



网络抓取是为检索增强生成 (RAG) 应用程序收集内容的常用方法。然而,解析网页内容可能具有挑战性。
Mozilla 的开源 Readability.js 库提供了一种方便的解决方案,用于仅提取网页的基本部分。 让我们探讨一下它将其集成到 RAG 应用程序的数据摄取管道中。
从网页中提取非结构化数据
网页是非结构化数据的丰富来源,非常适合 RAG 应用程序。 然而,网页通常包含不相关的信息,例如页眉、侧边栏和页脚。虽然这些额外内容对于浏览很有用,但会分散页面的主要主题。
为了获得最佳的 RAG 数据,必须删除不相关的内容。 虽然像 Cheerio 这样的工具可以根据网站的已知结构解析 HTML,但这种方法对于抓取不同的网站布局效率很低。需要一种强大的方法来仅提取相关内容。
利用阅读器视图功能
大多数浏览器都包含一个阅读器视图,该视图会删除除文章标题和内容之外的所有内容。下图说明了应用于 DataStax 博客文章的标准浏览模式和阅读器模式之间的区别:

Mozilla 提供 Readability.js(Firefox 阅读器模式背后的库)作为独立的开源模块。这使我们能够将 Readability.js 集成到数据管道中,以删除不相关的内容并改善抓取结果。
使用 Node.js 和 Readability.js 抓取数据
让我们举例说明如何从之前关于在 Node.js 中创建矢量嵌入的博客文章中抓取文章内容。 以下 JavaScript 代码检索页面的 HTML:
const html = await fetch( "https://www.datastax.com/blog/how-to-create-vector-embeddings-in-node-js" ).then((res) => res.text()); console.log(html);
这包括所有 HTML,包括导航、页脚和网站上常见的其他元素。
或者,您可以使用 Cheerio 来选择特定元素:
npm install cheerio
import * as cheerio from "cheerio";
const html = await fetch(
"https://www.datastax.com/blog/how-to-create-vector-embeddings-in-node-js"
).then((res) => res.text());
const $ = cheerio.load(html);
console.log($("h1").text(), "\n");
console.log($("section#blog-content > div:first-child").text());
这会产生标题和文章文本。 然而,这种方法依赖于了解 HTML 结构,这并不总是可行。
更好的方法是安装 Readability.js 和 jsdom:
npm install @mozilla/readability jsdom
Readability.js 在浏览器环境中运行,需要 jsdom 在 Node.js 中模拟它。 我们可以将加载的 HTML 转换为文档并使用 Readability.js 解析内容:
import { Readability } from "@mozilla/readability";
import { JSDOM } from "jsdom";
const url = "https://www.datastax.com/blog/how-to-create-vector-embeddings-in-node-js";
const html = await fetch(url).then((res) => res.text());
const doc = new JSDOM(html, { url });
const reader = new Readability(doc.window.document);
const article = reader.parse();
console.log(article);
article 对象包含各种解析元素:
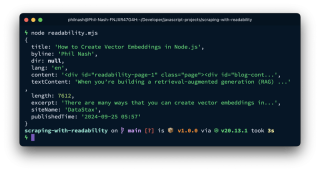
这包括标题、作者、摘录、出版时间以及 HTML (content) 和纯文本 (textContent)。 textContent 已准备好进行分块、嵌入和存储,而 content 保留链接和图像以供进一步处理。
isProbablyReaderable 函数有助于确定文档是否适合 Readability.js:
const html = await fetch( "https://www.datastax.com/blog/how-to-create-vector-embeddings-in-node-js" ).then((res) => res.text()); console.log(html);
不合适的页面应被标记以供审核。
将可读性与 LangChain.js 集成
Readability.js 与 LangChain.js 无缝集成。以下示例使用 LangChain.js 加载页面,使用 MozillaReadabilityTransformer 提取内容,使用 RecursiveCharacterTextSplitter 分割文本,使用 OpenAI 创建嵌入,并将数据存储在 Astra DB 中。
所需的依赖项:
npm install cheerio
您需要 Astra DB 凭据(ASTRA_DB_APPLICATION_TOKEN、ASTRA_DB_API_ENDPOINT)和 OpenAI API 密钥 (OPENAI_API_KEY) 作为环境变量。
导入必要的模块:
import * as cheerio from "cheerio";
const html = await fetch(
"https://www.datastax.com/blog/how-to-create-vector-embeddings-in-node-js"
).then((res) => res.text());
const $ = cheerio.load(html);
console.log($("h1").text(), "\n");
console.log($("section#blog-content > div:first-child").text());
初始化组件:
npm install @mozilla/readability jsdom
加载、转换、分割、嵌入和存储文档:
import { Readability } from "@mozilla/readability";
import { JSDOM } from "jsdom";
const url = "https://www.datastax.com/blog/how-to-create-vector-embeddings-in-node-js";
const html = await fetch(url).then((res) => res.text());
const doc = new JSDOM(html, { url });
const reader = new Readability(doc.window.document);
const article = reader.parse();
console.log(article);
通过 Readability.js 提高网页抓取准确性
Readability.js 是一个为 Firefox 阅读器模式提供支持的强大库,可以有效地从网页中提取相关数据,从而提高 RAG 数据质量。 可以直接使用,也可以通过LangChain.js的MozillaReadabilityTransformer.
这只是摄取管道的初始阶段。 分块、嵌入和 Astra DB 存储是构建 RAG 应用程序的后续步骤。
您是否使用其他方法来清理 RAG 应用程序中的网页内容? 分享你的技巧!
以上是使用 Readability.js 清理 HTML 内容以进行检索增强生成的详细内容。更多信息请关注PHP中文网其他相关文章!

 Python vs. JavaScript:开发人员的比较分析May 09, 2025 am 12:22 AM
Python vs. JavaScript:开发人员的比较分析May 09, 2025 am 12:22 AMPython和JavaScript的主要区别在于类型系统和应用场景。1.Python使用动态类型,适合科学计算和数据分析。2.JavaScript采用弱类型,广泛用于前端和全栈开发。两者在异步编程和性能优化上各有优势,选择时应根据项目需求决定。
 Python vs. JavaScript:选择合适的工具May 08, 2025 am 12:10 AM
Python vs. JavaScript:选择合适的工具May 08, 2025 am 12:10 AM选择Python还是JavaScript取决于项目类型:1)数据科学和自动化任务选择Python;2)前端和全栈开发选择JavaScript。Python因其在数据处理和自动化方面的强大库而备受青睐,而JavaScript则因其在网页交互和全栈开发中的优势而不可或缺。
 Python和JavaScript:了解每个的优势May 06, 2025 am 12:15 AM
Python和JavaScript:了解每个的优势May 06, 2025 am 12:15 AMPython和JavaScript各有优势,选择取决于项目需求和个人偏好。1.Python易学,语法简洁,适用于数据科学和后端开发,但执行速度较慢。2.JavaScript在前端开发中无处不在,异步编程能力强,Node.js使其适用于全栈开发,但语法可能复杂且易出错。
 JavaScript的核心:它是在C还是C上构建的?May 05, 2025 am 12:07 AM
JavaScript的核心:它是在C还是C上构建的?May 05, 2025 am 12:07 AMjavascriptisnotbuiltoncorc; saninterpretedlanguagethatrunsonenginesoftenwritteninc.1)javascriptwasdesignedAsalightweight,解释edganguageforwebbrowsers.2)Enginesevolvedfromsimpleterterterpretpreterterterpretertestojitcompilerers,典型地提示。
 JavaScript应用程序:从前端到后端May 04, 2025 am 12:12 AM
JavaScript应用程序:从前端到后端May 04, 2025 am 12:12 AMJavaScript可用于前端和后端开发。前端通过DOM操作增强用户体验,后端通过Node.js处理服务器任务。1.前端示例:改变网页文本内容。2.后端示例:创建Node.js服务器。
 Python vs. JavaScript:您应该学到哪种语言?May 03, 2025 am 12:10 AM
Python vs. JavaScript:您应该学到哪种语言?May 03, 2025 am 12:10 AM选择Python还是JavaScript应基于职业发展、学习曲线和生态系统:1)职业发展:Python适合数据科学和后端开发,JavaScript适合前端和全栈开发。2)学习曲线:Python语法简洁,适合初学者;JavaScript语法灵活。3)生态系统:Python有丰富的科学计算库,JavaScript有强大的前端框架。
 JavaScript框架:为现代网络开发提供动力May 02, 2025 am 12:04 AM
JavaScript框架:为现代网络开发提供动力May 02, 2025 am 12:04 AMJavaScript框架的强大之处在于简化开发、提升用户体验和应用性能。选择框架时应考虑:1.项目规模和复杂度,2.团队经验,3.生态系统和社区支持。
 JavaScript,C和浏览器之间的关系May 01, 2025 am 12:06 AM
JavaScript,C和浏览器之间的关系May 01, 2025 am 12:06 AM引言我知道你可能会觉得奇怪,JavaScript、C 和浏览器之间到底有什么关系?它们之间看似毫无关联,但实际上,它们在现代网络开发中扮演着非常重要的角色。今天我们就来深入探讨一下这三者之间的紧密联系。通过这篇文章,你将了解到JavaScript如何在浏览器中运行,C 在浏览器引擎中的作用,以及它们如何共同推动网页的渲染和交互。JavaScript与浏览器的关系我们都知道,JavaScript是前端开发的核心语言,它直接在浏览器中运行,让网页变得生动有趣。你是否曾经想过,为什么JavaScr


热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

Video Face Swap
使用我们完全免费的人工智能换脸工具轻松在任何视频中换脸!

热门文章
热工具

VSCode Windows 64位 下载
微软推出的免费、功能强大的一款IDE编辑器

记事本++7.3.1
好用且免费的代码编辑器

WebStorm Mac版
好用的JavaScript开发工具

SublimeText3汉化版
中文版,非常好用

适用于 Eclipse 的 SAP NetWeaver 服务器适配器
将Eclipse与SAP NetWeaver应用服务器集成。

