


如果您正在步入大数据世界,您可能听说过 Apache Spark,这是一个强大的分布式计算系统。 PySpark 是 Apache Spark 的 Python 库,因其速度、可扩展性和易用性的结合而深受数据爱好者的喜爱。但在本地计算机上设置它一开始可能会感觉有点吓人。
不用担心 - 本文将引导您完成整个过程,解决常见问题并使整个过程尽可能简单。
什么是 PySpark,您为什么要关心?
在开始安装之前,我们先来了解一下 PySpark 是什么。 PySpark 允许您使用 Python 来利用 Apache Spark 的强大计算能力。无论您是分析 TB 级数据、构建机器学习模型还是运行 ETL(Extract、Transform、Load)管道,PySpark 都可以让您使用数据比以往更加高效。
现在您已经了解了 PySpark,让我们来完成安装过程。
第 1 步:确保您的系统满足要求
PySpark 在各种计算机上运行,包括 Windows、macOS 和 Linux。以下是成功安装所需的内容:
- Java 开发套件 (JDK):PySpark 需要 Java(建议使用版本 8 或 11)。
- Python:确保您有 Python 3.6 或更高版本。
- Apache Spark Binary:您将在安装过程中下载它。
要检查您的系统准备情况:
- 打开终端或命令提示符。
- 输入 java -version 和 python —version 以确认 Java 和 Python 安装。
如果您没有安装 Java 或 Python,请按照以下步骤操作:
- 对于Java:从Oracle官网下载。
- 对于 Python:访问 Python 的下载页面。
第 2 步:安装 Java
Java 是 Apache Spark 的支柱。安装方法:
1.下载 Java:访问 Java SE 开发工具包下载页面。选择适合您的操作系统的版本。
2.安装 Java:运行安装程序并按照提示操作。在 Windows 上,您需要设置 JAVA_HOME 环境变量。为此:
- 复制路径变量,进入您机器上的本地磁盘,选择program files,查找java文件夹打开它你会看到jdk-17(你自己的版本可能不是 17)。打开它,你将能够看到你的路径并复制如下
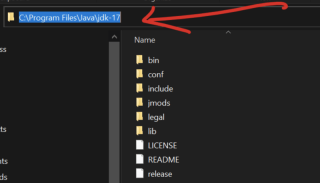
在 Windows 搜索栏中搜索 环境变量。
在系统变量下,单击新建并将变量名称设置为JAVA_HOME,并将值设置为您在上面复制的Java安装路径(例如,C:Program文件Javajdk-17)。
3.验证安装:打开终端或命令提示符并输入java-version。
第 3 步:安装 Apache Spark
1.下载 Spark:访问 Apache Spark 网站并选择适合您需求的版本。使用 Hadoop 的预构建包(与 Spark 的常见配对)。
2.解压文件:
- 在 Windows 上,使用 WinRAR 或 7-Zip 等工具来提取文件。
- 在 macOS/Linux 上,使用命令 tar -xvf Spark-.tgz
3.设置环境变量:
- 对于 Windows:将 Spark 的 bin 目录添加到系统的 PATH 变量中。
- 对于 macOS/Linux:将以下行添加到 .bashrc 或 .zshrc 文件:
export SPARK_HOME=/path/to/spark export PATH=$SPARK_HOME/bin:$PATH
4.验证安装:打开终端并输入spark-shell。您应该看到 Spark 的交互式 shell 启动。
第 4 步:安装 Hadoop(可选但推荐)
虽然 Spark 并不严格要求 Hadoop,但许多用户安装它是为了支持 HDFS(Hadoop 分布式文件系统)。要安装 Hadoop:
- 从 Apache Hadoop 网站下载 Hadoop 二进制文件。
- 解压文件并设置 HADOOP_HOME 环境变量。
第5步:通过pip安装PySpark
使用 Python 的 pip 工具安装 PySpark 变得轻而易举。只需运行:
pip install pyspark
要进行验证,请打开 Python shell 并输入:
pip install pysparkark.__version__)
如果您看到版本号,恭喜! PySpark 已安装?
第 6 步:测试您的 PySpark 安装
乐趣就从这里开始。让我们确保一切顺利:
创建一个简单的脚本:
打开文本编辑器并粘贴以下代码:
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName("PySparkTest").getOrCreate()
data = [("Alice", 25), ("Bob", 30), ("Cathy", 29)]
columns = ["Name", "Age"]
df = spark.createDataFrame(data, columns)
df.show()
另存为 test_pyspark.py
运行脚本:
在终端中,导航到脚本的目录并输入:
export SPARK_HOME=/path/to/spark export PATH=$SPARK_HOME/bin:$PATH
您应该看到一个格式整齐的表格,其中显示姓名和年龄。
常见问题故障排除
即使有最好的指导,也会出现问题。以下是一些常见问题和解决方案:
问题:java.lang.NoClassDefFoundError
解决方案:仔细检查您的 JAVA_HOME 和 PATH 变量。问题:PySpark安装成功,但测试脚本失败。
解决方案:确保您使用的是正确的 Python 版本。有时,虚拟环境可能会导致冲突。问题:spark-shell 命令不起作用。
解决方案:验证 Spark 目录是否已正确添加到您的 PATH 中。
为什么在本地使用 PySpark?
许多用户想知道为什么要在本地计算机上安装 PySpark,因为 PySpark 主要用于分布式系统。原因如下:
- 学习:无需集群即可实验和学习 Spark 概念。
- 原型设计:在将小数据作业部署到更大的环境之前在本地测试它们。
- 方便:轻松调试问题并开发应用程序。
提高您的 PySpark 生产力
要充分利用 PySpark,请考虑以下提示:
设置虚拟环境:使用 venv 或 conda 等工具来隔离 PySpark 安装。
与 IDE 集成:PyCharm 和 Jupyter Notebook 等工具使 PySpark 开发更具交互性。
利用 PySpark 文档:访问 Apache Spark 的文档以获取深入指导。
参与 PySpark 社区
陷入困境是正常的,尤其是使用 PySpark 这样强大的工具时。与充满活力的 PySpark 社区联系以寻求帮助:
加入论坛:像 Stack Overflow 这样的网站有专用的 Spark 标签。
参加聚会:Spark 和 Python 社区经常举办可供您学习和交流的活动。
关注博客:许多数据专业人士在线分享他们的经验和教程。
结论
在本地计算机上安装 PySpark 起初可能看起来令人畏惧,但遵循这些步骤使其易于管理且有益。无论您是刚刚开始数据之旅还是提高技能,PySpark 都能为您提供解决现实数据问题的工具。
PySpark 是 Apache Spark 的 Python API,是数据分析和处理的游戏规则改变者。虽然它的潜力巨大,但在本地计算机上设置它可能会让人感到具有挑战性。本文逐步分解该过程,涵盖从安装 Java 和下载 Spark 到使用简单脚本测试您的设置的所有内容。
通过在本地安装 PySpark,您可以构建数据工作流原型、学习 Spark 的功能并测试小型项目,而无需完整集群。
以上是如何在本地计算机上安装 PySpark的详细内容。更多信息请关注PHP中文网其他相关文章!

 Python:编译器还是解释器?May 13, 2025 am 12:10 AM
Python:编译器还是解释器?May 13, 2025 am 12:10 AMPython是解释型语言,但也包含编译过程。1)Python代码先编译成字节码。2)字节码由Python虚拟机解释执行。3)这种混合机制使Python既灵活又高效,但执行速度不如完全编译型语言。
 python用于循环与循环时:何时使用哪个?May 13, 2025 am 12:07 AM
python用于循环与循环时:何时使用哪个?May 13, 2025 am 12:07 AMuseeAforloopWheniteratingOveraseQuenceOrforAspecificnumberoftimes; useAwhiLeLoopWhenconTinuingUntilAcIntiment.ForloopSareIdeAlforkNownsences,而WhileLeleLeleLeleLoopSituationSituationSituationsItuationSuationSituationswithUndEtermentersitations。
 Python循环:最常见的错误May 13, 2025 am 12:07 AM
Python循环:最常见的错误May 13, 2025 am 12:07 AMpythonloopscanleadtoerrorslikeinfiniteloops,modifyingListsDuringteritation,逐个偏置,零indexingissues,andnestedloopineflinefficiencies
 对于循环和python中的循环时:每个循环的优点是什么?May 13, 2025 am 12:01 AM
对于循环和python中的循环时:每个循环的优点是什么?May 13, 2025 am 12:01 AMforloopsareadvantageousforknowniterations and sequests,供应模拟性和可读性;而LileLoopSareIdealFordyNamicConcitionSandunknowniterations,提供ControloperRoverTermination.1)forloopsareperfectForeTectForeTerToratingOrtratingRiteratingOrtratingRitterlistlistslists,callings conspass,calplace,cal,ofstrings ofstrings,orstrings,orstrings,orstrings ofcces
 Python:深入研究汇编和解释May 12, 2025 am 12:14 AM
Python:深入研究汇编和解释May 12, 2025 am 12:14 AMpythonisehybridmodelofcompilationand interpretation:1)thepythoninterspretercompilesourcececodeintoplatform- interpententbybytecode.2)thepytythonvirtualmachine(pvm)thenexecuteCutestestestesteSteSteSteSteSteSthisByTecode,BelancingEaseofuseWithPerformance。
 Python是一种解释或编译语言,为什么重要?May 12, 2025 am 12:09 AM
Python是一种解释或编译语言,为什么重要?May 12, 2025 am 12:09 AMpythonisbothinterpretedAndCompiled.1)它的compiledTobyTecodeForportabilityAcrosplatforms.2)bytecodeisthenInterpreted,允许fordingfordforderynamictynamictymictymictymictyandrapiddefupment,尽管Ititmaybeslowerthananeflowerthanancompiledcompiledlanguages。
 对于python中的循环时循环与循环:解释了关键差异May 12, 2025 am 12:08 AM
对于python中的循环时循环与循环:解释了关键差异May 12, 2025 am 12:08 AM在您的知识之际,而foroopsareideal insinAdvance中,而WhileLoopSareBetterForsituations则youneedtoloopuntilaconditionismet
 循环时:实用指南May 12, 2025 am 12:07 AM
循环时:实用指南May 12, 2025 am 12:07 AMForboopSareSusedwhenthentheneMberofiterationsiskNownInAdvance,而WhileLoopSareSareDestrationsDepportonAcondition.1)ForloopSareIdealForiteratingOverSequencesLikelistSorarrays.2)whileLeleLooleSuitableApeableableableableableableforscenarioscenarioswhereTheLeTheLeTheLeTeLoopContinusunuesuntilaspecificiccificcificCondond


热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

Video Face Swap
使用我们完全免费的人工智能换脸工具轻松在任何视频中换脸!

热门文章
热工具

ZendStudio 13.5.1 Mac
功能强大的PHP集成开发环境

SecLists
SecLists是最终安全测试人员的伙伴。它是一个包含各种类型列表的集合,这些列表在安全评估过程中经常使用,都在一个地方。SecLists通过方便地提供安全测试人员可能需要的所有列表,帮助提高安全测试的效率和生产力。列表类型包括用户名、密码、URL、模糊测试有效载荷、敏感数据模式、Web shell等等。测试人员只需将此存储库拉到新的测试机上,他就可以访问到所需的每种类型的列表。

Dreamweaver Mac版
视觉化网页开发工具

Dreamweaver CS6
视觉化网页开发工具

SublimeText3汉化版
中文版,非常好用

