



Object detection is pivotal in artificial intelligence, serving as the backbone for numerous cutting-edge applications. From autonomous vehicles and surveillance systems to medical imaging and augmented reality, the ability to identify and locate objects in images and videos is transforming industries worldwide. TensorFlow’s Object Detection API, a powerful and versatile tool, simplifies building robust object detection models. By leveraging this API, developers can train custom models tailored to specific needs, significantly reducing development time and complexity.
In this guide, we will explore the step-by-step process of training an object detection model using TensorFlow,focusing on integrating datasets fromRoboflow Universe,a rich repository of annotated datasets designed to accelerate AI development.
Learning Objectives
- Learn to set up and configure TensorFlow‘s Object Detection API environment for efficient model training.
- Understand how to prepare and preprocess datasets for training, using the TFRecord format.
- Gain expertise in selecting and customizing a pre-trained object detection model for specific needs.
- Learn to adjust pipeline configuration files and fine-tune model parameters to optimize performance.
- Master the training process, including handling checkpoints and evaluating model performance during training.
- Understand how to export the trained model for inference and deployment in real-world applications.
This article was published as a part of theData Science Blogathon.
Table of contents
- Step-By-Step Implementation of Object Detection with TensorFlow
- Step1: Setting Up the Environment
- Step2: Verify Environment and Installations
- Step3: Prepare the Training Data
- Step4: Set Up the Training Configuration
- Step5: Modify the Pipeline Configuration File
- Step6: Train the Model
- Step7: Save the Trained Model
- Conclusion
- Frequently Asked Questions
Step-By-Step Implementation of Object Detection with TensorFlow
In this section, we’ll walk you through a step-by-step implementation of object detection using TensorFlow, guiding you from setup to deployment.
Step1: Setting Up the Environment
The TensorFlow Object Detection API requires various dependencies. Begin by cloning the TensorFlow models repository:
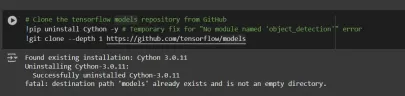
# Clone the tensorflow models repository from GitHub !pip uninstall Cython -y # Temporary fix for "No module named 'object_detection'" error !git clone --depth 1 https://github.com/tensorflow/models
- Uninstall Cython: This step ensures there are no conflicts with the Cython library during setup.
- Clone TensorFlow Models Repository: This repository contains TensorFlow’s official models, including the Object Detection API.
Copy the Setup Files andModify the setup.py File
# Copy setup files into models/research folder
%%bash
cd models/research/
protoc object_detection/protos/*.proto --python_out=.
#cp object_detection/packages/tf2/setup.py .
# Modify setup.py file to install the tf-models-official repository targeted at TF v2.8.0
import re
with open('/content/models/research/object_detection/packages/tf2/setup.py') as f:
s = f.read()
with open('/content/models/research/setup.py', 'w') as f:
# Set fine_tune_checkpoint path
s = re.sub('tf-models-official>=2.5.1',
'tf-models-official==2.8.0', s)
f.write(s)
Why is This Necessary?
- Protocol Buffers Compilation: The Object Detection API uses .proto files to define model configurations and data structures. These need to be compiled into Python code to function.
- Dependency Version Compatibility: TensorFlow and its dependencies evolve. Using tf-models-official>=2.5.1 may inadvertently install an incompatible version for TensorFlow v2.8.0.
- Explicitly setting tf-models-official==2.8.0 avoids potential version conflicts and ensures stability.
Installing dependency libraries
TensorFlow models often rely on specific library versions. Fixing the TensorFlow version ensures smooth integration.
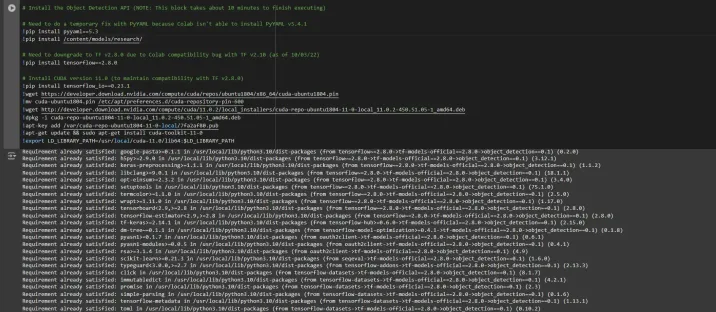
# Install the Object Detection API # Need to do a temporary fix with PyYAML because Colab isn't able to install PyYAML v5.4.1 !pip install pyyaml==5.3 !pip install /content/models/research/ # Need to downgrade to TF v2.8.0 due to Colab compatibility bug with TF v2.10 (as of 10/03/22) !pip install tensorflow==2.8.0 # Install CUDA version 11.0 (to maintain compatibility with TF v2.8.0) !pip install tensorflow_io==0.23.1 !wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu1804/x86_64/cuda-ubuntu1804.pin !mv cuda-ubuntu1804.pin /etc/apt/preferences.d/cuda-repository-pin-600 !wget http://developer.download.nvidia.com/compute/cuda/11.0.2/local_installers/cuda-repo-ubuntu1804-11-0-local_11.0.2-450.51.05-1_amd64.deb !dpkg -i cuda-repo-ubuntu1804-11-0-local_11.0.2-450.51.05-1_amd64.deb !apt-key add /var/cuda-repo-ubuntu1804-11-0-local/7fa2af80.pub !apt-get update && sudo apt-get install cuda-toolkit-11-0 !export LD_LIBRARY_PATH=/usr/local/cuda-11.0/lib64:$LD_LIBRARY_PATH
While running this block you need to restart the sessions again and run this block of code again to successfully install all dependencies. This will install all the dependencies successfully.
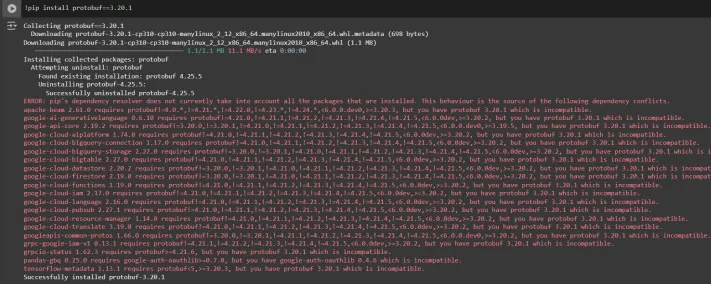
Installing an appropriate version of protobuf library for resolving dependency issues
!pip install protobuf==3.20.1
Step2: Verify Environment and Installations
To confirm the installation works, run the following test:
# Run Model Bulider Test file, just to verify everything's working properly !python /content/models/research/object_detection/builders/model_builder_tf2_test.py
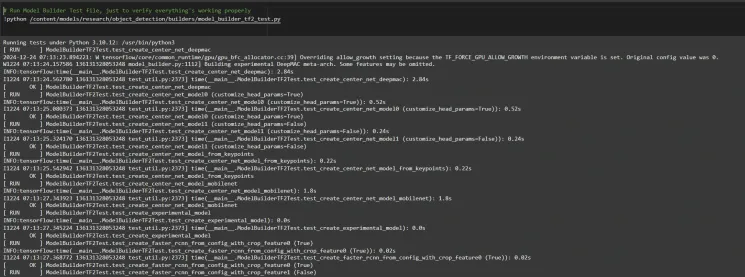
If no errors appear, your setup is complete. So now we have completed the setup successfully.
Step3: Prepare the Training Data
For this tutorial, we’ll use the “People Detection” dataset from Roboflow Universe. Follow these steps to prepare it:
Visit the dataset page:
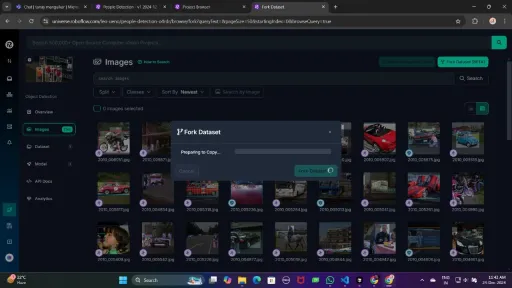
Fork the dataset into your workspace to make it accessible for customization.
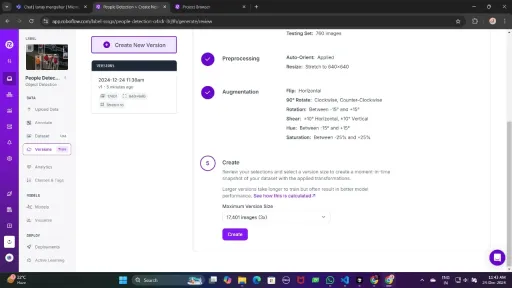
Generate a version of the dataset to finalize its preprocessing configurations such as augmentation and resizing.
Now , Download it in TFRecord format, which is a binary format optimized for TensorFlow workflows. TFRecord stores data efficiently and allows TensorFlow to read large datasets during training with minimal overhead.
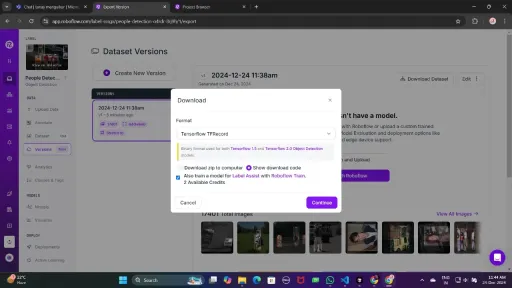
Once downloaded, place the dataset files in your Google Drive mount your code to your drive, and load those files in the code to use it.
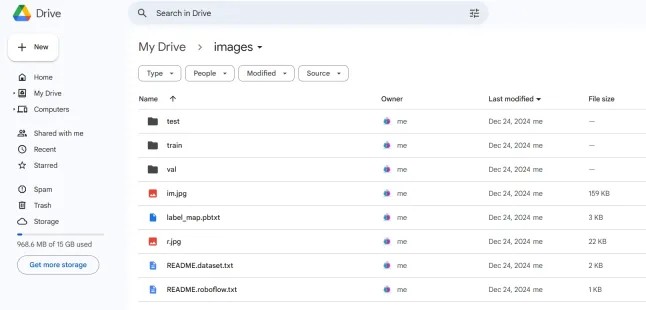
from google.colab import drive
drive.mount('/content/gdrive')
train_record_fname = '/content/gdrive/MyDrive/images/train/train.tfrecord'
val_record_fname = '/content/gdrive/MyDrive/images/test/test.tfrecord'
label_map_pbtxt_fname = '/content/gdrive/MyDrive/images/label_map.pbtxt'
Step4: Set Up the Training Configuration
Now, it’s time to set up the configuration for the object detection model. For this example, we’ll use the efficientdet-d0 model. You can choose from other models like ssd-mobilenet-v2 or ssd-mobilenet-v2-fpnlite-320, but for this guide, we’ll focus on efficientdet-d0.
# Change the chosen_model variable to deploy different models available in the TF2 object detection zoo
chosen_model = 'efficientdet-d0'
MODELS_CONFIG = {
'ssd-mobilenet-v2': {
'model_name': 'ssd_mobilenet_v2_320x320_coco17_tpu-8',
'base_pipeline_file': 'ssd_mobilenet_v2_320x320_coco17_tpu-8.config',
'pretrained_checkpoint': 'ssd_mobilenet_v2_320x320_coco17_tpu-8.tar.gz',
},
'efficientdet-d0': {
'model_name': 'efficientdet_d0_coco17_tpu-32',
'base_pipeline_file': 'ssd_efficientdet_d0_512x512_coco17_tpu-8.config',
'pretrained_checkpoint': 'efficientdet_d0_coco17_tpu-32.tar.gz',
},
'ssd-mobilenet-v2-fpnlite-320': {
'model_name': 'ssd_mobilenet_v2_fpnlite_320x320_coco17_tpu-8',
'base_pipeline_file': 'ssd_mobilenet_v2_fpnlite_320x320_coco17_tpu-8.config',
'pretrained_checkpoint': 'ssd_mobilenet_v2_fpnlite_320x320_coco17_tpu-8.tar.gz',
},
}
model_name = MODELS_CONFIG[chosen_model]['model_name']
pretrained_checkpoint = MODELS_CONFIG[chosen_model]['pretrained_checkpoint']
base_pipeline_file = MODELS_CONFIG[chosen_model]['base_pipeline_file']
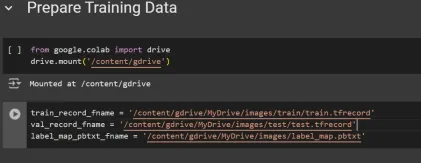
We then download the pre-trained weights and the corresponding configuration file for the chosen model:
# Create "mymodel" folder for holding pre-trained weights and configuration files
%mkdir /content/models/mymodel/
%cd /content/models/mymodel/
# Download pre-trained model weights
import tarfile
download_tar = 'http://download.tensorflow.org/models/object_detection/tf2/20200711/' + pretrained_checkpoint
!wget {download_tar}
tar = tarfile.open(pretrained_checkpoint)
tar.extractall()
tar.close()
# Download training configuration file for model
download_config = 'https://raw.githubusercontent.com/tensorflow/models/master/research/object_detection/configs/tf2/' + base_pipeline_file
!wget {download_config}
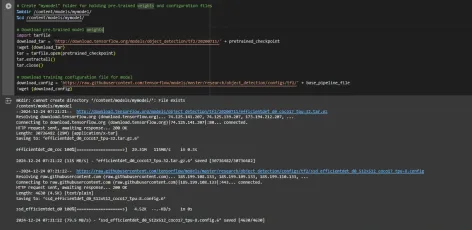
After this, we set up the number of steps for training and batch size based on the model selected:
# Set training parameters for the model num_steps = 4000 if chosen_model == 'efficientdet-d0': batch_size = 8 else: batch_size = 8
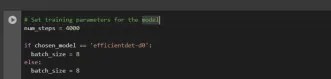
You can increase and decrease num_steps and batch_size according to your requirements.
Step5: Modify the Pipeline Configuration File
We need to customize the pipeline.config file with the paths to our dataset and model parameters. The pipeline.config file contains various configurations such as the batch size, number of classes, and fine-tuning checkpoints. We make these modifications by reading the template and replacing the relevant fields:
# Set file locations and get number of classes for config file
pipeline_fname = '/content/models/mymodel/' + base_pipeline_file
fine_tune_checkpoint = '/content/models/mymodel/' + model_name + '/checkpoint/ckpt-0'
def get_num_classes(pbtxt_fname):
from object_detection.utils import label_map_util
label_map = label_map_util.load_labelmap(pbtxt_fname)
categories = label_map_util.convert_label_map_to_categories(
label_map, max_num_classes=90, use_display_name=True)
category_index = label_map_util.create_category_index(categories)
return len(category_index.keys())
num_classes = get_num_classes(label_map_pbtxt_fname)
print('Total classes:', num_classes)
# Create custom configuration file by writing the dataset, model checkpoint, and training parameters into the base pipeline file
import re
%cd /content/models/mymodel
print('writing custom configuration file')
with open(pipeline_fname) as f:
s = f.read()
with open('pipeline_file.config', 'w') as f:
# Set fine_tune_checkpoint path
s = re.sub('fine_tune_checkpoint: ".*?"',
'fine_tune_checkpoint: "{}"'.format(fine_tune_checkpoint), s)
# Set tfrecord files for train and test datasets
s = re.sub(
'(input_path: ".*?)(PATH_TO_BE_CONFIGURED/train)(.*?")', 'input_path: "{}"'.format(train_record_fname), s)
s = re.sub(
'(input_path: ".*?)(PATH_TO_BE_CONFIGURED/val)(.*?")', 'input_path: "{}"'.format(val_record_fname), s)
# Set label_map_path
s = re.sub(
'label_map_path: ".*?"', 'label_map_path: "{}"'.format(label_map_pbtxt_fname), s)
# Set batch_size
s = re.sub('batch_size: [0-9]+',
'batch_size: {}'.format(batch_size), s)
# Set training steps, num_steps
s = re.sub('num_steps: [0-9]+',
'num_steps: {}'.format(num_steps), s)
# Set number of classes num_classes
s = re.sub('num_classes: [0-9]+',
'num_classes: {}'.format(num_classes), s)
# Change fine-tune checkpoint type from "classification" to "detection"
s = re.sub(
'fine_tune_checkpoint_type: "classification"', 'fine_tune_checkpoint_type: "{}"'.format('detection'), s)
# If using ssd-mobilenet-v2, reduce learning rate (because it's too high in the default config file)
if chosen_model == 'ssd-mobilenet-v2':
s = re.sub('learning_rate_base: .8',
'learning_rate_base: .08', s)
s = re.sub('warmup_learning_rate: 0.13333',
'warmup_learning_rate: .026666', s)
# If using efficientdet-d0, use fixed_shape_resizer instead of keep_aspect_ratio_resizer (because it isn't supported by TFLite)
if chosen_model == 'efficientdet-d0':
s = re.sub('keep_aspect_ratio_resizer', 'fixed_shape_resizer', s)
s = re.sub('pad_to_max_dimension: true', '', s)
s = re.sub('min_dimension', 'height', s)
s = re.sub('max_dimension', 'width', s)
f.write(s)
# (Optional) Display the custom configuration file's contents
!cat /content/models/mymodel/pipeline_file.config
# Set the path to the custom config file and the directory to store training checkpoints in
pipeline_file = '/content/models/mymodel/pipeline_file.config'
model_dir = '/content/training/'
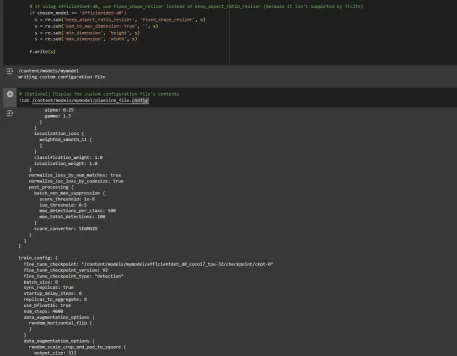
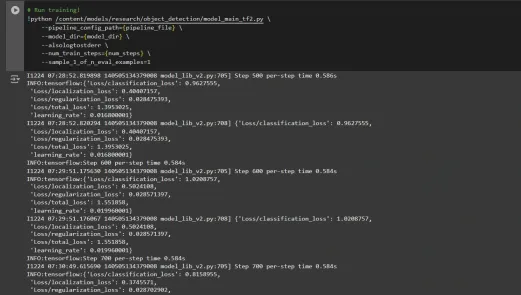
Step6: Train the Model
Now we can train the model using the custom pipeline configuration file. The training script will save checkpoints, which you can use to evaluate the performance of your model:
# Run training!
!python /content/models/research/object_detection/model_main_tf2.py \
--pipeline_config_path={pipeline_file} \
--model_dir={model_dir} \
--alsologtostderr \
--num_train_steps={num_steps} \
--sample_1_of_n_eval_examples=1
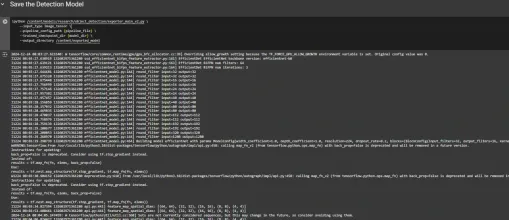
Step7: Save the Trained Model
After training is complete, we export the trained model so it can be used for inference. We use the exporter_main_v2.py script to export the model:
!python /content/models/research/object_detection/exporter_main_v2.py \
--input_type image_tensor \
--pipeline_config_path {pipeline_file} \
--trained_checkpoint_dir {model_dir} \
--output_directory /content/exported_model
Finally, we compress the exported model into a zip file for easy downloading and then you can download the zip file containing your trained model:
import shutil
# Path to the exported model folder
exported_model_path = '/content/exported_model'
# Path where the zip file will be saved
zip_file_path = '/content/exported_model.zip'
# Create a zip file of the exported model folder
shutil.make_archive(zip_file_path.replace('.zip', ''), 'zip', exported_model_path)
# Download the zip file using Google Colab's file download utility
from google.colab import files
files.download(zip_file_path)
You can use these downloaded model files for testing it on unseen images or in your applications according to your needs.
You can refer to this:collab notebook for detailed code
Conclusion
In conclusion, this guide equips you with the knowledge and tools necessary to train an object detection model using TensorFlow’s Object Detection API, leveraging datasets from Roboflow Universe for rapid customization. By following the steps outlined, you can effectively prepare your data, configure the training pipeline, select the right model, and fine-tune it to meet your specific needs. Moreover, the ability to export and deploy your trained model opens up vast possibilities for real-world applications, whether in autonomous vehicles, medical imaging, or surveillance systems. This workflow enables you to create powerful, scalable object detection systems with reduced complexity and faster time to deployment.
Key Takeaways
- TensorFlow Object Detection API offers a flexible framework for building custom object detection models with pre-trained options, reducing development time and complexity.
- TFRecord format is essential for efficient data handling, especially with large datasets in TensorFlow, allowing fast training and minimal overhead.
- Pipeline configuration files are crucial for fine-tuning and adjusting the model to work with your specific dataset and desired performance characteristics.
- Pretrained models like efficientdet-d0 and ssd-mobilenet-v2 provide solid starting points for training custom models, with each having specific strengths depending on use case and resource constraints.
- The training process involves managing parameters like batch size, number of steps, and model checkpointing to ensure the model learns optimally.
- Exporting the model is essential for using the trained object detection model in a real-world model that is being packaged and ready for deployment.
Frequently Asked Questions
Q1: What is the TensorFlow Object Detection API?A: The TensorFlow Object Detection API is a flexible and open-source framework for creating, training, and deploying custom object detection models. It provides tools for fine-tuning pre-trained models and building solutions tailored to specific use cases.
Q2: What is the purpose of the TFRecord format in object detection workflows?A: TFRecord is a binary file format optimized for TensorFlow pipelines. It allows efficient data handling, ensuring faster loading, minimal I/O overhead, and smoother training, especially with large datasets.
Q3: What are pipeline configuration files, and why are they critical?A: These files enable seamless model customization by defining parameters like dataset paths, learning rate, model architecture, and training steps to meet specific datasets and performance goals.
Q4: How do I select the best pre-trained model for my use case?A: Select EfficientDet-D0 for a balance of accuracy and efficiency, ideal for edge devices, and SSD-MobileNet-V2 for lightweight, fast real-time applications like mobile apps.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
以上是用张量集检测对象检测的详细内容。更多信息请关注PHP中文网其他相关文章!

 AI内部部署的隐藏危险:治理差距和灾难性风险Apr 28, 2025 am 11:12 AM
AI内部部署的隐藏危险:治理差距和灾难性风险Apr 28, 2025 am 11:12 AMApollo Research的一份新报告显示,先进的AI系统的不受检查的内部部署构成了重大风险。 在大型人工智能公司中缺乏监督,普遍存在,允许潜在的灾难性结果
 构建AI测谎仪Apr 28, 2025 am 11:11 AM
构建AI测谎仪Apr 28, 2025 am 11:11 AM传统测谎仪已经过时了。依靠腕带连接的指针,打印出受试者生命体征和身体反应的测谎仪,在识破谎言方面并不精确。这就是为什么测谎结果通常不被法庭采纳的原因,尽管它曾导致许多无辜者入狱。 相比之下,人工智能是一个强大的数据引擎,其工作原理是全方位观察。这意味着科学家可以通过多种途径将人工智能应用于寻求真相的应用中。 一种方法是像测谎仪一样分析被审问者的生命体征反应,但采用更详细、更精确的比较分析。 另一种方法是利用语言标记来分析人们实际所说的话,并运用逻辑和推理。 俗话说,一个谎言会滋生另一个谎言,最终
 AI是否已清除航空航天行业的起飞?Apr 28, 2025 am 11:10 AM
AI是否已清除航空航天行业的起飞?Apr 28, 2025 am 11:10 AM航空航天业是创新的先驱,它利用AI应对其最复杂的挑战。 现代航空的越来越复杂性需要AI的自动化和实时智能功能,以提高安全性,降低操作
 观看北京的春季机器人比赛Apr 28, 2025 am 11:09 AM
观看北京的春季机器人比赛Apr 28, 2025 am 11:09 AM机器人技术的飞速发展为我们带来了一个引人入胜的案例研究。 来自Noetix的N2机器人重达40多磅,身高3英尺,据说可以后空翻。Unitree公司推出的G1机器人重量约为N2的两倍,身高约4英尺。比赛中还有许多体型更小的类人机器人参赛,甚至还有一款由风扇驱动前进的机器人。 数据解读 这场半程马拉松吸引了超过12,000名观众,但只有21台类人机器人参赛。尽管政府指出参赛机器人赛前进行了“强化训练”,但并非所有机器人均完成了全程比赛。 冠军——由北京类人机器人创新中心研发的Tiangong Ult
 镜子陷阱:人工智能伦理和人类想象力的崩溃Apr 28, 2025 am 11:08 AM
镜子陷阱:人工智能伦理和人类想象力的崩溃Apr 28, 2025 am 11:08 AM人工智能以目前的形式并不是真正智能的。它擅长模仿和完善现有数据。 我们不是在创造人工智能,而是人工推断 - 处理信息的机器,而人类则
 新的Google泄漏揭示了方便的Google照片功能更新Apr 28, 2025 am 11:07 AM
新的Google泄漏揭示了方便的Google照片功能更新Apr 28, 2025 am 11:07 AM一份报告发现,在谷歌相册Android版7.26版本的代码中隐藏了一个更新的界面,每次查看照片时,都会在屏幕底部显示一行新检测到的面孔缩略图。 新的面部缩略图缺少姓名标签,所以我怀疑您需要单独点击它们才能查看有关每个检测到的人员的更多信息。就目前而言,此功能除了谷歌相册已在您的图像中找到这些人之外,不提供任何其他信息。 此功能尚未上线,因此我们不知道谷歌将如何准确地使用它。谷歌可以使用缩略图来加快查找所选人员的更多照片的速度,或者可能用于其他目的,例如选择要编辑的个人。我们拭目以待。 就目前而言
 加固芬特的指南 - 分析VidhyaApr 28, 2025 am 09:30 AM
加固芬特的指南 - 分析VidhyaApr 28, 2025 am 09:30 AM增强者通过教授模型根据人类反馈进行调整来震撼AI的开发。它将监督的学习基金会与基于奖励的更新融合在一起,使其更安全,更准确,真正地帮助
 让我们跳舞:结构化运动以微调我们的人类神经网Apr 27, 2025 am 11:09 AM
让我们跳舞:结构化运动以微调我们的人类神经网Apr 27, 2025 am 11:09 AM科学家已经广泛研究了人类和更简单的神经网络(如秀丽隐杆线虫中的神经网络),以了解其功能。 但是,出现了一个关键问题:我们如何使自己的神经网络与新颖的AI一起有效地工作


热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

Video Face Swap
使用我们完全免费的人工智能换脸工具轻松在任何视频中换脸!

热门文章
热工具

EditPlus 中文破解版
体积小,语法高亮,不支持代码提示功能

记事本++7.3.1
好用且免费的代码编辑器

禅工作室 13.0.1
功能强大的PHP集成开发环境

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)

Atom编辑器mac版下载
最流行的的开源编辑器

