
LLM抹布:创建一个AI驱动的文件阅读器助手

- Linda Hamilton原创
- 2025-03-04 10:40:11509浏览
简介
>很难与大型语言模型(LLM)至少每天一次相互作用。聊天机器人在这里留下来。他们在您的应用程序中,可以帮助您更好地写作,撰写电子邮件,阅读电子邮件……好吧,他们做了很多。
>
>我认为那不是不好的。实际上,我的看法是另一种方式 - 至少到目前为止。我为在我们的日常生活中使用AI的辩护并倡导,因为,让我们同意,这使一切变得更加容易。>我不必花时间仔细阅读文档来查找标点符号问题或类型。 AI为我做到了。我不会在每个星期一浪费时间写这篇后续电子邮件。 AI为我做到了。当我有AI时,我不需要阅读一份巨大而无聊的合同来总结我的主要收获和行动点!
>这些只是AI的一些伟大用途。如果您想了解更多LLM的用例以使我们的生活更轻松,那么我写了一本关于它们的书。
现在,作为数据科学家并看着技术方面的思考,并不是一切都那么明亮而有光泽。LLM非常适合适用于任何人或任何公司的几种普通用例。例如,编码,汇总或回答有关创建的一般内容的问题,直到培训截止日期为止。但是,当涉及到特定的业务应用程序,出于单一目的或没有截止日期的新事物时,那就是如果使用
>“”
> - 意思是,他们将不知道答案。因此,它将需要调整。 培训LLM型号可能需要数月和数百万美元。更糟糕的是,如果我们不调整并将模型调整为我们的目的,那么结果或幻觉就会不令人满意(当模型的响应鉴于我们的查询没有意义时)。
>那么,解决方案是什么?花大量的钱再训练模型包含我们的数据?
不是真的。那时,检索演示的一代(抹布)变得有用。
抹布是一个框架,它结合了从外部知识库中获取信息与大语言模型(LLMS)的框架。它可以帮助AI模型产生更准确和相关的响应。
让我们进一步了解接下来的抹布。什么是抹布?
>让我告诉你一个故事来说明这个概念。我喜欢电影。过去一段时间以来,我知道哪些电影正在争夺奥斯卡奖或最好的演员的最佳电影类别。我当然知道那年有哪个雕像。但是现在我对那个主题生锈了。如果您问我参加比赛的人,我将不知道。即使我试图回答您,我也会给您一个弱的回应。
>
因此,为了为您提供质量的响应,我将做其他所有人的工作:在线搜索信息,获取信息,然后将其交给您。我刚刚做的是与抹布相同的想法:我从外部数据库中获取了数据以给您一个答案。
我们使用> content Store 增强LLM时,>>检索数据到
增强>增强(增加)其知识库,这是行动中的抹布框架。 抹布就像创建一个内容存储,模型可以增强其知识并更准确地做出响应。
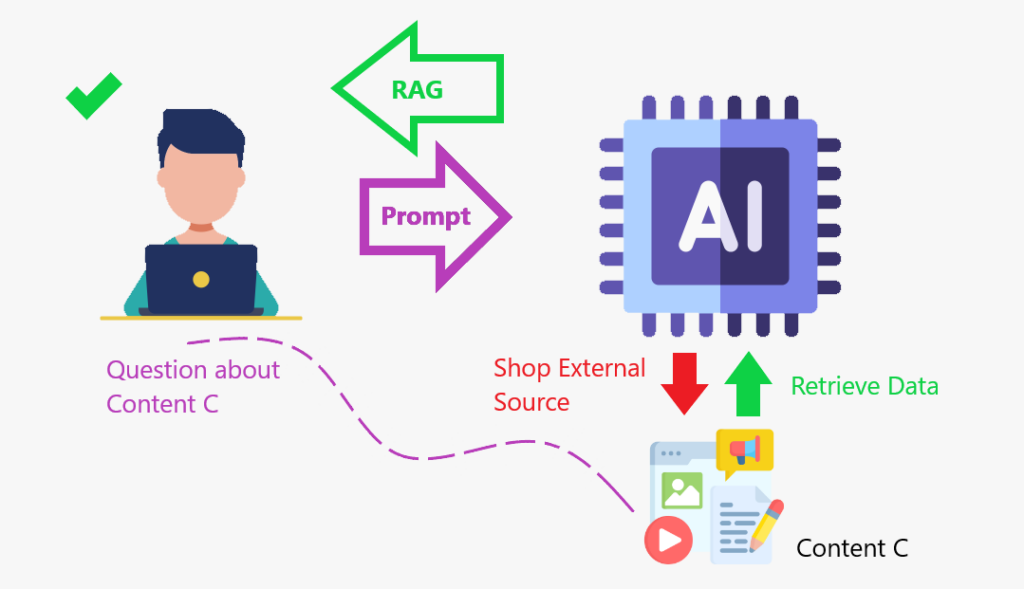 总结:
总结:
- >使用搜索算法查询外部数据源,例如数据库,知识库和网页。
- 预处理信息。 >
- 将预处理的信息合并到LLM中。 >
- 为什么使用抹布?
现在我们知道了抹布框架是什么
以下是一些好处:>
通过引用真实数据来提高事实准确性。
- rag可以帮助LLMS处理并巩固知识以创建更多相关的答案
- > rag可以帮助LLM访问其他知识库,例如内部组织数据
> rag可以帮助LLM创建更准确的域特异性内容 - 抹布可以帮助减少知识差距和AI幻觉
- 如前所述,我想说的是,使用RAG框架,我们为希望将其添加到知识库中的内容提供了内部搜索引擎。
- 好。所有这些都非常有趣。但是,让我们看看抹布的应用。我们将学习如何创建AI驱动的PDF阅读器助手。
- >项目
该应用程序使用简化作为前端。
> langchain,OpenAI的GPT-4型号和Faiss(Facebook AI相似性搜索),以进行文档检索和问题答案。
>
>让我们分解步骤以更好地理解:
- >加载PDF文件并将其分成几块文本。
- 这使得针对检索优化了数据
将块呈现给嵌入工具。
-
- 嵌入是用于以机器可以理解的方式捕获关系,相似性和含义的数据的数值向量表示。它们被广泛用于自然语言处理(NLP),推荐系统和搜索引擎。
- >最后,我们将其提供给LLM。
- 数据准备
内容存储
将采取一些步骤。因此,让我们从创建一个可以加载文件并将其将其拆分为文本块以进行有效检索的函数首先。。 接下来,我们将开始构建我们的简化应用程序,我们将在下一个脚本中使用该函数。
# Imports
from langchain_community.document_loaders import PyPDFLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
def load_document(pdf):
# Load a PDF
"""
Load a PDF and split it into chunks for efficient retrieval.
:param pdf: PDF file to load
:return: List of chunks of text
"""
loader = PyPDFLoader(pdf)
docs = loader.load()
# Instantiate Text Splitter with Chunk Size of 500 words and Overlap of 100 words so that context is not lost
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=100)
# Split into chunks for efficient retrieval
chunks = text_splitter.split_documents(docs)
# Return
return chunks> Web应用程序我们将开始在Python中导入必要的模块。其中大多数将来自Langchain套餐。
faiss用于文档检索; Openaiembeddings将文本块转换为数值得分,以通过LLM更好地相似性计算。 Chatopenai是使我们能够与Openai API互动的原因; create_retrieval_chain实际上是抹布所做的,可以使用该数据检索和增强LLM; create_stuff_documents_chain胶结模型和chatprompttemplate。
注意:您将需要
生成一个OpenAI键才能运行此脚本。如果这是您第一次创建帐户,那么您将获得一些免费的积分。但是,如果您有一段时间,则可能必须添加5美元的学分才能访问OpenAI的API。一种选择是使用拥抱的脸部嵌入。> 这个第一个代码段将创建应用程序标题,创建一个用于文件上传的框,然后准备要添加到load_document()function的文件。
# Imports from langchain_community.vectorstores import FAISS from langchain_openai import OpenAIEmbeddings from langchain.chains import create_retrieval_chain from langchain_openai import ChatOpenAI from langchain.chains.combine_documents import create_stuff_documents_chain from langchain_core.prompts import ChatPromptTemplate from scripts.secret import OPENAI_KEY from scripts.document_loader import load_document import streamlit as st机器比文本更好地理解数字,因此,最终,我们必须为模型提供一个数字数据库,在执行查询时可以比较和检查是否相似。在下一个代码中,嵌入对于创建vector_db的地方将很有用。
>
# Create a Streamlit app
st.title("AI-Powered Document Q&A")
# Load document to streamlit
uploaded_file = st.file_uploader("Upload a PDF file", type="pdf")
# If a file is uploaded, create the TextSplitter and vector database
if uploaded_file :
# Code to work around document loader from Streamlit and make it readable by langchain
temp_file = "./temp.pdf"
with open(temp_file, "wb") as file:
file.write(uploaded_file.getvalue())
file_name = uploaded_file.name
# Load document and split it into chunks for efficient retrieval.
chunks = load_document(temp_file)
# Message user that document is being processed with time emoji
st.write("Processing document... :watch:")接下来,我们创建一个在vector_db中导航的检索器对象。然后,我们将创建System_prompt,这是向LLM的一组指令,以了解如何回答,我们将创建一个提示模板,一旦我们从用户那里获得输入后,就可以将其添加到模型中。
# Generate embeddings # Embeddings are numerical vector representations of data, typically used to capture relationships, similarities, # and meanings in a way that machines can understand. They are widely used in Natural Language Processing (NLP), # recommender systems, and search engines. embeddings = OpenAIEmbeddings(openai_api_key=OPENAI_KEY, model="text-embedding-ada-002") # Can also use HuggingFaceEmbeddings # from langchain_huggingface.embeddings import HuggingFaceEmbeddings # embeddings = HuggingFaceEmbeddings(model_name="sentence-transformers/all-MiniLM-L6-v2") # Create vector database containing chunks and embeddings vector_db = FAISS.from_documents(chunks, embeddings)>
# Imports
from langchain_community.document_loaders import PyPDFLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
def load_document(pdf):
# Load a PDF
"""
Load a PDF and split it into chunks for efficient retrieval.
:param pdf: PDF file to load
:return: List of chunks of text
"""
loader = PyPDFLoader(pdf)
docs = loader.load()
# Instantiate Text Splitter with Chunk Size of 500 words and Overlap of 100 words so that context is not lost
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=100)
# Split into chunks for efficient retrieval
chunks = text_splitter.split_documents(docs)
# Return
return chunks
继续前进,我们创建了抹布框架的核心,粘贴了猎犬对象和提示。该对象添加了来自数据源(例如,矢量数据库)的相关文档,并准备好使用LLM处理以生成响应。
# Imports from langchain_community.vectorstores import FAISS from langchain_openai import OpenAIEmbeddings from langchain.chains import create_retrieval_chain from langchain_openai import ChatOpenAI from langchain.chains.combine_documents import create_stuff_documents_chain from langchain_core.prompts import ChatPromptTemplate from scripts.secret import OPENAI_KEY from scripts.document_loader import load_document import streamlit as st
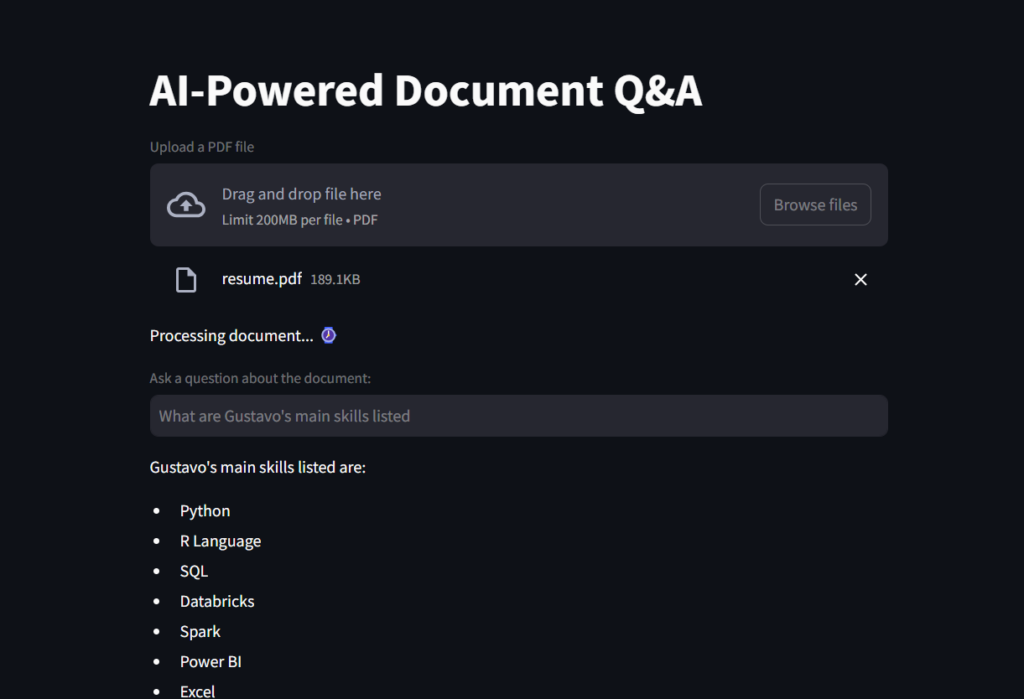
这是结果的屏幕截图。
# Create a Streamlit app
st.title("AI-Powered Document Q&A")
# Load document to streamlit
uploaded_file = st.file_uploader("Upload a PDF file", type="pdf")
# If a file is uploaded, create the TextSplitter and vector database
if uploaded_file :
# Code to work around document loader from Streamlit and make it readable by langchain
temp_file = "./temp.pdf"
with open(temp_file, "wb") as file:
file.write(uploaded_file.getvalue())
file_name = uploaded_file.name
# Load document and split it into chunks for efficient retrieval.
chunks = load_document(temp_file)
# Message user that document is being processed with time emoji
st.write("Processing document... :watch:")
>这是您可以看到文件读取器AI助手的GIF!
>
在您去之前 在这个项目中,我们了解了抹布框架是什么,以及它如何帮助LLM表现更好,并且在特定的知识方面表现良好。
> AI可以从指令手册,公司的数据库,某些财务文件或合同的知识中提供动力,然后进行微调以准确地响应特定领域的内容查询。知识库是用内容存储的增强 的。
的。>
回顾一下,这就是框架的工作方式:>
>1️⃣用户查询→输入文本。
2️⃣检索相关文档
→搜索知识库(例如,数据库,矢量存储)。3️⃣增强上下文→检索的文档被添加到输入中。
4️⃣生成响应→a llm处理组合输入并产生答案。
github存储库https://github.com/gurezende/basic-rag 关于我的
如果您喜欢此内容并想了解有关我的工作的更多信息,这是我的网站,您也可以在其中找到我所有的联系人。>
https://gustavorsantos.me参考
> https://cloud.google.com/use-cases/retrieval-aigmented-generation
https://www.ibm.com/think/topics/retrieval-augmented-generate
https://youtu.be/t-d1ofcdw1m?si=g0uwfh5-wznmu0nw
https://python.langchain.com/docs/introduction
https://www.geeksforgeeks.org/how-to-get-get-your-own-own-openai-api-key
以上是LLM抹布:创建一个AI驱动的文件阅读器助手的详细内容。更多信息请关注PHP中文网其他相关文章!