己的技能和工具的辅助工具,帮助Web开发人员更好地理解保护Web应用程序的过程,并帮助教师/学生在课堂环境中教授/学习Web应用程序安全。DVWA的目标是通过简单直接的界面练习一些最常见的Web漏洞,难度各不相同。请注意,该软件中

