
#|自动提取 PDF 数据:用户验收测试

- Mary-Kate Olsen原创
- 2024-12-16 00:18:32897浏览
概述
在每个功能发布之前,我都会进行用户验收测试(“UAT”)以发现错误并确保业务逻辑正确转换为代码。
我只在 UAT 100% 成功后才清除发布功能。
我的推理很简单:你只有一次机会给最终用户留下良好的第一印象,而糟糕的发布会让它加倍困难。

虽然这是一个 MVP 功能,并不适合生产发布,但我认为做一些 UAT 来保持我的技能新鲜会很好。
结果
在我提出的 19 个 UAT 场景中,有一个因 托管人声明 PDF 模板的更改而失败。
我在 Discovery 期间就预见到了这种风险,但说实话,我没想到这个问题会这么快出现。
我将在本文后面详细介绍错误修复细节。
方法论
我的 UAT 流程涉及使用业务逻辑或功能需求作为参考来创建测试场景和预期结果。
测试场景不需要很复杂。它们可以很简单:“该功能会在 30 秒内生成 CSV 文件”。
对于 UAT,我处理了来自 10 个托管人声明 PDF 的 71 页 文件。这应该是一个足够大的样本集。
预期输出是三个 CSV 文件,其中包含托管人声明 PDF 的 基金持有、证券持有 和 现金持有 部分的特定数据点。
我想出了以下测试用例:
CSV 1:基金持有量
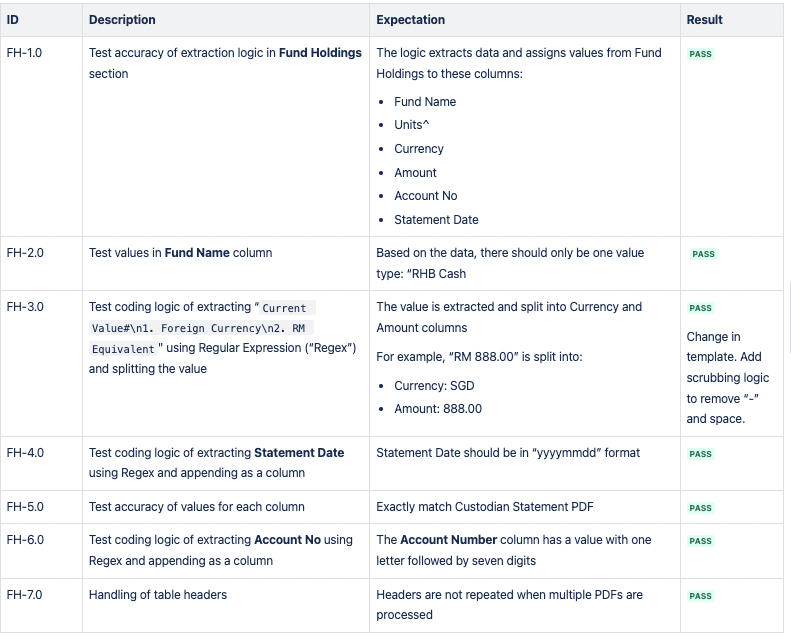
CSV 2:证券持有
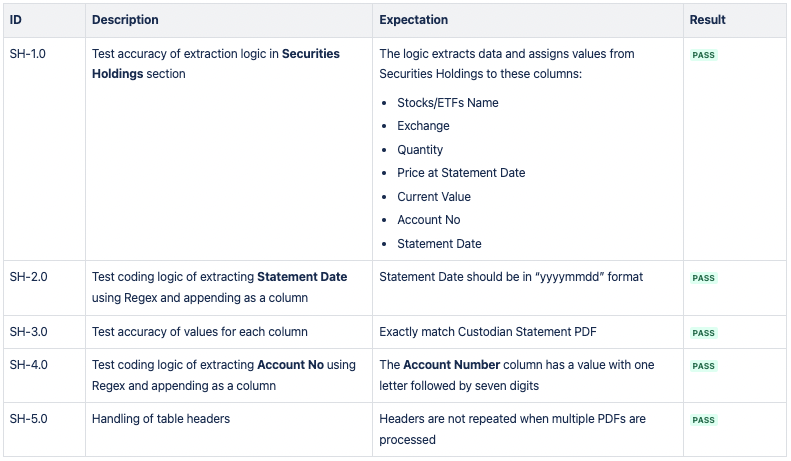
CSV 3:现金持有

错误修复
测试失败是因为托管人声明 PDF 的模板在 11 月份发生了轻微变化。更具体地说,基金持有表的“当前值#1.外币2.RM等值”列中的值现在有一个额外的“-n”前缀。
例如,以前的 PDF 中的值为“USD 10,000”,现在的值为“- USD10,000”。
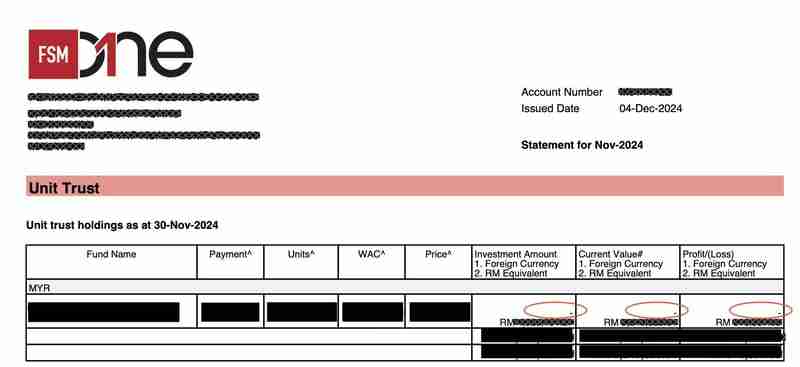
这个小变化导致了以下问题:

我咨询了 ChatGPT 进行修复,它建议添加以下清理逻辑以删除不正确的“-/n”前缀。
# Scrub error prefix
df['Currency'] = df['Currency'].str.replace('[-\n]', '', regex=True)
清理工作成功了,基金控股 CSV 输出现在按预期输出。
接下来做什么?
我现在很满意提取 PDF 数据的代码可以正常运行。也就是说,我认为 CSV 文件不是存储所有这些数据的最佳位置。
虽然 CSV 对我来说是用户友好的,但将数据存储在数据库中可以更轻松地根据最终用户的要求检索和操作数据。
我在数据库方面的经验非常有限。因此,我接下来要做的是在数据库应用程序上进行 Discovery,我可以快速上手。
--结束
以上是#|自动提取 PDF 数据:用户验收测试的详细内容。更多信息请关注PHP中文网其他相关文章!