



介绍
检索增强生成(RAG)管道正在改善AI系统与自定义数据的交互方式,但是我们将重点关注的两个关键组件:内存和混合搜索。在本文中,我们将探讨如何整合这些强大的功能可以将您的抹布系统从简单的提问工具转换为上下文感知的,智能的对话代理。
RAG中的内存使您的系统可以维护和利用对话历史记录,创建更连贯和上下文相关的交互。同时,混合搜索将对矢量搜索的语义理解与基于关键字的方法的精确度相结合,从而大大提高了抹布管道的检索准确性。
在本文中,我们将使用LlamainDex使用QDRANT作为矢量商店和Google的Gemini作为我们的大语言模型来实施内存和混合搜索。
学习目标
- 对内存在抹布系统中的作用及其对生成上下文准确响应的影响获得实施理解。
- 学习将Google的Google的Gemini LLM和QDrant快速嵌入在LlamainDex框架中,这很有用,因为OpenAI是LlamainDex中使用的默认LLM和嵌入模型。
- 使用Qdrant矢量存储来开发混合搜索技术的实现,结合向量和关键字搜索以增强抹布应用程序中的检索精度。
- 探索Qdrant作为矢量商店的功能,重点关注其内置的混合搜索功能和快速嵌入功能。
本文作为数据科学博客马拉松的一部分发表。
目录
- QDRANT中的混合搜索
- 使用LlamainDex的记忆和混合搜索
- 步骤1:安装要求
- 步骤2:定义LLM和嵌入模型
- 步骤3:加载数据
- 步骤4:通过混合搜索设置QDRANT
- 步骤5:索引您的文档
- 步骤6:查询索引查询引擎
- 步骤7:定义内存
- 步骤8:创建带有内存的聊天引擎
- 步骤9:测试内存
- 常见问题
QDRANT中的混合搜索
想象一下,您正在为大型电子商务网站构建聊天机器人。用户问:“向我展示最新的iPhone型号。”通过传统的矢量搜索,您可能会获得语义上相似的结果,但是您可能会错过确切的匹配。另一方面,关键字搜索可能太严格了。混合搜索为您提供了两全其美的最好:
- 向量搜索捕获语义含义和上下文
- 关键字搜索确保特定术语的精度
Qdrant是我们本文首选的矢量商店,也是充分的理由:
- Qdrant在定义时只需启用混合参数即可轻松实现混合搜索。
- 它带有使用快速培训的优化嵌入模型,其中该模型以ONNX格式加载。
- QDRANT实施优先考虑保护敏感信息,提供多功能部署选项,最小化响应时间并减少运营费用。
使用LlamainDex的记忆和混合搜索
我们将深入研究LlamainDex框架内的内存和混合搜索的实际实施,展示这些功能如何增强检索增强发电(RAG)系统的功能。通过集成这些组件,我们可以创建一个更聪明,更感知的对话代理,该代理有效地利用了历史数据和高级搜索技术。
步骤1:安装要求
好吧,让我们逐步分解这一点。我们将使用LlamainDex,Qdrant矢量商店,从QDRANT进行了快进,以及Google的Gemini模型。确保已安装这些库:
! !
步骤2:定义LLM和嵌入模型
首先,让我们导入依赖关系并设置API密钥:
导入操作系统 从GetPass Import GetPass 来自llama_index.llms.gemini Import gemini 来自llama_index.embeddings.Fastembed进口fastembedembedding Google_api_key = getPass(“输入您的双子座API:”) os.environ [“ Google_api_key”] = Google_api_key llm = gemini()#gemini 1.5闪光灯 embed_model = fastembedembedding()
现在,让我们测试API当前是否是通过在示例用户查询上运行该LLM来定义的。
llm_response = llm.complete(“一件开始?”)。 打印(llm_response)
在Llamaindex中,OpenAI是默认的LLM和嵌入模型,以覆盖我们需要从LlamainDex Core定义设置。在这里,我们需要覆盖LLM和嵌入模型。
来自llama_index.core导入设置 settings.llm = llm settings.embed_model = embed_model
步骤3:加载数据
在此示例中,假设我们在数据文件夹中有一个PDF,我们可以使用LlamainDex中的SimpleDirectory Reader加载数据文件夹。
来自llama_index.core导入simpledirectoryReader documents = simpleDirectoryReader(“ ./ data/”)。load_data()
步骤4:通过混合搜索设置QDRANT
我们需要定义一个QDRANTVECTORSTORE实例,并将其设置在此示例中。我们还可以使用其云服务或Localhost来定义QDrant客户端,但是在我们的内存文章中,具有收集名称的定义应该可以。
确保enable_hybrid = true,因为这允许我们使用QDRANT的混合搜索功能。我们的收藏名称是“纸”,因为数据文件夹在有关代理商的研究论文中包含PDF。
来自llama_index.core导入vectorstoreindex,StorageContext
来自llama_index.vector_stores.qdrant导入QDRANTVECTORSTORE
导入qdrant_client
客户端= qdrant_client.qdrantclient(
位置=“:内存:”,
)
vector_store = qdrantVectorstore(
collection_name =“纸”,
客户端=客户端,
enable_hybrid = true,#混合搜索将进行
batch_size = 20,
)
步骤5:索引您的文档
通过在我们的抹布系统中实现内存和混合搜索,我们创建了一个更聪明,更聪明的上下文-A
Storage_Context = StorageContext.from_defaults(vector_store = vector_store)
index = vectorstoreIndex.from_documents(
文件,
storage_context = storage_context,
)
步骤6:查询索引查询引擎
索引是我们在LlamainDex中定义猎犬和发电机链的部分。它处理文档集合中的每个文档,并为每个文档的内容生成嵌入式。然后,它将这些嵌入在我们的Qdrant矢量存储中。它创建了一个索引结构,可有效检索。在定义查询引擎时,请确保在混合动力车中查询模式。
query_engine = index.as_query_engine(
vector_store_query_mode =“ hybrid”
)
revertmon1 = query_engine.query(“生活的含义是什么?”)
打印(响应1)
revertmon2 = query_engine.query(“在2个句子中给出摘要”)
打印(响应2)
在上面的查询引擎中,我们运行两个查询,一个是在上下文中,另一个在上下文之外。这是我们得到的输出:
输出 #响应1 提供的文本着重于使用大语模型(LLMS)在自主代理中计划。 它没有讨论生活的含义。 #响应2 本文档探讨了大型语言模型(LLM)作为解决复杂任务的代理。 它专注于两种主要方法: 分解优先的方法, 在执行前将任务分解为子任务,而 交错分解方法,该方法基于反馈动态调整分解。
步骤7:定义内存
虽然我们的聊天机器人表现良好并提供了改进的响应,但它仍然缺乏多个交互之间的上下文意识。这是记忆进入图片的地方。
来自llama_index.core.memory Import ChatMemorybuffer 内存= chatmemorybuffer.from_defaults(token_limit = 3000)
步骤8:创建带有内存的聊天引擎
我们将创建一个使用混合搜索和内存的聊天引擎。在LlamainDex中,当我们拥有外部或外部数据时,请确保聊天模式是上下文。
chat_engine = index.as_chat_engine(
chat_mode =“上下文”,
内存=内存,
system_prompt =(
“您是AI助手,他们回答用户问题”
),
)
步骤9:测试内存
让我们进行一些查询,并检查内存是否按预期工作。
从ipython.display导入降价,显示 check1 = chat_engine.chat(“在2句中给摘要”) check2 = chat_engine.chat(“继续摘要,在上两个句子中再添加一个句子”) check3 = chat_engine.chat(“将上述抽象变成诗”)


结论
我们探讨了将内存和混合搜索集成到检索增强发电(RAG)系统中如何显着增强其功能。通过将LlamainDex与Qdrant用作矢量商店和Google的双子座作为大语言模型,我们演示了混合搜索如何结合向量和基于关键字的检索的优势,以提供更精确的结果。内存的添加进一步改善了上下文理解,从而使聊天机器人能够在多个交互之间提供连贯的响应。这些功能共同创造了一个更聪明,更智能的上下文感知系统,使破布管道对复杂的AI应用程序更有效。
关键要点
- RAG管道中的内存组件的实现显着增强了聊天机器人的上下文意识和在多个交互之间保持连贯对话的能力。
- 使用QDRANT作为矢量存储的混合搜索集成,结合了向量和关键字搜索的优势,以提高抹布系统中的检索准确性和相关性,从而最大程度地减少了幻觉的风险。免责声明,它并没有完全消除幻觉,而是降低了风险。
- 利用Llamaindex的ChatMemoryBuffer进行对话历史的有效管理,并具有可配置的令牌限制,以平衡上下文保留和计算资源。
- 将Google的双子座模型纳入Llamaindex框架中,并将其嵌入提供商嵌入,展示了LlamainDex在适应不同的AI模型和嵌入技术方面的灵活性。
常见问题
问1。什么是混合搜索,为什么在抹布中很重要?答:混合搜索结合了矢量搜索以获取语义理解和关键字搜索精度。它通过允许系统同时考虑上下文和确切的术语来提高结果的准确性,从而可以更好地检索结果,尤其是在复杂的数据集中。
Q2。为什么在抹布中使用QDrant进行混合搜索?答:QDRANT支持框开的混合搜索,可针对快速嵌入式进行优化,并且可扩展。这使其成为在抹布系统中同时实施基于向量和关键字的搜索的可靠选择,从而确保大规模的性能。
Q3。内存如何改善抹布系统?A.抹布系统中的内存可以保留对话历史记录,从而使聊天机器人能够在交互之间提供更连贯和上下文的准确响应,从而显着增强了用户体验。
Q 4。我可以将本地模型代替基于云的API用于抹布应用吗?答:是的,您可以运行本地LLM(例如Ollama或HuggingFace),而不是使用OpenAI之类的基于云的API。这使您可以在不上传到外部服务器的情况下保持对数据的完全控制,这是对隐私敏感应用程序的普遍关注点。
本文所示的媒体不由Analytics Vidhya拥有,并由作者酌情使用。
以上是使用llamaindex在抹布中的记忆和混合搜索的详细内容。更多信息请关注PHP中文网其他相关文章!

 易于理解的解释如何使用ChatGpt提高库存管理效率!May 14, 2025 am 03:44 AM
易于理解的解释如何使用ChatGpt提高库存管理效率!May 14, 2025 am 03:44 AM即使对于中小型企业,易于实施!与Chatgpt和Excel的明智库存管理 库存管理是您业务的命脉。储存过多和库存的物品对现金流和客户满意度有严重影响。但是,目前的情况是,在成本方面引入全尺度库存管理系统很高。 您想关注的是Chatgpt和Excel的组合。在本文中,我们将逐步解释如何使用此简单方法简化库存管理。 自动化数据分析,需求预测和报告以显着提高运营效率等任务。而且,
 易于理解的解释如何检查和切换chatgpt的版本!May 14, 2025 am 03:43 AM
易于理解的解释如何检查和切换chatgpt的版本!May 14, 2025 am 03:43 AM通过选择chatgpt版本明智地使用AI!对最新信息以及如何检查的详尽说明 Chatgpt是一种不断发展的AI工具,但其功能和性能因版本而异。在本文中,我们将以易于理解的方式解释每个版本的Chatgpt的功能,如何检查最新版本以及免费版本和付费版本之间的差异。选择最佳版本,并充分利用您的AI潜力。 单击此处以获取有关Openai最新AI代理OpenAi Deep Research⬇️的更多信息 [chatgpt] openai d
 解释为什么您不能将信用卡与Chatgpt的付费计划一起使用以及如何处理的原因May 14, 2025 am 03:32 AM
解释为什么您不能将信用卡与Chatgpt的付费计划一起使用以及如何处理的原因May 14, 2025 am 03:32 AMChatGPT付费订阅的信用卡支付故障排除指南 使用ChatGPT付费订阅时,信用卡支付可能会遇到问题。本文将探讨信用卡被拒的原因以及相应的解决方法,从用户自行解决的问题到需要联系信用卡公司的情况,提供详尽的指南,助您顺利使用ChatGPT付费订阅。 OpenAI发布的最新AI代理,“OpenAI Deep Research”详情请点击⬇️ 【ChatGPT】OpenAI Deep Research详解:使用方法及收费标准 目录 ChatGPT信用卡支付失败的原因 原因一:信用卡信息输入错误 原
 易于理解的解释如何在Chatgpt中创建VBA宏!May 14, 2025 am 02:40 AM
易于理解的解释如何在Chatgpt中创建VBA宏!May 14, 2025 am 02:40 AM对于初学者和对业务自动化感兴趣的人,编写VBA脚本(Microsoft Office的扩展程序)可能会觉得很困难。但是,ChatGpt使简化和自动化业务流程变得容易。 本文以易于理解的方式解释了如何使用ChatGpt开发VBA脚本。我们将详细介绍特定的示例,包括从VBA的基础到使用ChatGpt集成,测试和调试的所有内容,以及要注意的好处和点。为了提高编程技能并提高业务效率,
 我无法使用ChatGpt插件功能!解释在错误时该怎么做May 14, 2025 am 01:56 AM
我无法使用ChatGpt插件功能!解释在错误时该怎么做May 14, 2025 am 01:56 AMChatGPT插件无法使用?这篇指南将帮助您解决问题!您是否遇到过ChatGPT插件无法使用或突然失效的情况?ChatGPT插件是提升用户体验的强大工具,但有时也会出现故障。本文将详细分析ChatGPT插件无法正常工作的原因,并提供相应的解决方法。从用户设置检查到服务器故障排查,我们涵盖了各种故障排除方案,助您高效利用插件完成日常任务。 OpenAI发布的最新AI代理——OpenAI Deep Research,详情请点击⬇️ [ChatGPT] OpenAI Deep Research详解:使
 chatgpt是否不遵循字符计数规范?关于如何处理这个问题的详尽解释!May 14, 2025 am 01:54 AM
chatgpt是否不遵循字符计数规范?关于如何处理这个问题的详尽解释!May 14, 2025 am 01:54 AM在使用chatgpt编写句子时,有时您想指定字符数。但是,很难准确预测AI生成的句子的长度,并且匹配指定数量的字符并不容易。 在本文中,我们将解释如何创建一个句子,其中chatgpt中的字符数量。我们将介绍有效的及时写作,获取适合您目的的答案的技术,并教您处理角色限制的技巧。此外,我们将解释为什么Chatgpt不擅长指定角色的数量及其工作方式,以及要谨慎和对策的要点。 本文
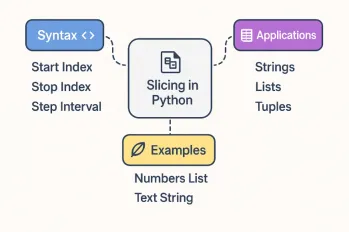 关于Python切片操作的所有内容May 14, 2025 am 01:48 AM
关于Python切片操作的所有内容May 14, 2025 am 01:48 AM对于每个Python程序员,无论是在数据科学和机器学习的领域还是软件开发领域,Python切片操作都是最有效,最多功能和强大的操作之一。 Python切片语法
 易于理解的解释如何使用Chatgpt创建报价!May 14, 2025 am 01:44 AM
易于理解的解释如何使用Chatgpt创建报价!May 14, 2025 am 01:44 AMAI技术的发展提高了业务效率。特别引起关注的是使用AI创建估计值。 Openai的AI助理Chatgpt有助于改善估计创建过程并提高准确性。 本文说明了如何使用chatgpt创建报价。我们将通过与Excel VBA的合作,系统开发项目的应用,AI实施的好处以及未来的前景来介绍效率提高。了解如何通过Chatgpt提高运营效率和生产力。 OP


热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

Video Face Swap
使用我们完全免费的人工智能换脸工具轻松在任何视频中换脸!

热门文章
热工具

mPDF
mPDF是一个PHP库,可以从UTF-8编码的HTML生成PDF文件。原作者Ian Back编写mPDF以从他的网站上“即时”输出PDF文件,并处理不同的语言。与原始脚本如HTML2FPDF相比,它的速度较慢,并且在使用Unicode字体时生成的文件较大,但支持CSS样式等,并进行了大量增强。支持几乎所有语言,包括RTL(阿拉伯语和希伯来语)和CJK(中日韩)。支持嵌套的块级元素(如P、DIV),

SublimeText3汉化版
中文版,非常好用

WebStorm Mac版
好用的JavaScript开发工具

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver Mac版
视觉化网页开发工具

