
小语言模型的绩效评估

- Christopher Nolan原创
- 2025-03-17 09:16:15997浏览
本文探讨了小语言模型(SLM)的优势,而不是其较大的对应物,重点是它们对资源约束环境的适用性。 SLM少于100亿个参数,为边缘计算和实时应用程序提供速度和资源效率至关重要。本文使用Ollama在Google Colab上详细介绍了他们的创建,应用程序和实施。
本指南涵盖:
- 了解SLM:了解SLM的定义特征及其与LLM的关键差异。
- SLM创建技术:探索用于从LLM创建有效SLM的知识蒸馏,修剪和量化方法。
- 绩效评估:通过对其输出的比较分析,比较各种SLM(Llama 2,Microsoft Phi,Qwen 2,Gemma 2,Mistral 7b)的性能。
- 实际实施:使用Ollama在Google Colab上运行SLMS的分步指南。
- SLMS的应用:发现SLMS Excel(包括聊天机器人,虚拟助手和边缘计算方案)的不同应用程序。
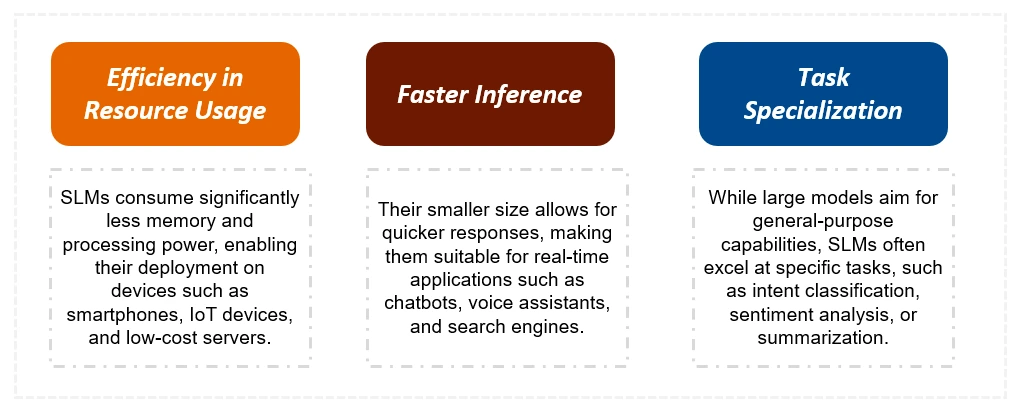
关键差异:SLM与LLMS
SLM明显小于LLM,需要更少的培训数据和计算资源。这导致推理时间更快,成本较低。虽然LLM在复杂的任务中表现出色,但SLM是针对特定任务进行了优化的,并且更适合于资源有限的设备。下表总结了关键区别:
| 特征 | 小语言模型(SLM) | 大语言模型(LLM) |
|---|---|---|
| 尺寸 | 明显较小(100亿以下参数) | 大得多(数百万或万亿个参数) |
| 培训数据 | 较小,集中的数据集 | 大量,多样化的数据集 |
| 训练时间 | 较短(周) | 更长(月) |
| 资源 | 低计算要求 | 高计算要求 |
| 任务能力 | 专业任务 | 通用任务 |
| 推理 | 可以在边缘设备上运行 | 通常需要强大的GPU |
| 响应时间 | 快点 | 慢点 |
| 成本 | 降低 | 更高 |
建筑SLM:技术和示例
本节详细介绍了从LLMS创建SLM的方法:
- 知识蒸馏:较小的“学生”模型从较大的“老师”模型的输出中学习。
- 修剪:在较大模型中删除不太重要的连接或神经元。
- 量化:降低模型参数的精度,降低内存要求。
然后,文章对几个最先进的SLM进行了详细比较,包括Llama 2,Microsoft Phi,Qwen 2,Gemma 2和Mismtral 7b,突出了它们的独特功能和性能基准。

在Google Colab上与Ollama一起运行SLM
一份实用指南演示了如何使用Ollama在Google Colab上运行SLM,并提供用于安装,模型选择和及时执行的代码段。本文展示了来自不同模型的输出,从而可以直接比较其在示例任务上的性能。
结论和常见问题解答
本文总结了SLM的优势及其对各种应用的适用性。一个常见的问题部分介绍了有关SLM,知识蒸馏以及修剪和量化之间的差异的常见疑问。关键要点强调了SLM在效率和绩效之间实现的平衡,使其成为开发人员和企业的宝贵工具。
以上是小语言模型的绩效评估的详细内容。更多信息请关注PHP中文网其他相关文章!
声明:
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系admin@php.cn