


> Neurips 2024聚光灯:使用选择性语言建模(SLM)
进行优化语言模型>最近,我提出了一份来自2024年Neurips的引人入胜的论文,“并非所有的标记都是您在当地阅读组中所需的。” 本文解决了一个令人惊讶的简单但有影响力的问题:在训练语言模型期间,每个令牌是否需要下一步的预测? >标准方法涉及大量的网络绑带数据集和普遍应用因果语言建模(CLM)。 本文提出了假设的挑战,提出某些令牌阻碍了学习过程而不是帮助。 作者表明,将培训集中在“有用”代币上可以显着提高数据效率和下游任务绩效。 这篇文章总结了他们的核心思想和关键的实验发现。
>
问题:噪声和效率低下的学习> >大型网络中心不可避免地包含噪音。虽然文档级过滤有所帮助,但噪声通常位于各个文档中。 这些嘈杂的令牌浪费了计算资源,并可能使模型混淆。 作者分析了令牌级学习动力学,基于其跨渗透损失轨迹对令牌进行分类:
l→l(低至低):
迅速学习,提供最小的进一步好处。- h→l(高到低):最初很困难,但最终学会了;代表宝贵的学习机会。
- h→h(高到高):始终困难,通常是由于固有的不可预测性(良好的不确定性)。>
- l→H(低至高):最初学会,但后来成为问题,可能是由于上下文变化或噪声。 他们的分析表明,只有一小部分代币提供有意义的学习信号。 >
- 解决方案:选择性语言建模(SLM)> 建议的解决方案,选择性语言建模(SLM),提供了一种更具针对性的方法:
参考模型(RM)训练:
 多余的损失计算:
多余的损失计算:
-
> 选择性反向传播:
进行反向传播。这动态地将培训集中在最有价值的代币上。在所有令牌上都执行完整的正向通行证,但是仅对多余损失最高的代币的顶部 k% >
实验结果:显着增长
SLM在各种实验中都具有显着优势:

在
自我引用:
即使是来自RAW语料库的快速训练的RM也提供了2-3%的准确性提升,而使用的代币降低了30-40%。>结论和未来工作
>以上是超越因果语言建模的详细内容。更多信息请关注PHP中文网其他相关文章!

 AV字节:Openai' apple apple and visual ai等 - 分析vidhyaApr 12, 2025 am 09:38 AM
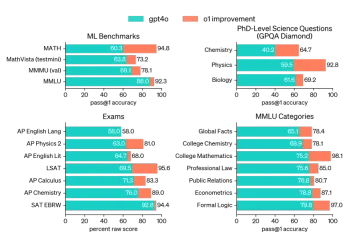
AV字节:Openai' apple apple and visual ai等 - 分析vidhyaApr 12, 2025 am 09:38 AM介绍 本周,人工智能(AI)世界上充满了重大更新。从OpenAI的O1模型展示高级推理到苹果的开创性视觉智能技术,Tech
 如何监视生产级代理抹布管道?Apr 12, 2025 am 09:34 AM
如何监视生产级代理抹布管道?Apr 12, 2025 am 09:34 AM介绍 2022年,Chatgpt的推出彻底改变了技术和非技术行业,从而使个人和组织具有生成性AI的能力。在2023年,努力集中在利用大语言模式
 如何使用Star模式优化数据仓库?Apr 12, 2025 am 09:33 AM
如何使用Star模式优化数据仓库?Apr 12, 2025 am 09:33 AMStar模式是用于数据仓库和商业智能的高效数据库设计。它将数据组织到链接到周围尺寸表的中心事实表中。这种类似恒星的结构简化了复杂Q
 代理抹布系统如何改变技术?Apr 12, 2025 am 09:21 AM
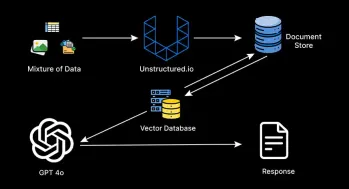
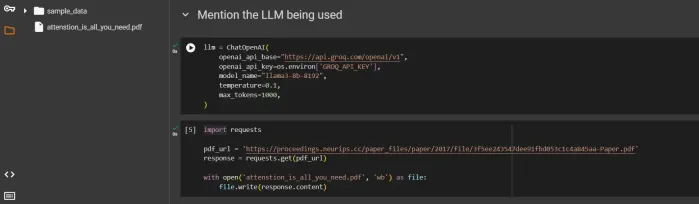
代理抹布系统如何改变技术?Apr 12, 2025 am 09:21 AM介绍 人工智能进入了一个新时代。模型将基于预定义的规则输出信息的日子已经一去不复返了。当今AI中的尖端方法围绕抹布(检索-Aigmente)
 SQL自动生成查询助手Apr 12, 2025 am 09:13 AM
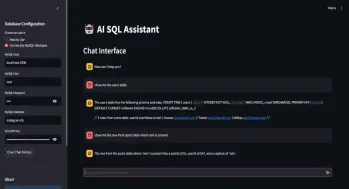
SQL自动生成查询助手Apr 12, 2025 am 09:13 AM您是否希望您可以简单地与数据库交谈,用简单的语言提出问题,并在不编写复杂的SQL查询或通过电子表格进行分类的情况下获得即时答案?使用Langchain的SQL工具包,Groq A
 阅读AI索引2025:AI是您的朋友,敌人还是副驾驶?Apr 11, 2025 pm 12:13 PM
阅读AI索引2025:AI是您的朋友,敌人还是副驾驶?Apr 11, 2025 pm 12:13 PM斯坦福大学以人为本人工智能研究所发布的《2025年人工智能指数报告》对正在进行的人工智能革命进行了很好的概述。让我们用四个简单的概念来解读它:认知(了解正在发生的事情)、欣赏(看到好处)、接纳(面对挑战)和责任(弄清我们的责任)。 认知:人工智能无处不在,并且发展迅速 我们需要敏锐地意识到人工智能发展和传播的速度有多快。人工智能系统正在不断改进,在数学和复杂思维测试中取得了优异的成绩,而就在一年前,它们还在这些测试中惨败。想象一下,人工智能解决复杂的编码问题或研究生水平的科学问题——自2023年
 开始使用Meta Llama 3.2 -Analytics VidhyaApr 11, 2025 pm 12:04 PM
开始使用Meta Llama 3.2 -Analytics VidhyaApr 11, 2025 pm 12:04 PMMeta的Llama 3.2:多模式和移动AI的飞跃 Meta最近公布了Llama 3.2,这是AI的重大进步,具有强大的视觉功能和针对移动设备优化的轻量级文本模型。 以成功为基础


热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

Atom编辑器mac版下载
最流行的的开源编辑器

螳螂BT
Mantis是一个易于部署的基于Web的缺陷跟踪工具,用于帮助产品缺陷跟踪。它需要PHP、MySQL和一个Web服务器。请查看我们的演示和托管服务。

ZendStudio 13.5.1 Mac
功能强大的PHP集成开发环境

EditPlus 中文破解版
体积小,语法高亮,不支持代码提示功能

SecLists
SecLists是最终安全测试人员的伙伴。它是一个包含各种类型列表的集合,这些列表在安全评估过程中经常使用,都在一个地方。SecLists通过方便地提供安全测试人员可能需要的所有列表,帮助提高安全测试的效率和生产力。列表类型包括用户名、密码、URL、模糊测试有效载荷、敏感数据模式、Web shell等等。测试人员只需将此存储库拉到新的测试机上,他就可以访问到所需的每种类型的列表。

