



深度学习GPU基准测试彻底改变了我们解决复杂问题的方式,从图像识别到自然语言处理。但是,在培训这些模型时,通常依赖于高性能的GPU,将它们有效地部署在资源受限的环境中,例如边缘设备或有限的硬件系统提出了独特的挑战。 CPU,广泛可用且具有成本效益,通常是在这种情况下推断的骨干。但是,我们如何确保部署在CPU上的模型在不损害准确性的情况下提供最佳性能?
本文深入研究了对CPU的深度学习模型推断的基准测试,重点介绍了三个关键指标:延迟,CPU利用率和内存利用率。使用垃圾邮件分类示例,我们探讨了Pytorch,Tensorflow,Jax和ONNX运行时手柄推理工作负载等流行框架。最后,您将对如何衡量性能,优化部署并为资源受限环境中的基于CPU推断的推理选择正确的工具和框架有清晰的了解。
影响:最佳推理执行可以节省大量资金,并为其他工作量提供免费资源。
学习目标
- 了解深度学习CPU基准在评估AI模型培训和推理硬件性能中的作用。
- 评估Pytorch,Tensorflow,Jax,OnNX运行时和OpenVino运行时,以选择最适合您的需求。
- 诸如psutil的主工具和收集准确的性能数据并优化推理的时间。
- 准备模型,运行推理并衡量性能,将技术应用于图像分类和NLP等各种任务。
- 确定瓶颈,优化模型并提高性能,同时有效地管理资源。
本文作为数据科学博客马拉松的一部分发表。
目录
- 通过运行时加速进行优化推理
- 模型推理性能指标
- 假设和局限性
- 工具和框架
- 安装依赖项
- 问题说明和输入规范
- 模型架构和格式
- 基准测试的其他网络的示例
- 基准的工作流程
- 基准函数定义
- 模型推理并为每个框架执行基准测试
- 结果与讨论
- 结论
- 常见问题
通过运行时加速进行优化推理
推理速度对于用户体验和机器学习应用程序的运营效率至关重要。运行时优化在通过简化执行来增强它方面起着关键作用。使用诸如ONNX运行时的硬件加速库会利用针对特定体系结构的优化,减少延迟(每次推理时间)。
此外,轻巧的模型格式,例如ONNX最小化开销,从而更快地加载和执行。优化的运行时间利用并行处理来在可用的CPU内核上分发计算并改善内存管理,从而确保更好的性能,尤其是在资源有限的系统上。这种方法使模型在保持准确性的同时更快,更有效。
模型推理性能指标
为了评估模型的性能,我们专注于三个关键指标:
潜伏期
- 定义:延迟是指在接收输入后进行预测所需的时间。这通常是作为从发送输入数据到接收输出(预测)所花费的时间来衡量的。
- 重要性:在实时或近实时应用程序中,高潜伏期会导致延迟,这可能会导致响应较慢。
- 测量:延迟通常以毫秒(MS)或秒为单位。较短的延迟意味着该系统响应效率更高,对需要立即决策或行动的应用至关重要。
CPU利用率
- 定义:CPU利用率是执行推理任务时消耗的CPU处理能力的百分比。它告诉您模型推断期间系统使用了多少计算资源。
- 重要性:高CPU使用意味着机器可能很难同时处理其他任务,从而导致瓶颈。有效利用CPU资源可确保模型推断不会垄断系统资源。
- 测量人员T:通常以可用CPU资源总数的百分比(%)测量。同一工作负载的较低利用通常表明更优化的模型,更有效地利用CPU资源。
内存利用率
- 定义:内存利用率是指模型在推理过程中使用的RAM量。它通过模型的参数,中间计算和输入数据跟踪内存消耗。
- 重要性:在将模型部署到边缘设备或系统有限的内存中时,优化内存使用量尤为重要。高内存消耗可能会导致内存过浮力,较慢的处理或系统崩溃。
- 测量:内存利用率是Megabytes(MB)或GB(GB)中的测量值。在推理的不同阶段跟踪内存消耗可以帮助识别内存效率低下或内存泄漏。
假设和局限性
为了保持这项基准研究的重点和实用,我们做出了以下假设并设定了一些界限:
- 硬件约束:测试旨在在具有有限的CPU内核的单台计算机上运行。尽管现代硬件能够处理并行工作负载,但此设置反映了在边缘设备或较小规模部署中经常看到的约束。
- 没有多系统并行化:我们没有合并分布式计算设置或基于群集的解决方案。基准反映了性能独立条件,适用于有限的CPU内核和内存的单节点环境。
- 范围:主要重点仅在于CPU推理性能。虽然基于GPU的推理是资源密集型任务的绝佳选择,但该基准测试旨在提供对仅CPU的设置的见解,在成本敏感或便携式应用程序中更常见。
这些假设确保基准与使用资源受限硬件的开发人员和团队相关,或者需要可预测的性能而没有分布式系统的复杂性。
工具和框架
我们将探讨用于基准和优化CPU的深度学习模型推断的基本工具和框架,从而提供了对其能力的见解,以在资源受限的环境中有效执行。
分析工具
- Python Time (时间库) :Python中的时间库是用于测量代码块的执行时间的轻量级工具。通过记录开始和结束时间戳记,它有助于计算模型推理或数据处理等操作所花费的时间。
- PSUTIL(CPU,内存分析) : PSUTI L是用于维持监视和分析的Python库。它提供有关CPU使用,内存消耗,磁盘I/O等的实时数据,也非常适合在模型培训或推理过程中分析使用情况。
推理框架
- TensorFlow :一个强大的深度学习框架,广泛用于培训和推理任务。它为各种模型和部署策略提供了强有力的支持。
- Pytorch: Pytorch以易用性和动态计算图而闻名,是研究和生产部署的流行选择。
- ONNX运行时:用于运行ONXX(开放神经网络交换)模型的开源,跨平台引擎,可在各种硬件和框架上提供有效的推断。
- JAX :一个功能框架,侧重于高性能数值计算和机器学习,提供自动分化和GPU/TPU加速度。
- OpenVino:OpenVino针对英特尔硬件进行了优化,为Intel CPU,GPU和VPU提供了模型优化和部署的工具。
硬件规范和环境
我们正在利用github codespace(虚拟机),以下配置:
- 虚拟机的规格: 2个内核,8 GB RAM和32 GB存储
- Python版本: 3.12.1
安装依赖项
所使用的包装的版本如下,此主要包括五个深度学习推理库:Tensorflow,Pytorch,Onnx Runtime,Jax和OpenVino:
!pip安装numpy == 1.26.4 !pip安装火炬== 2.2.2 !PIP安装TensorFlow == 2.16.2 !pip安装onnx == 1.17.0 !pip安装onnxRuntime == 1.17.0! !pip安装jaxlib == 0.4.30 !PIP安装OpenVino == 2024.6.0 !pip安装matplotlib == 3.9.3 !pip安装matplotlib:3.4.3 !PIP安装枕头:8.3.2 !pip安装psutil:5.8.0
问题说明和输入规范
由于模型推断包括在网络权重和输入数据之间执行一些矩阵操作,因此它不需要模型培训或数据集。对于我们的示例,我们模拟了标准分类用例。这模拟了常见的二进制分类任务,例如垃圾邮件检测和贷款申请决策(批准或拒绝)。这些问题的二进制性质使它们是比较不同框架模型性能的理想选择。该设置反映了现实世界中的系统,但使我们能够将重点放在跨框架的推理性能上,而无需大型数据集或预训练的模型。
问题陈述
样本任务涉及根据一组输入功能预测给定样本是垃圾邮件(贷款批准还是拒绝)。这个二进制分类问题在计算上是有效的,可以重点分析推理性能,而没有多类分类任务的复杂性。
输入规范
为了模拟现实世界电子邮件数据,我们生成了随机输入。这些嵌入模仿垃圾邮件过滤器可能处理的数据类型,但避免了对外部数据集的需求。该模拟输入数据允许在不依赖任何特定外部数据集的情况下进行基准测试,这是测试模型推理时间,内存使用情况和CPU性能的理想选择。另外,您可以使用图像分类,NLP任务或任何其他深度学习任务来执行此基准测试过程。
模型架构和格式
模型选择是基准测试的关键步骤,因为它直接影响了从分析过程中获得的推理性能和见解。如上一节所述,对于这项基准测试研究,我们选择了标准分类用例,其中涉及确定给定的电子邮件是否是垃圾邮件。此任务是一个直接的两类分类问题,它在计算上有效,但为跨框架进行比较提供了有意义的结果。
基准测试模型架构
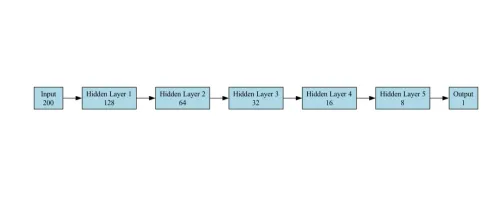
分类任务的模型是为二进制分类设计的馈电神经网络(FNN)(垃圾邮件与垃圾邮件)。它由以下层组成:
- 输入层:接受尺寸200的向量(嵌入功能)。我们提供了Pytorch的示例,其他框架遵循完全相同的网络配置
self.fc1 = torch.nn.linear(200,128)
- 隐藏层:该网络具有5个隐藏的图层,每个连续的图层包含的单位少于前面的单元。
self.fc2 = torch.nn.linear(128,64) self.fc3 = torch.nn.linear(64,32) self.fc4 = torch.nn.linear(32,16) self.fc5 = torch.nn.linear(16,8) self.fc6 = torch.nn.linear(8,1)
- 输出层:具有Sigmoid激活函数的单个神经元以输出概率(对于不垃圾邮件为0,垃圾邮件为1)。我们利用Sigmoid层作为二进制分类的最终输出。
self.sigmoid = torch.nn.sigmoid()
该模型对于分类任务很简单,但有效。
在我们的用例中用于基准测试的模型体系结构图如下所示:
基准测试的其他网络的示例
- 图像分类:可以将诸如Resnet-50(中等复杂性)和Mobilenet(轻量级)之类的模型添加到基准套件中,以进行涉及图像识别的任务。 Resnet-50在计算复杂性和准确性之间提供了平衡,而Mobilenet则针对低资源环境进行了优化。
- NLP任务: Distilbert :BERT模型的较小,更快的变体,适合自然语言理解任务。
模型格式
- 天然格式:每个框架都支持其本机模型格式,例如Pytorch的.pt和tensorflow的.h5 。
- 统一格式(ONNX) :为了确保跨框架的兼容性,我们将Pytorch模型导出到ONNX格式(model.onnx)。 ONNX(开放的神经网络交换)充当桥梁,使模型可以在Pytorch,Tensorflow,Jax或OpenVino等其他框架中使用,而无需进行重大修改。这对于互操作性至关重要的多框架测试和现实部署方案特别有用。
- 这些格式针对其各自的框架进行了优化,使其易于保存,加载和部署这些生态系统。
基准的工作流程
该工作流旨在比较使用分类任务的多个深度学习框架(Tensorflow,Pytorch,Onnx,Jax和OpenVino)的推理性能。该任务涉及使用随机生成的输入数据并根据每个框架进行基准测试以测量预测所花费的平均时间。
- 导入Python软件包
- 禁用GPU使用并抑制TensorFlow记录
- 输入数据准备
- 每个框架的模型实现
- 基准功能定义
- 每个框架的模型推理和基准测试执行
- 基准结果的可视化和导出
导入必要的Python软件包
为了开始基准测试深度学习模型,我们首先需要导入实现无缝集成和性能评估的基本Python软件包。
进口时间 导入操作系统 导入numpy作为NP 导入火炬 导入TensorFlow作为TF 来自TensorFlow.keras导入输入 导入OnnxRuntime AS Ort 导入matplotlib.pyplot作为PLT 从PIL导入图像 导入psutil 导入JAX 导入jax.numpy作为jnp 来自OpenVino.runtime Import Core 导入CSV
禁用GPU使用并抑制TensorFlow记录
os.environ [“ cuda_visible_devices”] =“ -1”#disable gpu os.environ [“ tf_cpp_min_log_level”] =“ 3” #suppress tensorflow log
输入数据准备
在此步骤中,我们随机生成用于垃圾邮件分类的输入数据:
- 样本的维度(200段的特征)
- 类的数量(2:垃圾邮件或不垃圾邮件)
我们使用Numpy生成Randome数据,以作为模型的输入功能。
#Generate虚拟数据 input_data = np.random.rand(1000,200).stype(np.float32)
模型定义
在此步骤中,我们从每个深度学习框架(Tensorflow,Pytorch,Onnx,Jax和OpenVino)定义NetWrok体系结构或设置模型。每个框架都需要一种特定的方法来加载模型并将其设置为推断。
- Pytorch模型:在Pytorch中,我们定义了一个具有五个完全连接层的简单神经网络结构。
- TensorFlow模型:使用KERAS API定义了TensorFlow模型,并由用于分类任务的简单馈电神经网络组成。
- JAX模型:该模型是用参数初始化的,并且使用JAX的JAX-IN-INTIME(JIT)汇编编辑了预测函数,以进行有效的执行。
- ONNX模型:对于ONNX,我们从Pytorch导出了一个模型。导出到ONNX格式后,我们使用OnnxRuntime加载模型。推论API。这使我们可以通过不同的硬件规范对模型进行推断。
- OpenVino模型:OpenVino用于运行优化和部署模型,尤其是使用其他框架(例如Pytorch或Tensorflow)训练的模型。我们加载ONNX型号并使用OpenVino的运行时进行编译。
Pytorch
Pytorchmodel类(Torch.nn.Module):
def __init __(自我):
超级(pytorchmodel,self).__ init __()
self.fc1 = torch.nn.linear(200,128)
self.fc2 = torch.nn.linear(128,64)
self.fc3 = torch.nn.linear(64,32)
self.fc4 = torch.nn.linear(32,16)
self.fc5 = torch.nn.linear(16,8)
self.fc6 = torch.nn.linear(8,1)
self.sigmoid = torch.nn.sigmoid()
def向前(self,x):
x = torch.relu(self.fc1(x))
x = torch.relu(self.fc2(x))
x = torch.relu(self.fc3(x))
x = torch.relu(self.fc4(x))
x = torch.relu(self.fc5(x))
x = self.sigmoid(self.fc6(x))
返回x
#创建Pytorch模型
pytorch_model = pytorchmodel()
张量
tensorflow_model = tf.keras.Sequeential([[
输入(Shape =(200,)),
tf.keras.layers.dense(128,激活='relu'),
tf.keras.layers.dense(64,activation ='relu'),
tf.keras.layers.dense(32,activation ='relu'),
tf.keras.layers.dense(16,activation ='relu'),
tf.keras.layers.dense(8,activation ='relu'),
tf.keras.layers.dense(1,激活='Sigmoid')
)))
tensorflow_model.compile()
JAX
def jax_model(x):
x = jax.nn.relu(jnp.dot(x,jnp.ones((200,128)))))))
x = jax.nn.relu(jnp.dot(x,jnp.ones(((128,64))))))))
x = jax.nn.relu(jnp.dot(x,jnp.ones((64,32))))))))
x = jax.nn.relu(jnp.dot(x,jnp.ones((32,16))))))))
x = jax.nn.relu(jnp.dot(x,jnp.ones((16,8))))))
x = jax.nn.sigmoid(jnp.dot(x,jnp.ones((8,1)))))))
返回x
onnx
#将Pytorch型号转换为ONNX
dummy_input = torch.randn(1,200)
onnx_model_path =“ model.onnx”
TORCH.ONNX.EXPORT(
pytorch_model,
dummy_input,
onnx_model_path,
export_params = true,
opset_version = 11,
input_names = ['input'],
output_names = ['输出'],
dynamic_axes = {'input':{0:'batch_size'},'output':{0:'batch_size'}}}
)
onnx_session = ort.inferencesession(onnx_model_path)
Openvino
#OpenVino模型定义 core = core() OpenVino_model = core.Read_model(model =“ model.onnx”) compiled_model = core.compile_model(openvino_model,device_name =“ cpu”)
基准函数定义
该功能通过采用三个参数来执行跨不同框架的基准测试:prection_function,input_data和num_runs。默认情况下,它执行1000次,但可以根据要求增加。
def benchmark_model(prection_function,input_data,num_runs = 1000):
start_time = time.time()
process = psutil.process(os.getPid())
cpu_usage = []
memory_usage = []
对于_范围(num_runs):
preditive_function(input_data)
cpu_usage.append(process.cpu_percent())
memory_usage.append(process.memory_info()。rss)
end_time = time.time()
avg_latency =(end_time -start_time) / num_runs
avg_cpu = np.mean(cpu_usage)
avg_memory = np.Mean(Memory_usage) /(1024 * 1024)#转换为MB
返回avg_latency,avg_cpu,avg_memory
模型推理并为每个框架执行基准测试
现在我们已经加载了模型了,现在该基于每个框架的性能进行基准测试了。基准测试过程对生成的输入数据执行推断。
Pytorch
#基准Pytorch模型
def pytorch_predict(input_data):
pytorch_model(torch.tensor(input_data)))
pytorch_latency,pytorch_cpu,pytorch_memory = benchmark_model(lambda x:pytorch_predict(x),input_data)
张量
#基准TensorFlow模型
def tensorflow_predict(input_data):
tensorflow_model(input_data)
tensorflow_latency,tensorflow_cpu,tensorflow_memory = benchmark_model(lambda x:tensorflow_predict(x),input_data)
JAX
#基准JAX模型
def jax_predict(input_data):
jax_model(jnp.array(input_data))
jax_latency,jax_cpu,jax_memory = benchmark_model(lambda x:jax_predict(x),input_data)
onnx
#基准ONNX模型
def onnx_predict(input_data):
#批量的过程输入
对于i在范围内(input_data.shape [0]):
single_input = input_data [i:i 1]#提取单输入
onnx_session.run(none,{onnx_session.get_inputs()[0] .name:single_input})
onnx_latency,onnx_cpu,onnx_memory = benchmark_model(lambda x:onnx_predict(x),input_data)
Openvino
#基准OpenVino模型
DEF OPENVINO_PREDICT(INPUT_DATA):
#批量的过程输入
对于i在范围内(input_data.shape [0]):
single_input = input_data [i:i 1]#提取单输入
compiled_model.infer_new_request({0:single_input})
OpenVINO_LATENCY,OPENVINO_CPU,OPENVINO_MEMORY = BENCHMARK_MODEL(LAMBDA X:OPENVINO_PREDICT(X),INPUT_DATA)
结果与讨论
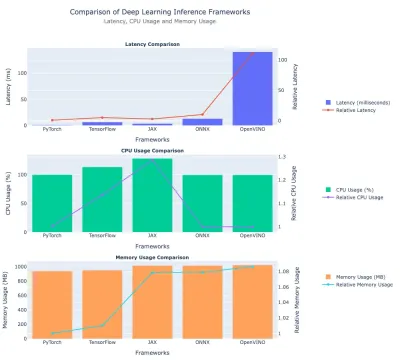
在这里,我们讨论了前面提到的深度学习框架的性能基准测试结果。我们将它们进行比较 - 延迟,CPU使用和内存使用情况。我们包含了表格数据和图,以进行快速比较。
延迟比较
| 框架 | 潜伏期(MS) | 相对延迟(与Pytorch) |
| Pytorch | 1.26 | 1.0(基线) |
| 张量 | 6.61 | 〜5.25× |
| JAX | 3.15 | 〜2.50× |
| onnx | 14.75 | 〜11.72× |
| Openvino | 144.84 | 〜115× |
见解:
- Pytorch是最快的框架,延迟〜1.26毫秒。
- TensorFlow具有〜6.61毫秒的延迟,约5.25×Pytorch的时间。
- JAX位于Pytorch和Tensorflow之间,绝对延迟。
- ONNX也相对较慢,约为14.75毫秒。
- OpenVino是该实验中最慢的,约为145 ms (比Pytorch慢115倍)。
CPU用法
| 框架 | CPU使用(%) | 相对CPU用法 1 |
| Pytorch | 99.79 | 〜1.00 |
| 张量 | 112.26 | 〜1.13 |
| JAX | 130.03 | 〜1.31 |
| onnx | 99.58 | 〜1.00 |
| Openvino | 99.32 | 1.00(基线) |
见解:
- JAX使用最多的CPU(约130% ),比OpenVino高31%。
- TensorFlow的含量约为112% ,超过Pytorch/Onnx/OpenVino,但仍低于JAX。
- Pytorch,ONNX和OpenVino的CPU使用量〜99-100% 。
内存使用
| 框架 | 内存(MB) | 相对内存使用(与Pytorch) |
| Pytorch | 〜959.69 | 1.0(基线) |
| 张量 | 〜969.72 | 〜1.01× |
| JAX | 〜1033.63 | 〜1.08× |
| onnx | 〜1033.82 | 〜1.08× |
| Openvino | 〜1040.80 | 〜1.08–1.09× |
见解:
- Pytorch和TensorFlow在〜960-970 MB附近具有相似的内存使用量
- JAX,ONNX和OpenVino的使用率约为1,030–1,040 MB ,比Pytorch高出约8–9%。
这是比较深度学习框架表现的情节:
结论
在本文中,我们提出了一个全面的基准工作流程,以评估突出的深度学习框架的推理性能 - Tensorflow,Pytorch,pytorch,Onnx,Jax和OpenVino-使用垃圾邮件分类任务作为参考。通过分析关键指标,例如延迟,CPU使用和记忆消耗,结果突出了框架与其对不同部署方案的适用性之间的权衡。
Pytorch表现出最平衡的性能,在低潜伏期和有效的内存使用方面表现出色,使其非常适合对潜伏期敏感的应用,例如实时预测和建议系统。 TensorFlow提供了一种中间地面解决方案,具有中等程度的资源消耗。 JAX展示了高计算吞吐量,但以增加CPU利用率为代价,这可能是资源受限环境的限制因素。同时,ONNX和OpenVino的潜伏期滞后,OpenVino的性能尤其受到硬件加速度的阻碍。
这些发现强调了将框架选择与部署需求保持一致的重要性。无论是针对速度,资源效率还是特定的硬件进行优化,理解权衡取舍对于在现实世界中的有效模型部署至关重要。
关键要点
- 深度学习的CPU基准为CPU性能提供了重要的见解,可帮助为AI任务选择最佳硬件。
- 利用深度学习CPU基准测试可通过识别高性能CPU来确保有效的模型培训和推断。
- 达到了最佳的延迟(1.26毫秒)并保持有效的内存使用情况,非常适合实时和资源有限的应用程序。
- 平衡延迟(6.61毫秒),使用CPU略高,适用于需要适度绩效妥协的任务。
- 提供了竞争性延迟(3.15毫秒),但以过高的CPU利用为代价( 130% ),从而限制了其在受限设置中的效用。
- 显示出较高的延迟(14.75毫秒),但其跨平台支持使其适用于多帧部署。
常见问题
Q1。为什么Pytorch首选用于实时应用?A. Pytorch的动态计算图和有效的执行管道允许低延节推断(1.26 ms),使其适合于推荐系统和实时预测等应用。
Q2。是什么影响了OpenVino在这项研究中的表现?答:OpenVino的优化是为Intel硬件设计的。没有这种加速度,与其他框架相比,它的延迟(144.84 ms)和内存使用情况(1040.8 MB)的竞争力较低。
Q3。如何为资源受限环境选择一个框架?答:对于仅CPU的设置,Pytorch是最有效的。 TensorFlow是适度工作负载的强大替代方法。除非可以接受较高的CPU利用率,否则避免使用JAX之类的框架。
Q4。硬件在框架性能中起什么作用?答:框架性能在很大程度上取决于硬件兼容性。例如,OpenVino在Intel CPU上具有特定于硬件的优化,而Pytorch和Tensorflow则在各种设置中持续执行。
Q5。基准测试结果是否会因复杂模型或任务而有所不同吗?答:是的,这些结果反映了一个简单的二进制分类任务。性能可能会随复杂的架构(例如Resnet或NLP或其他人)等任务而变化,这些框架可能会利用专业的优化。
本文所示的媒体不由Analytics Vidhya拥有,并由作者酌情使用。
以上是深度学习CPU基准的详细内容。更多信息请关注PHP中文网其他相关文章!

![无法使用chatgpt!解释可以立即测试的原因和解决方案[最新2025]](https://img.php.cn/upload/article/001/242/473/174717025174979.jpg?x-oss-process=image/resize,p_40) 无法使用chatgpt!解释可以立即测试的原因和解决方案[最新2025]May 14, 2025 am 05:04 AM
无法使用chatgpt!解释可以立即测试的原因和解决方案[最新2025]May 14, 2025 am 05:04 AMChatGPT无法访问?本文提供多种实用解决方案!许多用户在日常使用ChatGPT时,可能会遇到无法访问或响应缓慢等问题。本文将根据不同情况,逐步指导您解决这些问题。 ChatGPT无法访问的原因及初步排查 首先,我们需要确定问题是出在OpenAI服务器端,还是用户自身网络或设备问题。 请按照以下步骤进行排查: 步骤1:检查OpenAI官方状态 访问OpenAI Status页面 (status.openai.com),查看ChatGPT服务是否正常运行。如果显示红色或黄色警报,则表示Open
 计算ASI的风险始于人类的思想May 14, 2025 am 05:02 AM
计算ASI的风险始于人类的思想May 14, 2025 am 05:02 AM2025年5月10日,麻省理工学院物理学家Max Tegmark告诉《卫报》,AI实验室应在释放人工超级智能之前模仿Oppenheimer的三位一体测试演算。 “我的评估是'康普顿常数',这是一场比赛的可能性
 易于理解的解释如何编写和撰写歌词和推荐工具May 14, 2025 am 05:01 AM
易于理解的解释如何编写和撰写歌词和推荐工具May 14, 2025 am 05:01 AMAI音乐创作技术日新月异,本文将以ChatGPT等AI模型为例,详细讲解如何利用AI辅助音乐创作,并辅以实际案例进行说明。我们将分别介绍如何通过SunoAI、Hugging Face上的AI jukebox以及Python的Music21库进行音乐创作。 通过这些技术,每个人都能轻松创作原创音乐。但需注意,AI生成内容的版权问题不容忽视,使用时务必谨慎。 让我们一起探索AI在音乐领域的无限可能! OpenAI最新AI代理“OpenAI Deep Research”介绍: [ChatGPT]Ope
 什么是chatgpt-4?对您可以做什么,定价以及与GPT-3.5的差异的详尽解释!May 14, 2025 am 05:00 AM
什么是chatgpt-4?对您可以做什么,定价以及与GPT-3.5的差异的详尽解释!May 14, 2025 am 05:00 AMChatGPT-4的出现,极大地拓展了AI应用的可能性。相较于GPT-3.5,ChatGPT-4有了显着提升,它具备强大的语境理解能力,还能识别和生成图像,堪称万能的AI助手。在提高商业效率、辅助创作等诸多领域,它都展现出巨大的潜力。然而,与此同时,我们也必须注意其使用上的注意事项。 本文将详细解读ChatGPT-4的特性,并介绍针对不同场景的有效使用方法。文中包含充分利用最新AI技术的技巧,敬请参考。 OpenAI发布的最新AI代理,“OpenAI Deep Research”详情请点击下方链
 解释如何使用chatgpt应用程序!日本支持和语音对话功能May 14, 2025 am 04:59 AM
解释如何使用chatgpt应用程序!日本支持和语音对话功能May 14, 2025 am 04:59 AMCHATGPT应用程序:与AI助手释放您的创造力!初学者指南 ChatGpt应用程序是一位创新的AI助手,可处理各种任务,包括写作,翻译和答案。它是一种具有无限可能性的工具,可用于创意活动和信息收集。 在本文中,我们将以一种易于理解的方式解释初学者,从如何安装chatgpt智能手机应用程序到语音输入功能和插件等应用程序所独有的功能,以及在使用该应用时要牢记的要点。我们还将仔细研究插件限制和设备对设备配置同步
 如何使用中文版Chatgpt?注册程序和费用的说明May 14, 2025 am 04:56 AM
如何使用中文版Chatgpt?注册程序和费用的说明May 14, 2025 am 04:56 AMChatGPT中文版:解锁中文AI对话新体验 ChatGPT风靡全球,您知道它也提供中文版本吗?这款强大的AI工具不仅支持日常对话,还能处理专业内容,并兼容简体中文和繁体中文。无论是中国地区的使用者,还是正在学习中文的朋友,都能从中受益。 本文将详细介绍ChatGPT中文版的使用方法,包括账户设置、中文提示词输入、过滤器的使用、以及不同套餐的选择,并分析潜在风险及应对策略。此外,我们还将对比ChatGPT中文版和其他中文AI工具,帮助您更好地了解其优势和应用场景。 OpenAI最新发布的AI智能
 5 AI代理神话,您需要停止相信May 14, 2025 am 04:54 AM
5 AI代理神话,您需要停止相信May 14, 2025 am 04:54 AM这些可以将其视为生成AI领域的下一个飞跃,这为我们提供了Chatgpt和其他大型语言模型聊天机器人。他们可以代表我们采取行动,而不是简单地回答问题或产生信息
 易于理解使用Chatgpt创建和管理多个帐户的非法性的解释May 14, 2025 am 04:50 AM
易于理解使用Chatgpt创建和管理多个帐户的非法性的解释May 14, 2025 am 04:50 AM使用chatgpt有效的多个帐户管理技术|关于如何使用商业和私人生活的详尽解释! Chatgpt在各种情况下都使用,但是有些人可能担心管理多个帐户。本文将详细解释如何为ChatGpt创建多个帐户,使用时该怎么做以及如何安全有效地操作它。我们还介绍了重要的一点,例如业务和私人使用差异,并遵守OpenAI的使用条款,并提供指南,以帮助您安全地利用多个帐户。 Openai


热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

Video Face Swap
使用我们完全免费的人工智能换脸工具轻松在任何视频中换脸!

热门文章
热工具

SublimeText3 英文版
推荐:为Win版本,支持代码提示!

MinGW - 适用于 Windows 的极简 GNU
这个项目正在迁移到osdn.net/projects/mingw的过程中,你可以继续在那里关注我们。MinGW:GNU编译器集合(GCC)的本地Windows移植版本,可自由分发的导入库和用于构建本地Windows应用程序的头文件;包括对MSVC运行时的扩展,以支持C99功能。MinGW的所有软件都可以在64位Windows平台上运行。

ZendStudio 13.5.1 Mac
功能强大的PHP集成开发环境

禅工作室 13.0.1
功能强大的PHP集成开发环境

记事本++7.3.1
好用且免费的代码编辑器

