
利用 OpenAI Assistant 在 PHP/Symfony 7 中进行命名实体识别

- Patricia Arquette原创
- 2024-12-26 02:44:13868浏览
将大型语言模型集成到现实世界的产品后端是最新的创新战场。但与所有科技趋势一样,真正的赢家并不是那些急于了解一切的人。相反,它是关于暂停、反思和做出明智的决定。
尽管人工智能比以往任何时候都更容易获得,但认为这是一项微不足道的任务是一个很大的错误。该领域仍处于起步阶段,几乎技术和商业领域的每个人都在试图弄清楚如何理解它。互联网上充斥着可靠的信息和误导性的炒作。
不管你信不信,你不需要对你听到的每一条人工智能八卦都热衷起来。退后一步,深思熟虑地对待它。
如果您是 PHP 开发人员或使用 PHP 代码库,人工智能可能会感觉像是一个陌生的概念。类、接口、消息队列和框架似乎与 NLP、微调、随机梯度下降、LoRA、RAG 以及所有这些术语截然不同。我得到它。为了系统地学习这些概念,就像软件工程中的任何东西一样,我们需要时间和良好的实践。
但是人工智能、机器学习和数据科学不是 Python 或 R 程序员的领域吗?你说对了一部分。大多数基础机器学习都是用 Python 完成的。老实说,学习 Python 是一种乐趣——它用途广泛,可以应用于无数有趣的项目。从构建和训练语言模型到通过 API 部署它,Python 都能满足您的需求。
但是让我们回到 PHP。
别担心——作为一名普通软件工程师,你不会被淘汰。恰恰相反。随着我们越来越期望了解容器化、CI/CD、系统工程和云基础设施等相关领域,人工智能正迅速成为我们工具包中的另一项基本技能。现在就是开始学习的最佳时机。
也就是说,我不建议一头扎进从头开始构建神经网络(除非你真的想这么做)。很容易不知所措。相反,让我向您展示人工智能实验的实用起点。
您能期待什么?
以下是我们将在本指南中介绍的内容:
异步 AI 工作流程
我将向您展示如何使用消息队列实现 AI 工作流程 - 无论是 RabbitMQ、Amazon SQS 还是您首选的代理。
生产就绪解决方案
您将看到部署在生产系统中的解决方案的真实示例,该解决方案通过 AI 解决基本业务需求
Symfony 集成
该解决方案完全在 Symfony PHP 框架内实现。
OpenAI 工具
我们将使用 OpenAI PHP 库和最新的 OpenAI Assistants 2.0。
我们将涵盖哪些主题?
数据集结构
如何构建用于训练和评估 AI 模型的数据集。微调 OpenAI 模型
了解准备合适的 .jsonl 文件并根据您的特定业务用例微调 GPT-4o-mini 模型或 GPT 系列中的另一个模型。创建并测试 OpenAI Assistant 2.0
了解如何设置 OpenAI Assistant 并在 OpenAI Playground 中对其进行测试。知识库
深入了解知识库的概念:为什么 GPT 不知道一切,以及如何为其提供正确的上下文以显着提高准确性。PHP 与 Symfony 集成
了解如何将 AI 代理与 Symfony 应用程序无缝连接。
有兴趣吗?让我们滚吧。
OpenAI PHP 项目的先决条件
- 开设AI账户 您需要在 openai.com 上拥有一个帐户。
- 可选:权重和偏差帐户 在 wandb.ai 上设置帐户是可选的,但强烈建议您这样做。它是跟踪 AI 实验和可视化结果的出色工具。
定义问题
让我们深入探讨我们正在解决的问题。
从本质上讲,我们正在处理代表某种事物的文本块——在我们的例子中是一个地址。目标是将其组件分类到预定义的组中。
因此,当用户向我们发送地址时,我们的目标是返回一个 JSON 结构,该结构将地址分段。例如:
{
"street": "Strada Grui",
"block": "Bloc 7",
"staircase": "Scara A",
"apartment": "Apartament 6",
"city": "Zărnești"
}
为什么这很重要?
嗯,这些地址是由人们(我们的客户)输入的,而且它们通常不一致。这就是我们需要结构化、解析数据的原因:
- 一致的格式 确保地址遵循无缝处理的标准格式。
- 地址验证(可选) 允许我们验证地址是否有效或存在。
为了实现这一目标,我们将地址分解为预定义的组,例如“街道”、“房屋”、“邮政编码”等,然后将其重新组合成所需的序列。
为什么不使用正则表达式?
乍一看,这听起来很简单。如果我们对新客户强制执行格式设置或知道他们通常以特定方式编写地址,则正则表达式可能看起来是一个合理的解决方案。
但是,让我们考虑一下罗马尼亚地址的示例:
STRADA GRUI, BLOC 7, SCARA A, APARTAMENT 6, ZĂRNEŞTI BD. 21 DECEMBRIE 1989 nr. 93 ap. 50, CLUJ, 400124
罗马尼亚地址通常很复杂,没有特定的顺序书写,并且经常省略邮政编码等元素。即使是最复杂的正则表达式也很难可靠地处理这种可变性。
这就是 GPT-3.5 Turbo 或 GPT-4o-mini 等人工智能模型的闪光点——它们可以管理远远超出正则表达式等静态规则所能处理的不一致和复杂性。
更智能的人工智能工作流程
是的,我们正在开发一种人工智能工作流程,可以显着改进传统方法。
每个机器学习项目都可以归结为两个要素:数据和模型。虽然模型很重要,但数据更为关键。
模型已预先打包、测试,并且可以更换以查看哪一个性能更好。但真正的游戏规则改变者是我们提供给模型的数据的质量。
数据在机器学习中的作用
通常,我们将数据集分为两部分或三部分:
- 训练数据:用于教导模型应该做什么。
- 测试数据:用于评估模型的性能。
对于这个项目,我们希望将地址拆分为其各个组成部分 - 使其成为分类任务。为了使用像 GPT 这样的大型语言模型 (LLM) 获得良好的结果,我们的训练数据集中至少需要 100 个示例。
构建数据集
我们数据集的原始格式并不重要,但我选择了一种直观且易于使用的结构:
{
"street": "Strada Grui",
"block": "Bloc 7",
"staircase": "Scara A",
"apartment": "Apartament 6",
"city": "Zărnești"
}
这是一个例子:
STRADA GRUI, BLOC 7, SCARA A, APARTAMENT 6, ZĂRNEŞTI BD. 21 DECEMBRIE 1989 nr. 93 ap. 50, CLUJ, 400124
如您所见,目标是根据输入地址生成结构化 JSON 响应。
设置您的 OpenAI API 帐户
首先,您需要一个 OpenAI API 帐户。这是一个简单的过程,我建议添加一些初始资金——10 美元或 20 美元就足够了。 OpenAI 使用方便的预付费订阅模式,因此您可以完全控制自己的支出。
您可以在此处管理您的帐户账单:

探索 OpenAI Playground
您的帐户设置完毕后,请前往 OpenAI Playground。
花点时间熟悉一下界面。准备好后,在左侧菜单中查找“助手”部分。
我们将在此处创建自定义 GPT 实例。
自定义您的 GPT 助手
我们将分两个阶段定制 GPT 助手来满足我们的特定需求:
详细的系统说明和示例
这一步可以帮助我们快速测试并验证解决方案是否有效。这是查看结果的最快方式。使用知识库进行微调(简单 RAG)
一旦我们对初步结果感到满意,我们就会对模型进行微调。此过程减少了在每个提示中提供大量示例的需要,从而减少了推理时间(模型通过 API 响应所需的时间)。
这两个步骤的结合为我们提供了最准确、最高效的结果。
那么,让我们开始吧。
设计命名实体识别的系统提示
对于我们的命名实体识别系统,我们需要模型一致地输出结构化 JSON 响应。精心设计一个周到的系统提示对于实现这一目标至关重要。
我们将重点关注:
- 构建最初的“脏”系统提示以产生清晰的结果。
- 稍后完善提示,以提高效率并最小化成本。
从少击技术开始
“few-shot”技术是完成此任务的有效方法。它的工作原理是为模型提供一些所需输入输出关系的示例。从这些示例中,模型可以概括并处理以前从未见过的输入。
几次提示的关键要素:
提示由几个部分组成,应经过深思熟虑的结构以获得最佳结果。虽然确切的顺序可能有所不同,但以下部分是必不可少的:
1. 明确的目标
提示的第一部分概述了我们期望模型完成的任务。
例如,在此用例中,输入是罗马尼亚地址,其中可能包括拼写错误和格式不正确。此上下文至关重要,因为它为模型奠定了基础,解释了它将处理的数据类型。

2. 格式化指令
定义任务后,我们指导 AI 如何格式化其输出。
这里详细解释了 JSON 结构,包括模型应如何从输入中派生每个键值对。包含示例是为了阐明期望。此外,任何特殊字符都会被正确转义以确保有效的 JSON。

3. 例子
示例是“few-shot”技术的支柱。我们提供的相关示例越多,模型的性能就越好。
得益于 GPT 广泛的上下文窗口(最多 16K 个令牌),我们可以包含大量示例。
构建示例集:
从基本提示开始并手动评估模型的输出。
如果输出包含错误,请更正它们并将修复的版本添加到示例集中。
随着时间的推移,这个迭代过程会提高助手的性能。

4. 更正信息
这是不可避免的——你的助手会犯错误。有时,它可能会重复犯同样的错误。
要解决此问题,请在提示中包含清晰且礼貌的纠正信息。解释清楚:
助理犯了什么错误。
您期望从输出中得到什么。
此反馈有助于模型调整其行为并产生更好的结果。

配置和测试您的助手
现在我们已经为我们的概念验证几次解决方案制作了初始提示,是时候配置和测试助手了。
步骤1
- 前往 OpenAI 仪表板
- 从左侧菜单中选择“助手”
- 您将被重定向到助理创建页面。 返回 OpenAI 仪表板,从左侧菜单中选择“助手”。 您将被重定向到助理创建者。
第 2 步:配置您的助手
- 为您的助手命名:为您的助手选择一个能够反映其用途的描述性名称(例如“地址解析器”)。
- 粘贴系统说明:复制整个制作的提示并将其粘贴到系统说明输入框中。这定义了 Google 助理的行为并指导其输出。
- 保存您的助手:粘贴提示后,单击“保存”以存储配置。
第 3 步:选择合适的型号
对于这个项目,我选择 GPT-4o-mini 因为:
- 比 GPT-3.5 Turbo 便宜
- 更准确:)
也就是说,您应该始终根据准确性和成本之间的平衡来选择模型。运行或搜索基准测试以确定最适合您的特定任务的方法。

定义输出模式
初始配置到位后,我们现在可以直接在助手创建器中指定输出架构。
第 1 步:使用“生成”选项
我没有手动创建架构,而是使用助理创建者提供的“生成”选项。方法如下:
- 从提示中获取 JSON 输出结构(来自示例之一)
- 将其粘贴到“生成”字段中。
该工具在自动生成与您的结构相匹配的模式方面做得很好。

--
为了确保一致且可预测的反应,请将温度设置得尽可能低。

什么是温度?
温度控制模型响应的随机性。较低的温度值意味着模型会产生更具可预测性和确定性的输出。
对于我们的用例,这正是我们想要的。当给定与输入相同的地址时,模型应始终返回相同的正确响应。一致性是获得可靠结果的关键。
测试助手
所有参数就位后,前往 Playground 测试您的解决方案。
Playground 提供了一个控制台,您可以在其中让 Google 助理开始工作。这就是乐趣开始的地方 - 您可以严格测试您的基本解决方案以发现:
- 模型出现幻觉(生成不相关或不正确的信息)。
- 提示或架构中的潜在缺陷。
这些发现将帮助您完善提示的纠正信息部分,使您的智能助理更加强大。
下面是我的一项手动测试的结果示例:
{
"street": "Strada Grui",
"block": "Bloc 7",
"staircase": "Scara A",
"apartment": "Apartament 6",
"city": "Zărnești"
}
为什么手动测试很重要?
老式的实践测试是构建可靠解决方案的基础。通过手动评估模型的输出,您将快速发现问题并了解如何修复它们。虽然自动化稍后会出现,但手动测试是创建可靠的概念验证的宝贵步骤。
将助手插入您的 PHP Symfony 应用程序
现在是时候将所有内容集成到您的 PHP Symfony 应用程序中了。设置非常简单,并遵循经典的异步架构。

以下是流程细分:
1.前端交互
总的来说,我们这里有一个带有消息队列的经典异步设置。我们有 2 个 Symfony 应用程序实例在 Docker 容器内运行。第一个是与前端客户端交互。
例如,当客户输入:
STRADA GRUI, BLOC 7, SCARA A, APARTAMENT 6, ZĂRNEŞTI BD. 21 DECEMBRIE 1989 nr. 93 ap. 50, CLUJ, 400124
应用程序处理输入地址并将其打包成 Message 对象。
然后 Message 对象被包装在 Symfony Messenger Envelope 实例中。该消息被序列化为 JSON 格式,并带有用于处理的附加元数据。
Symfony Messenger 非常适合处理异步任务。它允许我们将耗时的操作(例如调用 OpenAI API)卸载到后台进程。
这种方法确保:
- 响应能力: 前端保持快速且响应迅速。
- 可扩展性:任务可以分配给多个工作人员。
以下是我们系统使用的消息类:
{
"street": "Strada Grui",
"block": "Bloc 7",
"staircase": "Scara A",
"apartment": "Apartament 6",
"city": "Zărnești"
}
应用程序使用 amqp PHP 扩展连接到 RabbitMQ 实例。要进行此设置,您需要在 messenger.yaml 配置文件中定义传输和消息绑定。
请参阅 Symfony Messenger 官方文档以获取详细指导:
Symfony Messenger 传输配置
文档:https://symfony.com/doc/current/messenger.html#transport-configuration
消息被推送到代理(例如 RabbitMQ、AmazonMQ 或 AWS SQS)后,它就会被应用程序的第二个实例接收。此实例运行信使守护进程来使用消息,如架构模式中标记的 3。
消费进程通过运行来处理:
bin/控制台信使:消费
正在按照其流程进行。
守护进程从配置的队列中获取消息,将其反序列化回相应的 Message 类,并将其转发给 Message Handler 进行处理。
这是与 OpenAI Assistant 进行交互的 消息处理程序:
STRADA GRUI, BLOC 7, SCARA A, APARTAMENT 6, ZĂRNEŞTI BD. 21 DECEMBRIE 1989 nr. 93 ap. 50, CLUJ, 400124
Handler 的要点
记录
记录处理的开始,以进行可追溯性和调试。
标准化服务调用 OpenAIAddressNormalizationService 来通过 Assistant 处理输入地址。
坚持
规范化地址使用 Doctrine 的 EntityManager 保存在数据库中。
消息处理程序可能看起来像标准的 Symfony 代码,但核心位于这一行:
INPUT: <what goes into the LLM> OUTPUT: <what the LLM should produce>
该服务负责通过指定的 PHP 库与 OpenAI 交互。
OpenAI PHP 客户端
让我们深入了解如何使用 PHP 客户端来实现该服务。
这是 OpenAIAddressNormalizationService 的完整实现:
input: STRADA EREMIA GRIGORESCU, NR.11 BL.45B,SC.B NR 11/38, 107065 PLOIESTI
output: {{"street": "Eremia Grigorescu", "house_number": "11", "flat_number": "38", "block": "45B", "staircase": "45B", floor: "", "apartment": "", "landmark": "", "postcode": "107065", "county": "Prahova", 'commune': '', 'village': '', "city" "Ploiesti"}}
使用 openai-php/client 库获取推理(或完成)(本质上是来自 GPT 的响应)的工作流程遵循三个主要阶段:
1. OpenAI客户端和助手检索的初始化
第一步是设置 OpenAI 客户端并检索配置的 Assistant:
INPUT: BD. 21 DECEMBRIE 1989 nr. 93 ap. 50, CLUJ, 400124
OUTPUT:
{
"street": "Bdul 21 Decembrie 1989",
"house": "93",
"flat": "50",
"block": "",
"staircase": "",
"floor": "",
"apartment": "",
"landmark": "",
"intercom": "",
"postcode": "400124",
"county": "Cluj",
"commune": "",
"village": "",
"city": "Cluj"
}
客户端初始化: OpenAI::client() 方法使用您的 API 密钥和组织 ID 创建一个新客户端。
助手检索:retrieve() 方法连接到为您的任务配置的特定 Assistant 实例,由其唯一 ID 标识。
1. 创建并运行线程
客户端和助手初始化后,您可以创建并运行线程来开始交互。线程充当通信管道,处理用户和助手之间的消息交换。
线程的启动方式如下:
{
"street": "Strada Grui",
"block": "Bloc 7",
"staircase": "Scara A",
"apartment": "Apartament 6",
"city": "Zărnești"
}
- 助手 ID:助手的 ID 决定哪个模型实例将处理输入。
- 消息: 每个线程都包含一系列消息。在这种情况下,消息具有角色,指示消息是来自用户(输入)还是来自系统(响应)。第二个是 Content - 包含实际的输入文本(例如地址)。
3. 处理线程响应
启动线程后,应用程序处理响应。由于 OpenAI 进程可能不会立即完成,因此您需要轮询线程的状态,直到它被标记为“已完成”:
STRADA GRUI, BLOC 7, SCARA A, APARTAMENT 6, ZĂRNEŞTI BD. 21 DECEMBRIE 1989 nr. 93 ap. 50, CLUJ, 400124
轮询:应用程序重复检查线程的状态(已排队或进行中)。一旦状态更改为“已完成”,线程就包含最终输出。
线程完成后,应用程序将检索响应消息以提取规范化地址:
INPUT: <what goes into the LLM> OUTPUT: <what the LLM should produce>
规范化地址现在可以返回到前端客户端以立即使用,或作为结构化实体(如 CustomerAddressNormalized)存储在数据库中,以供将来处理。
运行此设置时,您应该能够从 OpenAI 中提取并保存结构化输出,用于命名实体识别和其他分类或生成任务。
通过微调和知识库(检索增强生成)使助手炽热准确
在某些情况下,基本的人工智能解决方案还不够。当监管合规性和业务需求要求高精度时,我们需要加倍努力以确保输出真实可靠。
例如,在生成JSON结构时,我们需要保证其内容与实际相符。一个常见的风险是模型产生幻觉信息,例如根据提供的邮政编码发明一个地方。这可能会导致严重的问题,尤其是在高风险环境中。
具有知识库的基本事实
为了消除幻觉并确保事实准确性,我们需要为助手提供真实的知识库。这充当模型的明确参考,确保其在推理过程中使用准确的信息。
我的方法:邮政编码知识库
我创建了一个简单(但相当大,大约 12 MB)的 JSON 文件,其中包含罗马尼亚所有邮政编码的完整划分。这种类似字典的结构提供:
邮政编码: 输入值。
已验证信息: 相应城市、县和整体地名等事实。
该知识库可作为助手执行命名实体识别时的参考点。
知识库的结构
这是知识库 JSON 结构的示例片段:
{
"street": "Strada Grui",
"block": "Bloc 7",
"staircase": "Scara A",
"apartment": "Apartament 6",
"city": "Zărnești"
}
知识库准备就绪后,就可以指导助手有效地使用它了。虽然您可以将其直接嵌入到提示中,但这种方法会增加令牌的使用和成本。这是引入微调的绝佳时机。
什么是微调?
微调涉及修改预训练模型的最外层(特别是权重矩阵),使其适应特定任务。在我们的例子中,命名实体识别 (NER) 是一个完美的候选者。
微调模型:
- 需要较小的提示:减少对冗长说明或嵌入示例的需求。
- 降低成本:更短的提示和更少的示例可以降低代币消耗。
- 提高推理时间:更快的响应意味着更好的实时性能。
主要目标是使模型更紧密地与其将处理的现实世界数据的细微差别保持一致。对特定领域数据的训练使模型能够更好地理解和生成适当的响应。它还减少了应用程序进行后处理或纠错的需要。
准备微调数据集
为了微调模型,我们需要一个正确格式化的 .jsonl(JSON Lines)格式的数据集,按照 OpenAI 的要求。数据集中的每个条目包括:
- 系统提示:助手的初始指令。
- 用户输入:原始输入数据(例如,混乱的地址)。
- 预期输出:所需的结构化响应。
此数据集为助手提供了特定领域的示例,使其能够学习如何在将来响应类似的提示。
以下是如何构建微调条目的示例:
STRADA GRUI, BLOC 7, SCARA A, APARTAMENT 6, ZĂRNEŞTI BD. 21 DECEMBRIE 1989 nr. 93 ap. 50, CLUJ, 400124
让我们以罗马尼亚地址处理案例为例,分解 .jsonl 文件中微调条目的结构:

每个条目都旨在模拟用户和助手之间的真实交互,封装:
- 助理的目的和范围。
- 用户的输入场景。
- 预期的结构化输出。
这种方法有助于模型在现实环境中学习所需的行为。
1。系统角色消息
描述助手的功能及其功能范围,为其应识别和提取的实体类型设置期望,例如街道名称、门牌号码和邮政编码。
示例:系统解释说该助手旨在充当罗马尼亚地址的命名实体识别模型,详细说明了它应提取和分类的组件。
2。用户角色消息
- 提供详细的场景或查询,用户在其中输入特定的地址。这部分数据输入至关重要,因为它直接影响模型如何学习响应操作设置中的类似输入。
3。助理角色留言
- 包含来自助手的预期响应,采用 JSON 格式。此响应至关重要,因为它根据所需的输出格式和精度训练模型。
创建用于微调的验证文件
创建训练文件后,下一步就是准备验证文件。该文件评估微调助手对真实数据的准确性。其结构与训练文件类似,这使得自动创建两个文件变得更加简单。
验证文件旨在测试模型的泛化能力。它确保经过微调的助手能够处理新的输入并始终如一地执行,即使面对不熟悉或具有挑战性的示例也是如此。
验证文件的结构

系统消息:
为了保持训练过程的一致性,系统消息应该与训练文件中使用的消息相同。
用户留言:
引入未包含在训练文件中的新输入(例如地址)。新示例应该是现实的且针对特定领域的,并通过包含小错误或复杂性来挑战模型。
助理消息:
为新用户输入提供预期的结构化响应。
这是验证模型准确性的黄金标准。
为了简化训练和验证文件的创建,可以使用自动化脚本。这些脚本根据输入数据集生成格式正确的 .jsonl 文件。
访问包含脚本的存储库以生成训练和验证文件:
自动 .jsonl 生成脚本
这是微调自动化的 Python 版本。 PHP版本即将推出。
为什么验证很重要?
- 准确性测试: 衡量微调模型在未见过的数据上的表现。
- 泛化:验证模型处理新的、复杂的或容易出错的输入的能力。
- 反馈循环:帮助识别需要额外微调或数据的区域。
手动微调您的助手
如果您愿意,您可以使用 OpenAI 的图形用户界面 (GUI) 手动微调助手。准备好训练和验证文件后,请按照以下步骤开始:
第 1 步: 访问微调向导
- 转到仪表板并单击左侧菜单中的“微调”。
- 点击绿色的“创建”按钮打开微调菜单。
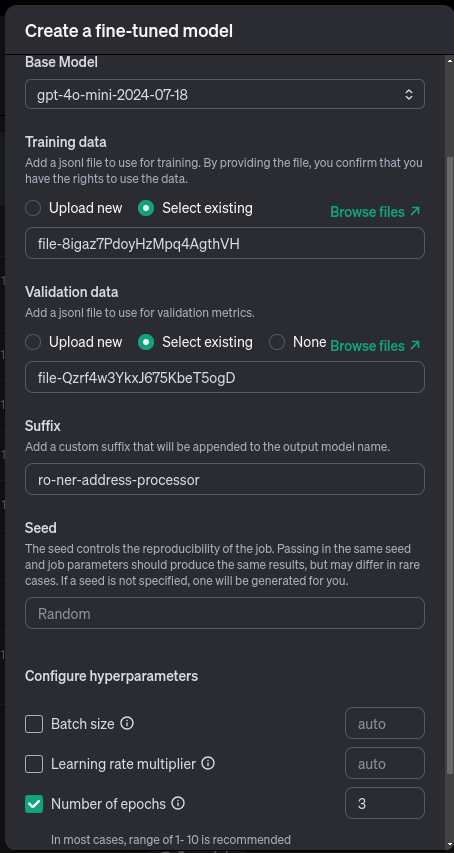
第 2 步: 配置微调
在微调菜单中,更新以下设置:
- 基础模型:在撰写本文时,最具成本效益和高性能的基础模型是 gpt-4o-mini-2024-07-18。选择最符合您的性能和预算要求的基本型号。
- 训练和验证数据 - 上传您之前创建的训练数据和验证数据文件。
- 纪元数 - 设置纪元数(整个数据集上训练过程的迭代)。我建议从 3 个 epoch 开始,但是如果您的预算允许,您可以尝试更多的 epoch。
第 3 步:监控微调过程
微调过程开始后,您可以在微调仪表板中跟踪其进度:

仪表板提供实时更新并显示多个指标,以帮助您监控和评估训练过程。
需要理解的关键指标
训练损失 衡量模型对训练数据的拟合程度。较低的训练损失表明模型正在有效地学习数据集中的模式。
完整验证损失 表示验证数据集中未见过的数据的性能。较低的验证损失表明该模型能够很好地推广到新的输入。
步骤和时间 训练步骤是迭代次数,模型权重根据批量数据进行更新。
时间戳指示每个步骤的处理时间,这有助于监控训练的持续时间和评估之间的间隔。
解释指标
监控以下指标可帮助您确定微调过程是否正确收敛或需要调整。
- 减少损失:理想情况下,训练和验证损失都应该随着时间的推移而减少,最终趋于稳定。 过度拟合:当训练损失持续减少而验证损失开始增加或波动时发生。这表明该模型对训练数据过于专业化,并且在未见过的数据上表现不佳。
欠拟合:当两个损失都很高时发生,表明模型没有有效学习。
插入模型并评估
您的助手经过培训和微调后,是时候将其集成到您的应用程序中并开始评估其性能了。
从简单开始。
从手动测试开始,无论是在 Assistants Playground 中还是直接在您的应用程序中。避免在此阶段使您的评估过于复杂;专注于确保基础知识按预期工作。
例如,您可以使用 Google Sheets 这样的简单工具来手动比较输入和输出,如下所示:

这是第一步。
人工智能和机器学习解决方案需要持续评估,以确保性能保持一致。对于命名实体识别等任务,自动化工具(例如 Visual Studio Code 的 PromptFlow 扩展)可以帮助简化测试和验证。
参考文献
OpenAI 微调文档
Symfony Messenger 文档
OpenAI PHP 客户端库
VS Code 的 PromptFlow 扩展
谢谢!
感谢您花时间探索本指南!我希望它能为您构建和微调人工智能驱动的解决方案奠定坚实的基础。如果您有任何疑问或建议,请随时联系或发表评论。
祝您编码愉快,祝您的人工智能项目好运! ?
以上是利用 OpenAI Assistant 在 PHP/Symfony 7 中进行命名实体识别的详细内容。更多信息请关注PHP中文网其他相关文章!