
批量、小批量和随机梯度下降

- Linda Hamilton原创
- 2024-11-24 11:26:09540浏览
请我喝杯咖啡☕
*备忘录:
- 我的文章解释了 PyTorch 中使用 DataLoader() 进行批量、小批量和随机梯度下降。
- 我的文章解释了 PyTorch 中不使用 DataLoader() 的批量梯度下降。
- 我的文章解释了 PyTorch 中的优化器。
有批量梯度下降(BGD)、小批量梯度下降(MBGD)和随机梯度下降(SGD),它们是如何从数据集中获取数据使用梯度下降的方法优化器,例如 Adam()、SGD()、RMSprop()、Adadelta()、Adagrad() 等PyTorch。
*备忘录:
- PyTorch 中的 SGD() 只是基本的梯度下降,没有特殊功能(经典梯度下降(CGD)),而不是随机梯度下降(SGD)。
- 例如,使用下面这些方式,您可以灵活地使用 Adam() 执行 BGD、MBGD 或 SGD Adam,使用 SGD() 执行 CGD,使用 RMSprop() 执行 RMSprop,使用 Adadelta() 执行 Adadelta,使用 Adagrad() 执行 Adagrad, PyTorch 中的等。
- 基本上,BGD、MBGD 或 SGD 是通过 DataLoader() 对数据集进行混洗来完成的:
*备注:
- 改组数据集可以缓解过度拟合。 *基本上,只有训练数据被打乱,因此测试数据不会被打乱。
- 我的帖子解释了过度拟合和欠拟合。
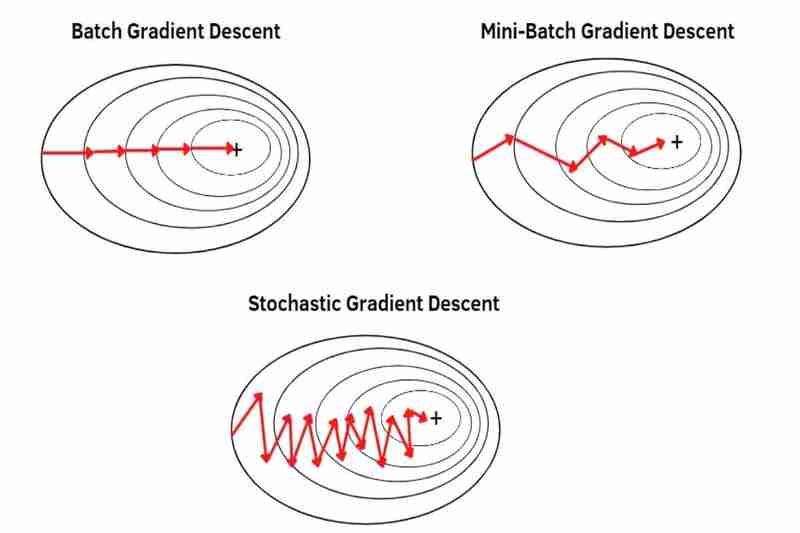
(1) 批量梯度下降(BGD):
- 可以对整个数据集进行梯度下降,在一个时期内只采取一步。例如,整个数据集有 100 个样本(1x100),那么梯度下降在一个 epoch 中只发生一次,这意味着模型的参数在一个 epoch 中只更新一次。
- 使用整个数据集的平均值,因此每个样本不如 MBGD 和 SGD 那么突出(不太强调)。因此,收敛比 MBGD 和 SGD 更稳定(波动更小),并且比 MBGD 和 SGD 的噪声(噪声数据)更强,导致比 MBGD 和 SGD 更少的超调,并且创建比 MBGD 和 SGD 更准确的模型,如果没有陷入局部最小值,但 BGD 比 MBGD 和 SGD 更不容易逃脱局部最小值或鞍点,因为正如我之前所说,收敛比 MBGD 和 SGD 更稳定(波动更小)正如我之前所说,BGD 比 MBGD 和 SGD 更容易导致过拟合,因为每个样本都比 MBGD 和 SGD 不那么突出(不太强调)。
*备注:
- 收敛表示初始权重通过梯度下降向函数的全局最小值移动。
- 噪声(噪声数据) 表示离群值、异常或有时重复的数据。
- 超调意味着跳过函数的全局最小值。
- 的优点:
- 收敛比 MBGD 和 SGD 更稳定(波动更小)。
- 它的噪声(噪声数据)比 MBGD 和 SGD 强。
- 它比 MBGD 和 SGD 更少导致过冲。
- 如果没有陷入局部最小值,它会创建比 MBGD 和 SGD 更准确的模型。
- 的缺点:
- 它不擅长在线学习等大型数据集,因为它需要大量内存,减慢收敛速度。 *在线学习是模型从数据集流中实时增量学习的方式。
- 如果你想更新模型,需要重新准备整个数据集。
- 与 MBGD 和 SGD 相比,它更不容易逃脱局部最小值或鞍点。
- 比 MBGD 和 SGD 更容易导致过拟合。
(2)小批量梯度下降(MBGD):
- 可以用分割的数据集(整个数据集的小批量)一小批一小批地进行梯度下降,在一个时期内采取与整个数据集的小批量相同的步数。例如,将具有 100 个样本(1x100)的整个数据集分为 5 个小批次(5x20),然后梯度下降在一个 epoch 内发生 5 次,这意味着模型的参数在一个 epoch 内更新 5 次。
使用从整个数据集中分割出来的每个小批次的平均值,因此每个样本比 BDG 更突出(更强调)。 *将整个数据集分成更小的批次可以使每个样本越来越突出(越来越强调)。因此,收敛比 BGD 更不稳定(波动更大),并且噪声(噪声数据)也比 BGD 弱,比 BGD 更容易导致过冲,并且即使没有陷入局部极小值,也会创建比 BGD 更不准确的模型,但MBGD 比 BGD 更容易逃脱局部最小值或鞍点,因为正如我之前所说,收敛比 BGD 更不稳定(波动更大),MBGD 比 BGD 更不容易导致过拟合,因为每个样本都更稳定正如我之前所说,out(更强调)比 BGD 更重要。
-
的优点:
- 在在线学习等大型数据集上,它比 BGD 更好,因为它比 BGD 占用更少的内存,比 BGD 更不会减慢收敛速度。
- 如果你想更新模型,不需要重新准备整个数据集。
- 它比 BGD 更容易逃脱局部最小值或鞍点。
- 比 BGD 更不容易导致过拟合。
-
的缺点:
- 收敛性比 BGD 更不稳定(波动更大)。
- 它的噪声(噪声数据)不如 BGD 强。
- 它比 BGD 更容易导致过冲。
- 即使没有陷入局部最小值,它也会创建一个不如 BGD 准确的模型。
(3) 随机梯度下降(SGD):
- 可以对整个数据集的每个样本进行梯度下降,一个样本一个样本,在一个时期内采取与整个数据集的样本相同的步数。例如,整个数据集有 100 个样本(1x100),那么梯度下降在一个 epoch 内发生 100 次,这意味着模型的参数在一个 epoch 内更新 100 次。
使用整个数据集的每一个样本逐个样本而不是平均值,因此每个样本比 MBGD 更突出(更强调)。因此,收敛比 MBGD 更不稳定(更波动),并且噪声(噪声数据)也比 MBGD 弱,比 MBGD 更容易导致过冲,并且即使没有陷入局部极小值,也会创建比 MBGD 更不准确的模型,但SGD 比 MBGD 更容易逃脱局部极小值或鞍点,因为正如我之前所说,收敛比 MBGD 更不稳定(波动更大),而且 SGD 比 MBGD 更不容易导致过拟合,因为每个样本都更稳定正如我之前所说,out(更强调)比MBGD。
-
的优点:
- 在大型数据集(例如在线学习)上它比 MBGD 更好,因为它比 MBGD 需要更小的内存,比 MBGD 更不会减慢收敛速度。
- 如果你想更新模型,不需要重新准备整个数据集。
- 它比 MBGD 更容易逃脱局部最小值或鞍点。
- 比 MBGD 更不容易导致过拟合。
-
的缺点:
- 收敛性比 MBGD 更不稳定(波动更大)。
- 它的噪声(噪声数据)不如 MBGD 强。
- 它比 MBGD 更容易导致过冲。
- 如果没有陷入局部最小值,它会创建一个不如 MBGD 准确的模型。
以上是批量、小批量和随机梯度下降的详细内容。更多信息请关注PHP中文网其他相关文章!