


主要目标是通过以下标识符之一识别与每个文档关联的客户:

目标是使用命名实体识别 (NER) 从法律文档中提取客户名称。以下是我完成任务的方法:
数据:我收集了 PDF 格式的法律文件。任务是使用以下标识符之一来识别每个文档中提到的客户:
大概的客户名称(例如“John Doe”)
准确的客户名称(例如“Doe, John A.”)
大概的公司名称(例如“Doe Law Firm”)
准确的公司名称(例如“Doe, John A. Law Firm”)
大约 5% 的文档不包含任何识别实体。
数据集:为了开发模型,我使用了 710 个“真实”PDF 文档,这些文档分为三组:600 个用于训练,55 个用于验证,55 个用于测试。
标签:我收到了一个 Excel 文件,其中的实体被提取为纯文本,需要在文档文本中手动标记。使用 BIO 标记格式,我执行了以下步骤:
用“B-
继续用“I-
如果令牌不属于任何实体,则将其标记为“O”。
替代方法:像 LayoutLM 这样的模型也考虑了输入标记的边界框,可能会提高 NER 任务的性能。然而,我选择不使用这种方法,因为通常情况下,我已经花费了项目的大部分时间来准备数据(例如,重新格式化 Excel 文件、更正数据错误、标记)。要集成基于边界框的模型,我需要分配更多时间。
虽然理论上可以应用正则表达式和启发式来识别这些简单的实体,但我预计这种方法是不切实际的,因为它需要过于复杂的规则来精确识别其他潜在候选者中的正确实体(例如,律师姓名、案件)人数、诉讼程序的其他参与者)。相比之下,该模型能够学习区分相关实体,从而使启发式方法的使用变得多余。
以上是识别与法律文件相关的客户的详细内容。更多信息请关注PHP中文网其他相关文章!

 o易交易所app官方下载最新版本 o易交易所官方最新APP下载链接May 15, 2025 pm 06:00 PM
o易交易所app官方下载最新版本 o易交易所官方最新APP下载链接May 15, 2025 pm 06:00 PMo易交易所app是当前市场上备受欢迎的数字货币交易平台之一,凭借其高效、安全的交易环境吸引了大量用户。无论你是经验丰富的交易者,还是刚刚入门的投资者,o易交易所app都能为你提供一个便捷的交易体验。本文将为你详细介绍如何下载并安装o易交易所app的最新版本。请注意,本文提供的下载链接均为官方链接,使用这些链接可以确保你下载到最安全、最新的版本。
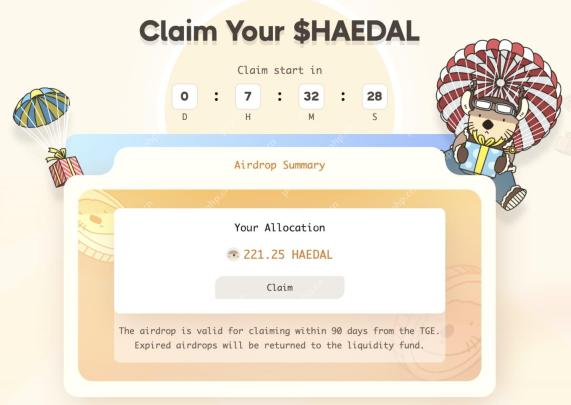 上线币安Alpha,HAEDAL空投价值分析May 15, 2025 pm 05:57 PM
上线币安Alpha,HAEDAL空投价值分析May 15, 2025 pm 05:57 PMHAEADL是Sui生态流动性质押协议Haedal的代币,已确认将上线币安Alpha和Bybit现货。Haedal在1月曾宣布完成种子轮融资,具体金额未披露。参与此轮融资的投资者包括Hashed、Comma 3Ventures、OKXVentures、AnimocaVentures、Sui基金会、FlowTraders、DewhalesCapital、Cetus、Scallop等。此外,
 加密货币分析师PlanB:以太坊是垃圾币!中心化程度远超比特币May 15, 2025 pm 05:54 PM
加密货币分析师PlanB:以太坊是垃圾币!中心化程度远超比特币May 15, 2025 pm 05:54 PM加密货币分析师、比特币Stock-to-Flow(S2F)模型开发者PlanB,于4月20日在社交平台X上针对以太坊(ETH)提出强烈批评。他转发了以太坊创办人VitalikButerin曾于2022年6月发布的一篇推文(该推文当时批评S2F模型),以此为契机反击以太坊,称其为「中心化、预挖、基于权益证明(PoS)且随意更改供应计划」的垃圾币。PlanB在推文中表示:以太坊现在看起来真的很糟糕。我知道幸灾乐祸有点不礼貌,但我认为像以太
 特斯拉营收3年来最差!回防补血冲本业:会减少在DOGE的工作May 15, 2025 pm 05:51 PM
特斯拉营收3年来最差!回防补血冲本业:会减少在DOGE的工作May 15, 2025 pm 05:51 PM特斯拉财报创下三年来最差表现。马斯克顺势宣布,会减少在白宫DOGE(政府效率部门)部门的工作,专注在自己的「本业」上。特斯拉营收3年来最差!回防补血冲本业:会减少在DOGE的工作特斯拉营收「3年来最差」美国总统川普(DonaldTrump)向全世界祭出关税的大刀,预计5月份还要对所有汽车零件进口,祭出25%的关税,连他的好朋友、好同事特斯拉(Tesla)马斯克(ElonMusk)也躲不了这阵旋风。一向自信满满的马斯克,在最新
 全球最大交易所注册入口(火币版)May 15, 2025 pm 05:48 PM
全球最大交易所注册入口(火币版)May 15, 2025 pm 05:48 PM火币全球(Huobi Global)作为全球领先的数字资产交易平台,自2013年成立以来,已发展成为全球最大的加密货币交易所之一。火币致力于为用户提供安全、便捷的数字资产交易服务,支持多种主流加密货币的交易,包括比特币(BTC)、以太坊(ETH)、莱特币(LTC)等。火币的用户遍布全球,拥有强大的技术团队和严格的安全措施,确保用户的资产和交易安全。
 Circle获阿布扎比ADGM初步许可货币服务 USDC正式登陆中东May 15, 2025 pm 05:45 PM
Circle获阿布扎比ADGM初步许可货币服务 USDC正式登陆中东May 15, 2025 pm 05:45 PM此举标志着Circle在中东地区拓展金融服务的重要里程碑,初步批准意味着Circle已满足在ADGM开展金融业务的相关要求,虽然仍需等待全面监管批准,但这一进展可能预示着完整执照的取得即将到来。对此,Circle联合创始人兼执行长JeremyAllaire评论表示:阿联酋正在为负责任的创新者铺平道路,以构建互联网金融系统。此次来自ADGM的初步批准推进了我们的战略,旨在深入扎根于拥抱链上经济的市场,为该地区的投资和创新创造新途径。这也
 SWTT是什么币种?SWTT币前景怎么样?May 15, 2025 pm 05:42 PM
SWTT是什么币种?SWTT币前景怎么样?May 15, 2025 pm 05:42 PMSWTT币的英文全称是SeeTheWorldThoughCars,实际上,SWTT是web3.0时代汽车领域底层协议IPFS的激励层,而IPFS则是被人民网认可的分布式存储技术。从某种程度上讲,SWTT币的未来与大数据时代的汽车后市场有着一定的联系,其未来的发展前景难以估量。随着社会和科技的迅猛发展,大数据已成为IT领域的热门话题,SWTT币可以说是踩准了当下的热点。那么,SWTT到底是什么币种?大家是否想了解SWTT币的前景呢?下面小编将为大家详细介绍。SWTT是什么币种?SeeTheWor
 从 $0.001 到 $1?三大不容忽视的迷因币May 15, 2025 pm 05:39 PM
从 $0.001 到 $1?三大不容忽视的迷因币May 15, 2025 pm 05:39 PM目录ShibaInu($SHIB)——让迷因变成现实力量BTCBull($BTCBULL)——还有哪种迷因币能给你比特币奖励?Pepe($PEPE)——互联网最受欢迎的青蛙重返舞台中央近期的市场动态表明,随着全球加密市场的扩张,迷因币可能正在酝酿一场重大回归。这是一个好迹象,因为在加密货币整体上涨时,迷因币通常充当利润倍增器。此外,迷因币的价格通常非常低廉,往往

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

Video Face Swap
使用我们完全免费的人工智能换脸工具轻松在任何视频中换脸!

热门文章
热工具

安全考试浏览器
Safe Exam Browser是一个安全的浏览器环境,用于安全地进行在线考试。该软件将任何计算机变成一个安全的工作站。它控制对任何实用工具的访问,并防止学生使用未经授权的资源。

DVWA
Damn Vulnerable Web App (DVWA) 是一个PHP/MySQL的Web应用程序,非常容易受到攻击。它的主要目标是成为安全专业人员在合法环境中测试自己的技能和工具的辅助工具,帮助Web开发人员更好地理解保护Web应用程序的过程,并帮助教师/学生在课堂环境中教授/学习Web应用程序安全。DVWA的目标是通过简单直接的界面练习一些最常见的Web漏洞,难度各不相同。请注意,该软件中

VSCode Windows 64位 下载
微软推出的免费、功能强大的一款IDE编辑器

SublimeText3汉化版
中文版,非常好用

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)

