


废话少说,上干活。
for的基本操作
for是用来循环的,是从某个对象那里依次将元素读取出来。看下面的例子,将已经学习过的数据对象用for循环一下,看看哪些能够使用,哪些不能使用。同时也是复习一下过往的内容。
>>> name_str = "qiwsir"
>>> for i in name_str: #可以对str使用for循环
... print i,
...
q i w s i r
>>> name_list = list(name_str)
>>> name_list
['q', 'i', 'w', 's', 'i', 'r']
>>> for i in name_list: #对list也能用
... print i,
...
q i w s i r
>>> name_set = set(name_str) #set还可以用
>>> name_set
set(['q', 'i', 's', 'r', 'w'])
>>> for i in name_set:
... print i,
...
q i s r w
>>> name_tuple = tuple(name_str)
>>> name_tuple
('q', 'i', 'w', 's', 'i', 'r')
>>> for i in name_tuple: #tuple也能呀
... print i,
...
q i w s i r
>>> name_dict={"name":"qiwsir","lang":"python","website":"qiwsir.github.io"}
>>> for i in name_dict: #dict也不例外
... print i,"-->",name_dict[i]
...
lang --> python
website --> qiwsir.github.io
name --> qiwsir
除了上面的数据类型之外,对文件也能够用for,这在前面有专门的《不要红头文件》两篇文章讲解有关如何用for来读取文件对象的内容。看官若忘记了,可去浏览。
for在list解析中,用途也不可小觑,这在讲解list解析的时候,业已说明,不过,还是再复习一下为好,所谓学而时常复习之,不亦哈哈乎。
>>> one = range(1,9)
>>> one
[1, 2, 3, 4, 5, 6, 7, 8]
>>> [ x for x in one if x%2==0 ]
[2, 4, 6, 8]
什么也不说了,list解析的强悍,在以后的学习中会越来越体会到的,佩服佩服呀。
列位如果用python3,会发现字典解析、元组解析也是奇妙的呀。
要上升一个档次,就得进行概括。将上面所说的for循环,概括一下,就是下图所示:
请输入图片描述
用一个文字表述:
for iterating_var in sequence:
statements
iterating_var是对象sequence的迭代变量,也就是sequence必须是一个能够有某种序列的对象,特别注意没某种序列,就是说能够按照一定的脚标获取元素。当然,文件对象属于序列,我们没有用脚标去获取每行,如果把它读取出来,因为也是一个str,所以依然可以用脚标读取其内容。
zip
zip是什么东西?在交互模式下用help(zip),得到官方文档是:
zip(...)
zip(seq1 [, seq2 [...]]) -> [(seq1[0], seq2[0] ...), (...)]
Return a list of tuples, where each tuple contains the i-th element from each of the argument sequences. The returned list is truncated in length to the length of the shortest argument sequence.
通过实验来理解上面的文档:
>>> a = "qiwsir"
>>> b = "github"
>>> zip(a,b)
[('q', 'g'), ('i', 'i'), ('w', 't'), ('s', 'h'), ('i', 'u'), ('r', 'b')]
>>> c = [1,2,3]
>>> d = [9,8,7,6]
>>> zip(c,d)
[(1, 9), (2, 8), (3, 7)]
>>> e = (1,2,3)
>>> f = (9,8)
>>> zip(e,f)
[(1, 9), (2, 8)]
>>> m = {"name","lang"}
>>> n = {"qiwsir","python"}
>>> zip(m,n)
[('lang', 'python'), ('name', 'qiwsir')]
>>> s = {"name":"qiwsir"}
>>> t = {"lang":"python"}
>>> zip(s,t)
[('name', 'lang')]
zip是一个内置函数,它的参数必须是某种序列数据类型,如果是字典,那么键视为序列。然后将序列对应的元素依次组成元组,做为一个list的元素。
下面是比较特殊的情况,参数是一个序列数据的时候,生成的结果样子:
>>> a
'qiwsir'
>>> c
[1, 2, 3]
>>> zip(c)
[(1,), (2,), (3,)]
>>> zip(a)
[('q',), ('i',), ('w',), ('s',), ('i',), ('r',)]
这个函数和for连用,就是实现了:
>>> c
[1, 2, 3]
>>> d
[9, 8, 7, 6]
>>> for x,y in zip(c,d): #实现一对一对地打印
... print x,y
...
1 9
2 8
3 7
>>> for x,y in zip(c,d): #把两个list中的对应量上下相加。
... print x+y
...
10
10
10
上面这个相加的功能,如果不用zip,还可以这么写:
>>> length = len(c) if len(c)
... print c[i]+d[i]
...
10
10
10
以上两种写法那个更好呢?前者?后者?哈哈。我看差不多了。还可以这么做呢:
>>> [ x+y for x,y in zip(c,d) ]
[10, 10, 10]
前面多次说了,list解析强悍呀。当然,还可以这样的:
>>> [ c[i]+d[i] for i in range(length) ]
[10, 10, 10]
for循环语句在后面还会经常用到,其实前面已经用了很多了。所以,看官应该不感到太陌生。

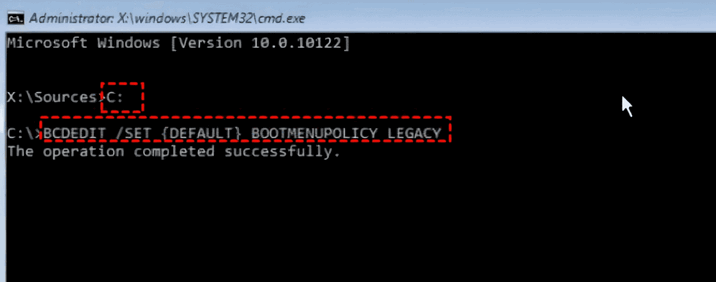 解决kernel_security_check_failure蓝屏的17种方法Feb 12, 2024 pm 08:51 PM
解决kernel_security_check_failure蓝屏的17种方法Feb 12, 2024 pm 08:51 PMKernelsecuritycheckfailure(内核检查失败)就是一个比较常见的停止代码类型,可蓝屏错误出现不管是什么原因都让很多的有用户们十分的苦恼,下面就让本站来为用户们来仔细的介绍一下17种解决方法吧。kernel_security_check_failure蓝屏的17种解决方法方法1:移除全部外部设备当您使用的任何外部设备与您的Windows版本不兼容时,则可能会发生Kernelsecuritycheckfailure蓝屏错误。为此,您需要在尝试重新启动计算机之前拔下全部外部设备。
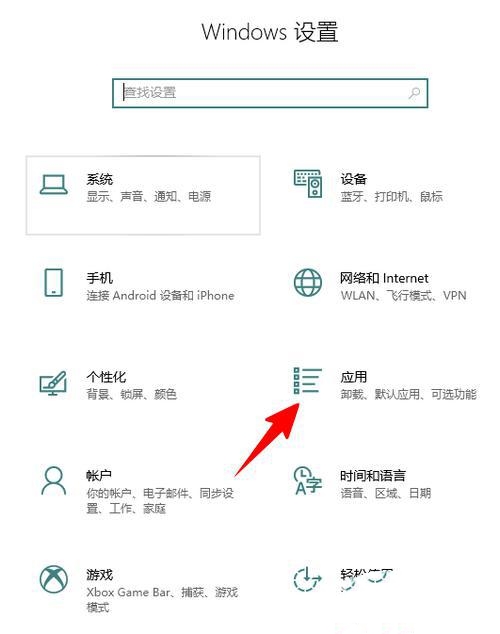 Win10如何卸载Skype for Business?电脑上的skype怎么彻底卸载方法Feb 13, 2024 pm 12:30 PM
Win10如何卸载Skype for Business?电脑上的skype怎么彻底卸载方法Feb 13, 2024 pm 12:30 PMWin10skype可以卸载吗是很多用户们都想知道的一个问题,因为很多的用户们发现自己电脑上的默认程序上有这个应用,担心删除后会影响到系统的运行,下面就让本站来为用户们来仔细的介绍一下Win10如何卸载SkypeforBusiness吧。Win10如何卸载SkypeforBusiness1、在电脑桌面点击Windows图标,再点击设置图标进入。2、点击“应用”。3、在搜索框中输入“Skype”,点击选中找到的结果。4、点击“卸载”。5
 Go语言中的循环和递归的比较研究Jun 01, 2023 am 09:23 AM
Go语言中的循环和递归的比较研究Jun 01, 2023 am 09:23 AM注:本文以Go语言的角度来比较研究循环和递归。在编写程序时,经常会遇到需要对一系列数据或操作进行重复处理的情况。为了实现这一点,我们需要使用循环或递归。循环和递归都是常用的处理方式,但在实际应用中,它们各有优缺点,因此在选择使用哪种方法时需要考虑实际情况。本文将对Go语言中的循环和递归进行比较研究。一、循环循环是一种重复执行某段代码的机制。Go语言中主要有三
 JavaScript怎么用for求n的阶乘Dec 08, 2021 pm 06:04 PM
JavaScript怎么用for求n的阶乘Dec 08, 2021 pm 06:04 PM用for求n阶乘的方法:1、使用“for (var i=1;i<=n;i++){}”语句控制循环遍历范围为“1~n”;2、循环体中,使用“cj*=i”将1到n的数相乘,乘积赋值给变量cj;3、循环结束后,变量cj的值就n的阶乘,输出即可。
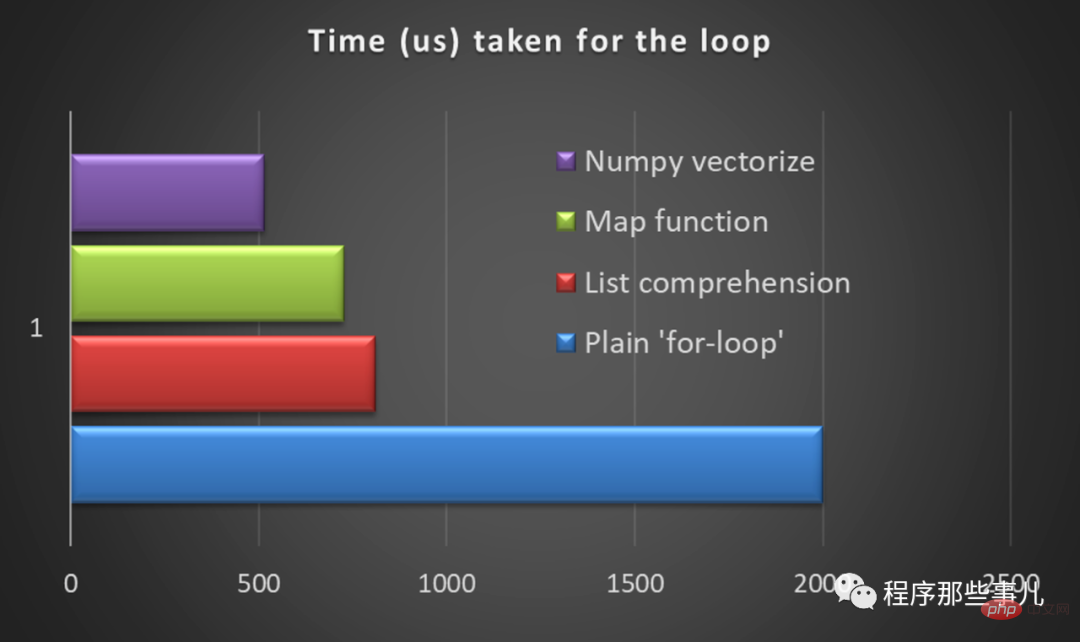 python中使用矢量化替换循环Apr 14, 2023 pm 07:07 PM
python中使用矢量化替换循环Apr 14, 2023 pm 07:07 PM所有编程语言都离不开循环。因此,默认情况下,只要有重复操作,我们就会开始执行循环。但是当我们处理大量迭代(数百万/十亿行)时,使用循环是一种犯罪。您可能会被困几个小时,后来才意识到它行不通。这就是在python中实现矢量化变得非常关键的地方。什么是矢量化?矢量化是在数据集上实现(NumPy)数组操作的技术。在后台,它将操作一次性应用于数组或系列的所有元素(不同于一次操作一行的“for”循环)。接下来我们使用一些用例来演示什么是矢量化。求数字之和##使用循环importtimestart
 如何处理PHP循环嵌套错误并生成相应的报错信息Aug 07, 2023 pm 01:33 PM
如何处理PHP循环嵌套错误并生成相应的报错信息Aug 07, 2023 pm 01:33 PM如何处理PHP循环嵌套错误并生成相应的报错信息在开发中,我们经常会用到循环语句来处理重复的任务,比如遍历数组、处理数据库查询结果等。然而,在使用循环嵌套的过程中,有时候会遇到错误,如无限循环或者嵌套层数过多,这种问题会导致服务器性能下降甚至崩溃。为了更好地处理这类错误,并生成相应的报错信息,本文将介绍一些常见的处理方式,并给出相应的代码示例。一、使用计数器来
 【总结分享】高效的PHP循环查询子分类的方法Mar 21, 2023 pm 03:49 PM
【总结分享】高效的PHP循环查询子分类的方法Mar 21, 2023 pm 03:49 PM在Web开发领域中,分类查询是一个很常见的需求,无论是电商平台还是内容管理系统,都存在着以分类为基础的数据展示方式。而随着分类层数的增加,查询子分类的任务也变得越来越复杂。本文将介绍一种高效的PHP循环查询子分类的方法,帮助开发者们轻松实现分类层次结构的管理。
 如何解决Python的循环条件错误?Jun 24, 2023 pm 07:50 PM
如何解决Python的循环条件错误?Jun 24, 2023 pm 07:50 PMPython是一门流行的高级编程语言,非常实用和灵活。但是,在使用Python编写循环时,有时会遇到循环条件错误的问题。本文将介绍Python中循环条件错误的原因和解决方法。1.循环条件错误的原因循环条件错误通常是由于变量值的错误或逻辑错误引起的。具体表现为:变量没有正确地更新。如果循环中的变量没有正确更新,循环条件将始终保持原样。条件表达式格式错误。如果条


热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

Dreamweaver Mac版
视觉化网页开发工具

SublimeText3 Linux新版
SublimeText3 Linux最新版

SublimeText3汉化版
中文版,非常好用

SublimeText3 英文版
推荐:为Win版本,支持代码提示!

ZendStudio 13.5.1 Mac
功能强大的PHP集成开发环境

