


请我喝杯咖啡☕
*我的帖子解释了加州理工学院 101。
Caltech101()可以使用Caltech 101数据集,如下所示:
*备忘录:
- 第一个参数是 root(必需类型:str 或 pathlib.Path)。 *绝对或相对路径都是可能的。
- 第二个参数是 target_type(可选-默认:“category”-类型:str 或元组或 str 列表)。 *可以为其设置“类别”和/或“注释”。
- 第三个参数是transform(Optional-Default:None-Type:callable)。
- 第四个参数是 target_transform(Optional-Default:None-Type:callable)。
- 第五个参数是 download(可选-默认:False-类型:bool):
*备注:
- 如果为 True,则从互联网下载数据集并解压(解压)到根目录。
- 如果为 True 并且数据集已下载,则将其提取。
- 如果为 True 并且数据集已下载并提取,则不会发生任何事情。
- 如果数据集已经下载并提取,则应该为 False,因为它速度更快。
- 您可以从此处手动下载并提取数据集(101_ObjectCategories.tar.gz 和 Annotations.tar)到 data/caltech101/。
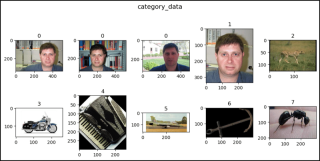
- 关于图像索引的类别,Faces(0) 为 0~434,Faces_easy(1) 为 435~869,豹子(2 )为870~1069, 摩托车(3)是1070~1867,手风琴(4)是1868~1922,飞机(5)是1923~2722,锚(6) 是2723~2764,蚂蚁(7)为2765~2806,桶(8)为2807~2853,低音(9)为2854~2907等。
from torchvision.datasets import Caltech101
category_data = Caltech101(
root="data"
)
category_data = Caltech101(
root="data",
target_type="category",
transform=None,
target_transform=None,
download=False
)
annotation_data = Caltech101(
root="data",
target_type="annotation"
)
all_data = Caltech101(
root="data",
target_type=["category", "annotation"]
)
len(category_data), len(annotation_data), len(all_data)
# (8677, 8677, 8677)
category_data
# Dataset Caltech101
# Number of datapoints: 8677
# Root location: data\caltech101
# Target type: ['category']
category_data.root
# 'data/caltech101'
category_data.target_type
# ['category']
print(category_data.transform)
# None
print(category_data.target_transform)
# None
category_data.download
# <bound method caltech101.download of dataset caltech101 number datapoints: root location: data target type:>
len(category_data.categories)
# 101
category_data.categories
# ['Faces', 'Faces_easy', 'Leopards', 'Motorbikes', 'accordion',
# 'airplanes', 'anchor', 'ant', 'barrel', 'bass', 'beaver',
# 'binocular', 'bonsai', 'brain', 'brontosaurus', 'buddha',
# 'butterfly', 'camera', 'cannon', 'car_side', 'ceiling_fan',
# 'cellphone', 'chair', 'chandelier', 'cougar_body', 'cougar_face', ...]
len(category_data.annotation_categories)
# 101
category_data.annotation_categories
# ['Faces_2', 'Faces_3', 'Leopards', 'Motorbikes_16', 'accordion',
# 'Airplanes_Side_2', 'anchor', 'ant', 'barrel', 'bass',
# 'beaver', 'binocular', 'bonsai', 'brain', 'brontosaurus',
# 'buddha', 'butterfly', 'camera', 'cannon', 'car_side',
# 'ceiling_fan', 'cellphone', 'chair', 'chandelier', 'cougar_body', ...]
category_data[0]
# (<pil.jpegimageplugin.jpegimagefile image mode="RGB" size="510x337">, 0)
category_data[1]
# (<pil.jpegimageplugin.jpegimagefile image mode="RGB" size="519x343">, 0)
category_data[2]
# (<pil.jpegimageplugin.jpegimagefile image mode="RGB" size="492x325">, 0)
category_data[435]
# (<pil.jpegimageplugin.jpegimagefile image mode="RGB" size="290x334">, 1)
category_data[870]
# (<pil.jpegimageplugin.jpegimagefile image mode="RGB" size="192x128">, 2)
annotation_data[0]
# (<pil.jpegimageplugin.jpegimagefile image mode="RGB" size="510x337">,
# array([[10.00958466, 8.18210863, 8.18210863, 10.92332268, ...],
# [132.30670927, 120.42811502, 103.52396166, 90.73162939, ...]]))
annotation_data[1]
# (<pil.jpegimageplugin.jpegimagefile image mode="RGB" size="519x343">,
# array([[15.19298246, 13.71929825, 15.19298246, 19.61403509, ...],
# [121.5877193, 103.90350877, 80.81578947, 64.11403509, ...]]))
annotation_data[2]
# (<pil.jpegimageplugin.jpegimagefile image mode="RGB" size="492x325">,
# array([[10.40789474, 7.17807018, 5.79385965, 9.02368421, ...],
# [131.30789474, 120.69561404, 102.23947368, 86.09035088, ...]]))
annotation_data[435]
# (<pil.jpegimageplugin.jpegimagefile image mode="RGB" size="290x334">,
# array([[64.52631579, 95.31578947, 123.26315789, 149.31578947, ...],
# [15.42105263, 8.31578947, 10.21052632, 28.21052632, ...]]))
annotation_data[870]
# (<pil.jpegimageplugin.jpegimagefile image mode="RGB" size="192x128">,
# array([[2.96536524, 7.55604534, 19.45780856, 33.73992443, ...],
# [23.63413098, 32.13539043, 33.83564232, 8.84193955, ...]]))
all_data[0]
# (<pil.jpegimageplugin.jpegimagefile image mode="RGB" size="510x337">,
# (0, array([[10.00958466, 8.18210863, 8.18210863, 10.92332268, ...],
# [132.30670927, 120.42811502, 103.52396166, 90.73162939, ...]]))
all_data[1]
# (<pil.jpegimageplugin.jpegimagefile image mode="RGB" size="519x343">,
# (0, array([[15.19298246, 13.71929825, 15.19298246, 19.61403509, ...],
# [121.5877193, 103.90350877, 80.81578947, 64.11403509, ...]]))
all_data[2]
# (<pil.jpegimageplugin.jpegimagefile image mode="RGB" size="492x325">,
# (0, array([[10.40789474, 7.17807018, 5.79385965, 9.02368421, ...],
# [131.30789474, 120.69561404, 102.23947368, 86.09035088, ...]]))
all_data[3]
# (<pil.jpegimageplugin.jpegimagefile image mode="RGB" size="538x355">,
# (0, array([[19.54035088, 18.57894737, 26.27017544, 38.2877193, ...],
# [131.49122807, 100.24561404, 74.2877193, 49.29122807, ...]]))
all_data[4]
# (<pil.jpegimageplugin.jpegimagefile image mode="RGB" size="528x349">,
# (0, array([[11.87982456, 11.87982456, 13.86578947, 15.35526316, ...],
# [128.34649123, 105.50789474, 91.60614035, 76.71140351, ...]]))
import matplotlib.pyplot as plt
def show_images(data, main_title=None):
plt.figure(figsize=(10, 5))
plt.suptitle(t=main_title, y=1.0, fontsize=14)
ims = (0, 1, 2, 435, 870, 1070, 1868, 1923, 2723, 2765, 2807, 2854)
for i, j in enumerate(ims, start=1):
plt.subplot(2, 5, i)
if len(data.target_type) == 1:
if data.target_type[0] == "category":
im, lab = data[j]
plt.title(label=lab)
elif data.target_type[0] == "annotation":
im, (px, py) = data[j]
plt.scatter(x=px, y=py)
plt.imshow(X=im)
elif len(data.target_type) == 2:
if data.target_type[0] == "category":
im, (lab, (px, py)) = data[j]
elif data.target_type[0] == "annotation":
im, ((px, py), lab) = data[j]
plt.title(label=lab)
plt.imshow(X=im)
plt.scatter(x=px, y=py)
if i == 10:
break
plt.tight_layout()
plt.show()
show_images(data=category_data, main_title="category_data")
show_images(data=annotation_data, main_title="annotation_data")
show_images(data=all_data, main_title="all_data")
</pil.jpegimageplugin.jpegimagefile></pil.jpegimageplugin.jpegimagefile></pil.jpegimageplugin.jpegimagefile></pil.jpegimageplugin.jpegimagefile></pil.jpegimageplugin.jpegimagefile></pil.jpegimageplugin.jpegimagefile></pil.jpegimageplugin.jpegimagefile></pil.jpegimageplugin.jpegimagefile></pil.jpegimageplugin.jpegimagefile></pil.jpegimageplugin.jpegimagefile></pil.jpegimageplugin.jpegimagefile></pil.jpegimageplugin.jpegimagefile></pil.jpegimageplugin.jpegimagefile></pil.jpegimageplugin.jpegimagefile></pil.jpegimageplugin.jpegimagefile></bound>


以上是PyTorch 中的加州理工学院的详细内容。更多信息请关注PHP中文网其他相关文章!

 您如何切成python阵列?May 01, 2025 am 12:18 AM
您如何切成python阵列?May 01, 2025 am 12:18 AMPython列表切片的基本语法是list[start:stop:step]。1.start是包含的第一个元素索引,2.stop是排除的第一个元素索引,3.step决定元素之间的步长。切片不仅用于提取数据,还可以修改和反转列表。
 在什么情况下,列表的表现比数组表现更好?May 01, 2025 am 12:06 AM
在什么情况下,列表的表现比数组表现更好?May 01, 2025 am 12:06 AMListSoutPerformarRaysin:1)DynamicsizicsizingandFrequentInsertions/删除,2)储存的二聚体和3)MemoryFeliceFiceForceforseforsparsedata,butmayhaveslightperformancecostsinclentoperations。
 如何将Python数组转换为Python列表?May 01, 2025 am 12:05 AM
如何将Python数组转换为Python列表?May 01, 2025 am 12:05 AMtoConvertapythonarraytoalist,usEthelist()constructororageneratorexpression.1)intimpthearraymoduleandcreateanArray.2)USELIST(ARR)或[XFORXINARR] to ConconverTittoalist,请考虑performorefformanceandmemoryfformanceandmemoryfformienceforlargedAtasetset。
 当Python中存在列表时,使用数组的目的是什么?May 01, 2025 am 12:04 AM
当Python中存在列表时,使用数组的目的是什么?May 01, 2025 am 12:04 AMchoosearraysoverlistsinpythonforbetterperformanceandmemoryfliceSpecificScenarios.1)largenumericaldatasets:arraysreducememoryusage.2)绩效 - 临界杂货:arraysoffersoffersOffersOffersOffersPoostSfoostSforsssfortasssfortaskslikeappensearch orearch.3)testessenforcety:arraysenforce:arraysenforc
 说明如何通过列表和数组的元素迭代。May 01, 2025 am 12:01 AM
说明如何通过列表和数组的元素迭代。May 01, 2025 am 12:01 AM在Python中,可以使用for循环、enumerate和列表推导式遍历列表;在Java中,可以使用传统for循环和增强for循环遍历数组。1.Python列表遍历方法包括:for循环、enumerate和列表推导式。2.Java数组遍历方法包括:传统for循环和增强for循环。
 什么是Python Switch语句?Apr 30, 2025 pm 02:08 PM
什么是Python Switch语句?Apr 30, 2025 pm 02:08 PM本文讨论了Python版本3.10中介绍的新“匹配”语句,该语句与其他语言相同。它增强了代码的可读性,并为传统的if-elif-el提供了性能优势

 Python中的功能注释是什么?Apr 30, 2025 pm 02:06 PM
Python中的功能注释是什么?Apr 30, 2025 pm 02:06 PMPython中的功能注释将元数据添加到函数中,以进行类型检查,文档和IDE支持。它们增强了代码的可读性,维护,并且在API开发,数据科学和图书馆创建中至关重要。


热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

Video Face Swap
使用我们完全免费的人工智能换脸工具轻松在任何视频中换脸!

热门文章
热工具

Atom编辑器mac版下载
最流行的的开源编辑器

VSCode Windows 64位 下载
微软推出的免费、功能强大的一款IDE编辑器

WebStorm Mac版
好用的JavaScript开发工具

螳螂BT
Mantis是一个易于部署的基于Web的缺陷跟踪工具,用于帮助产品缺陷跟踪。它需要PHP、MySQL和一个Web服务器。请查看我们的演示和托管服务。

禅工作室 13.0.1
功能强大的PHP集成开发环境

