
基于PHP的cURL快速入门二

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB原创
- 2016-06-13 13:03:28822浏览
基于PHP的cURL快速入门2
?
用POST方法发送数据
当发起GET请求时,数据可以通过“查询字串”(query string)传递给一个URL。例如,在google中搜索时,搜索关键即为URL的查询字串的一部分:
http://www.google.com/search?q=nettuts
这种情况下你可能并不需要cURL来模拟。把这个URL丢给“file_get_contents()”就能得到相同结果。
不过有一些HTML表单是用POST方法提交的。这种表单提交时,数据是通过 HTTP请求体(request body) 发送,而不是查询字串。例如,当使用CodeIgniter论坛的表单,无论你输入什么关键字,总是被POST到如下页面:
http://codeigniter.com/forums/do_search/
你可以用PHP脚本来模拟这种URL请求。首先,新建一个可以接受并显示POST数据的文件,我们给它命名为post_output.php:
print_r($_POST);?
接下来,写一段PHP脚本来执行cURL请求:
以下为引用的内容:
$url = "http://localhost/post_output.php"; $post_data = array ( "foo" => "bar", "query" => "Nettuts", "action" => "Submit" ); $ch = curl_init(); curl_setopt($ch, CURLOPT_URL, $url); curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1); // 我们在POST数据哦! curl_setopt($ch, CURLOPT_POST, 1); // 把post的变量加上 curl_setopt($ch, CURLOPT_POSTFIELDS, $post_data); $output = curl_exec($ch); curl_close($ch); echo $output;?
执行代码后应该会得到以下结果:

这段脚本发送一个POST请求给 post_output.php ,这个页面 $_POST 变量并返回,我们利用cURL捕捉了这个输出。
文件上传
上传文件和前面的POST十分相似。因为所有的文件上传表单都是通过POST方法提交的。
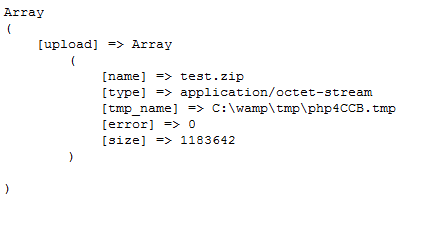
首先新建一个接收文件的页面,命名为 upload_output.php:
print_r($_FILES);
以下是真正执行文件上传任务的脚本:
以下为引用的内容:
$url = "http://localhost/upload_output.php"; $post_data = array ( "foo" => "bar", // 要上传的本地文件地址 "upload" => "@C:/wamp/www/test.zip" ); $ch = curl_init(); curl_setopt($ch, CURLOPT_URL, $url); curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1); curl_setopt($ch, CURLOPT_POST, 1); curl_setopt($ch, CURLOPT_POSTFIELDS, $post_data); $output = curl_exec($ch); curl_close($ch); echo $output;?
如果你需要上传一个文件,只需要把文件路径像一个post变量一样传过去,不过记得在前面加上@符号。执行这段脚本应该会得到如下输出:
cURL批处理(multi cURL)
cURL还有一个高级特性――批处理句柄(handle)。这一特性允许你同时或异步地打开多个URL连接。
下面是来自来自php.net的示例代码:
以下为引用的内容:
// 创建两个cURL资源
$ch1 = curl_init();
$ch2 = curl_init();
// 指定URL和适当的参数
curl_setopt($ch1, CURLOPT_URL, "http://lxr.php.net/");
curl_setopt($ch1, CURLOPT_HEADER, 0);
curl_setopt($ch2, CURLOPT_URL, "http://www.php.net/");
curl_setopt($ch2, CURLOPT_HEADER, 0);
// 创建cURL批处理句柄
$mh = curl_multi_init();
// 加上前面两个资源句柄
curl_multi_add_handle($mh,$ch1);
curl_multi_add_handle($mh,$ch2);
// 预定义一个状态变量
$active = null;
// 执行批处理
do {
$mrc = curl_multi_exec($mh, $active);
} while ($mrc == CURLM_CALL_MULTI_PERFORM);
while ($active && $mrc == CURLM_OK) {
if (curl_multi_select($mh) != -1) {
do {
$mrc = curl_multi_exec($mh, $active);
} while ($mrc == CURLM_CALL_MULTI_PERFORM);
}
}
// 关闭各个句柄
curl_multi_remove_handle($mh, $ch1);
curl_multi_remove_handle($mh, $ch2);
curl_multi_close($mh);
?
这里要做的就是打开多个cURL句柄并指派给一个批处理句柄。然后你就只需在一个while循环里等它执行完毕。
这个示例中有两个主要循环。第一个 do-while 循环重复调用 curl_multi_exec() 。这个函数是无隔断(non-blocking)的,但会尽可能少地执行。它返回一个状态值,只要这个值等于常量 CURLM_CALL_MULTI_PERFORM ,就代表还有一些刻不容缓的工作要做(例如,把对应URL的http头信息发送出去)。也就是说,我们需要不断调用该函数,直到返回值发生改变。
而接下来的 while 循环,只在 $active 变量为 true 时继续。这一变量之前作为第二个参数传给了 curl_multi_exec() ,代表只要批处理句柄中是否还有活动连接。接着,我们调用 curl_multi_select() ,在活动连接(例如接受服务器响应)出现之前,它都是被“屏蔽”的。这个函数成功执行后,我们又会进入另一个 do-while 循环,继续下一条URL。
还是来看一看怎么把这一功能用到实处吧:
WordPress 连接检查器
想象一下你有一个文章数目庞大的博客,这些文章中包含了大量外部网站链接。一段时间之后,因为这样那样的原因,这些链接中相当数量都失效了。要么是被和谐了,要么是整个站点都被功夫网了...
我们下面建立一个脚本,分析所有这些链接,找出打不开或者404的网站/网页,并生成一个报告。
请注意,以下并不是一个真正可用的WordPress插件,仅仅是一段独立功能的脚本而已,仅供演示,谢谢。
好,开始吧。首先,从数据库中读取所有这些链接:
以下为引用的内容:
// CONFIG
$db_host = 'localhost';
$db_user = 'root';
$db_pass = '';
$db_name = 'wordpress';
$excluded_domains = array(
'localhost', 'www.mydomain.com');
$max_connections = 10;
// 初始化一些变量
$url_list = array();
$working_urls = array();
$dead_urls = array();
$not_found_urls = array();
$active = null;
// 连到 MySQL
if (!mysql_connect($db_host, $db_user, $db_pass)) {
die('Could not connect: ' . mysql_error());
}
if (!mysql_select_db($db_name)) {
die('Could not select db: ' . mysql_error());
}
// 找出所有含有链接的文章
$q = "SELECT post_content FROM wp_posts
WHERE post_content LIKE '%href=%'
AND post_status = 'publish'
AND post_type = 'post'";
$r = mysql_query($q) or die(mysql_error());
while ($d = mysql_fetch_assoc($r)) {
// 用正则匹配链接
if (preg_match_all("!href=\"(.*?)\"!", $d['post_content'], $matches)) {
foreach ($matches[1] as $url) {
// exclude some domains
$tmp = parse_url($url);
if (in_array($tmp['host'], $excluded_domains)) {
continue;
}
// store the url
$url_list []= $url;
}
}
}
// 移除重复链接
$url_list = array_values(array_unique($url_list));
if (!$url_list) {
die('No URL to check');
}
?
我们首先配置好数据库,一系列要排除的域名($excluded_domains),以及最大并发连接数($max_connections)。然后,连接数据库,获取文章和包含的链接,把它们收集到一个数组中($url_list)。