


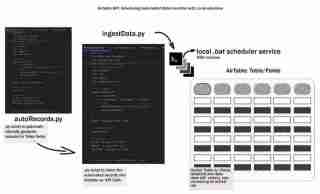
介绍
整个数据生命周期从生成数据并以某种方式在某个地方存储它开始。我们将其称为早期数据生命周期,我们将探索如何使用本地工作流程将数据自动摄取到 Airtable 中。我们将介绍设置开发环境、设计摄取过程、创建批处理脚本以及安排工作流程 - 保持事情简单、本地/可复制和可访问。
首先,我们来谈谈Airtable。 Airtable 是一个强大而灵活的工具,它将电子表格的简单性与数据库的结构融为一体。我发现它非常适合组织信息、管理项目、跟踪任务,而且它有免费套餐!
准备环境
设置开发环境
我们将使用 python 开发这个项目,所以使用你最喜欢的 IDE 并创建一个虚拟环境
# from your terminal python -m venv <environment_name> <environment_name>\Scripts\activate </environment_name></environment_name>
要开始使用 Airtable,请访问 Airtable 的网站。注册免费帐户后,您需要创建一个新的工作区。将工作区视为所有相关表和数据的容器。
接下来,在您的工作区中创建一个新表。表本质上是一个电子表格,您将在其中存储数据。定义表中的字段(列)以匹配数据结构。
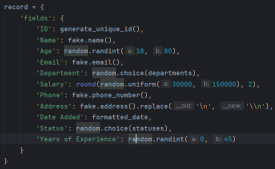
这是教程中使用的字段片段,它是 文本、日期 和 数字 的组合:
要将脚本连接到 Airtable,您需要生成 API 密钥或个人访问令牌。该密钥充当密码,允许您的脚本与 Airtable 数据进行交互。要生成密钥,请导航至您的 Airtable 帐户设置,找到 API 部分,然后按照说明创建新密钥。
*请记住确保您的 API 密钥安全。避免公开共享或将其提交到公共存储库。 *
安装必要的依赖项(Python、库等)
接下来,触摸requirements.txt。在此 .txt 文件中放置以下软件包:
pyairtable schedule faker python-dotenv
现在运行 pip install -rrequirements.txt 来安装所需的软件包。
组织项目结构
此步骤是我们创建脚本的地方,.env 是我们存储凭据的位置,autoRecords.py - 为定义的字段和 ingestData.py 将记录插入 Airtable。
设计摄取过程:环境变量
# from your terminal python -m venv <environment_name> <environment_name>\Scripts\activate </environment_name></environment_name>
设计摄取过程:自动记录
听起来不错,让我们为您在此员工数据生成器上的博客文章整理一个重点副主题内容。
为您的项目生成真实的员工数据
在处理涉及员工数据的项目时,拥有可靠的方法来生成真实的样本数据通常会很有帮助。无论您是构建人力资源管理系统、员工名录还是介于两者之间的任何系统,访问可靠的测试数据都可以简化您的开发并使您的应用程序更具弹性。
在本节中,我们将探索一个 Python 脚本,该脚本生成具有各种相关字段的随机员工记录。当您需要快速轻松地使用真实数据填充应用程序时,此工具可能是一项宝贵的资产。
生成唯一 ID
数据生成过程的第一步是为每个员工记录创建唯一标识符。这是一个重要的考虑因素,因为您的应用程序可能需要一种唯一引用每个员工的方法。我们的脚本包含一个简单的函数来生成这些 ID:
pyairtable schedule faker python-dotenv
该函数生成一个格式为“N-#####”的唯一 ID,其中数字是随机的 5 位数字。您可以自定义此格式以满足您的特定需求。
生成随机员工记录
接下来我们看一下生成员工记录的核心函数。 generate_random_records() 函数将要创建的记录数作为输入并返回字典列表,其中每个字典代表具有各个字段的员工:
"https://airtable.com/app########/tbl######/viw####?blocks=show" BASE_ID = 'app########' TABLE_NAME = 'tbl######' API_KEY = '#######'
该函数使用 Faker 库为各种员工字段生成逼真的数据,例如姓名、电子邮件、电话号码和地址。它还包括一些基本的约束,例如将年龄范围和工资范围限制在合理的值。
该函数返回一个字典列表,其中每个字典代表一条与 Airtable 兼容的格式的员工记录。
为 Airtable 准备数据
最后,让我们看一下prepare_records_for_airtable() 函数,该函数获取员工记录列表并提取每条记录的“字段”部分。这是 Airtable 期望导入数据的格式:
def generate_unique_id():
"""Generate a Unique ID in the format N-#####"""
return f"N-{random.randint(10000, 99999)}"
此功能简化了数据结构,使生成的数据与 Airtable 或其他系统集成时更容易使用。
把它们放在一起
要使用此数据生成工具,我们可以使用所需的记录数调用generate_random_records()函数,然后将结果列表传递给prepare_records_for_airtable()函数:
# from your terminal python -m venv <environment_name> <environment_name>\Scripts\activate </environment_name></environment_name>
这将生成 2 条随机员工记录,以原始格式打印它们,然后以适合 Airtable 的平面格式打印记录。
运行:
pyairtable schedule faker python-dotenv
输出:
"https://airtable.com/app########/tbl######/viw####?blocks=show" BASE_ID = 'app########' TABLE_NAME = 'tbl######' API_KEY = '#######'
将生成的数据与 Airtable 集成
除了生成真实的员工数据之外,我们的脚本还提供了将该数据与 Airtable 无缝集成的功能
设置 Airtable 连接
在开始将生成的数据插入 Airtable 之前,我们需要建立与平台的连接。我们的脚本使用 pyairtable 库与 Airtable API 进行交互。我们首先加载必要的环境变量,包括 Airtable API 密钥以及我们要存储数据的基本 ID 和表名称:
def generate_unique_id():
"""Generate a Unique ID in the format N-#####"""
return f"N-{random.randint(10000, 99999)}"
使用这些凭据,我们可以初始化 Airtable API 客户端并获取对我们要使用的特定表的引用:
def generate_random_records(num_records=10):
"""
Generate random records with reasonable constraints
:param num_records: Number of records to generate
:return: List of records formatted for Airtable
"""
records = []
# Constants
departments = ['Sales', 'Engineering', 'Marketing', 'HR', 'Finance', 'Operations']
statuses = ['Active', 'On Leave', 'Contract', 'Remote']
for _ in range(num_records):
# Generate date in the correct format
random_date = datetime.now() - timedelta(days=random.randint(0, 365))
formatted_date = random_date.strftime('%Y-%m-%dT%H:%M:%S.000Z')
record = {
'fields': {
'ID': generate_unique_id(),
'Name': fake.name(),
'Age': random.randint(18, 80),
'Email': fake.email(),
'Department': random.choice(departments),
'Salary': round(random.uniform(30000, 150000), 2),
'Phone': fake.phone_number(),
'Address': fake.address().replace('\n', '\n'), # Escape newlines
'Date Added': formatted_date,
'Status': random.choice(statuses),
'Years of Experience': random.randint(0, 45)
}
}
records.append(record)
return records
插入生成的数据
现在我们已经建立了连接,我们可以使用上一节中的generate_random_records()函数来创建一批员工记录,然后将它们插入到Airtable中:
def prepare_records_for_airtable(records):
"""Convert records from nested format to flat format for Airtable"""
return [record['fields'] for record in records]
prep_for_insertion()函数负责将generate_random_records()返回的嵌套记录格式转换为Airtable API期望的平面格式。准备好数据后,我们使用 table.batch_create() 方法在单个批量操作中插入记录。
错误处理和日志记录
为了确保我们的集成过程稳健且易于调试,我们还提供了一些基本的错误处理和日志记录功能。如果在数据插入过程中出现任何错误,脚本将记录错误消息以帮助排除故障:
if __name__ == "__main__":
records = generate_random_records(2)
print(records)
prepared_records = prepare_records_for_airtable(records)
print(prepared_records)
通过将我们早期脚本的强大数据生成功能与此处显示的集成功能相结合,您可以使用真实的员工数据快速可靠地填充基于 Airtable 的应用程序。
使用批处理脚本安排自动数据摄取
为了使数据摄取过程完全自动化,我们可以创建一个批处理脚本(.bat 文件)来定期运行 Python 脚本。这允许您将数据摄取设置为自动发生,无需手动干预。
以下是可用于运行 ingestData.py 脚本的批处理脚本示例:
python autoRecords.py
让我们分解一下这个脚本的关键部分:
- @echo off:此行禁止将每个命令打印到控制台,使输出更清晰。
- echo Running Airtable Automated Data Ingestion Service...:此行向控制台打印一条消息,表明脚本已启动。
- cd /d C:UsersbuascPycharmProjectsscrapEngineering:此行将当前工作目录更改为ingestData.py脚本所在的项目目录。
- call C:UsersbuascPycharmProjectsscrapEngineeringvenv_airtableScriptsactivate.bat:此行激活安装了必要的 Python 依赖项的虚拟环境。
- python ingestData.py:此行运行 ingestData.py Python 脚本。
- if %ERRORLEVEL% NEQ 0 (... ):此块检查 Python 脚本是否遇到错误(即 ERRORLEVEL 是否不为零)。如果发生错误,它会打印一条错误消息并暂停脚本,以便您调查问题。
要安排此批处理脚本自动运行,您可以使用 Windows 任务计划程序。以下是步骤的简要概述:
- 打开“开始”菜单并搜索“任务计划程序”。
或者
Windows R 和

- 在任务计划程序中,创建一个新任务并为其指定一个描述性名称(例如“Airtable Data Ingestion”)。
- 在“操作”选项卡中,添加新操作并指定批处理脚本的路径(例如 C:UsersbuascPycharmProjectsscrapEngineeringestData.bat)。
- 配置您希望脚本运行的时间表,例如每天、每周或每月。
- 保存任务并启用它。

现在,Windows 任务计划程序将按照指定的时间间隔自动运行批处理脚本,确保您的 Airtable 数据定期更新,无需手动干预。
结论
这对于测试、开发甚至演示来说都是一个非常宝贵的工具。
通过本指南,您学习了如何设置必要的开发环境、设计摄取流程、创建批处理脚本来自动执行任务,以及安排工作流程以实现无人值守执行。现在,我们对如何利用本地自动化的力量来简化我们的数据摄取操作并从 Airtable 驱动的数据生态系统中释放有价值的见解有了深入的了解。
现在您已经设置了自动数据摄取流程,您可以通过多种方式在此基础上进行构建,并从 Airtable 数据中释放更多价值。我鼓励您尝试代码,探索新的用例,并与社区分享您的经验。
这里有一些可以帮助您入门的想法:
- 自定义数据生成
- 利用获取的数据[基于 Markdown 的探索性数据分析 (EDA),使用 Tableau、Power BI 或 Plotly 等工具构建交互式仪表板或可视化,试验机器学习工作流程(预测员工流动率或识别表现最佳的员工)]
- 与其他系统集成[云函数、Webhook 或数据仓库]
可能性是无限的!我很高兴看到您如何构建这个自动化数据摄取流程,并从 Airtable 数据中释放新的见解和价值。请毫不犹豫地进行实验、协作并分享您的进展。我会一路支持你。
查看完整代码https://github.com/AkanimohOD19A/scheduling_airtable_insertion,完整视频教程正在路上。
以上是本地工作流程:将数据摄取编排到 Airtable 中的详细内容。更多信息请关注PHP中文网其他相关文章!

 Python中的合并列表:选择正确的方法May 14, 2025 am 12:11 AM
Python中的合并列表:选择正确的方法May 14, 2025 am 12:11 AMTomergelistsinpython,YouCanusethe操作员,estextMethod,ListComprehension,Oritertools
 如何在Python 3中加入两个列表?May 14, 2025 am 12:09 AM
如何在Python 3中加入两个列表?May 14, 2025 am 12:09 AM在Python3中,可以通过多种方法连接两个列表:1)使用 运算符,适用于小列表,但对大列表效率低;2)使用extend方法,适用于大列表,内存效率高,但会修改原列表;3)使用*运算符,适用于合并多个列表,不修改原列表;4)使用itertools.chain,适用于大数据集,内存效率高。
 Python串联列表字符串May 14, 2025 am 12:08 AM
Python串联列表字符串May 14, 2025 am 12:08 AM使用join()方法是Python中从列表连接字符串最有效的方法。1)使用join()方法高效且易读。2)循环使用 运算符对大列表效率低。3)列表推导式与join()结合适用于需要转换的场景。4)reduce()方法适用于其他类型归约,但对字符串连接效率低。完整句子结束。
 Python执行,那是什么?May 14, 2025 am 12:06 AM
Python执行,那是什么?May 14, 2025 am 12:06 AMpythonexecutionistheprocessoftransformingpypythoncodeintoExecutablestructions.1)InternterPreterReadSthecode,ConvertingTingitIntObyTecode,whepythonvirtualmachine(pvm)theglobalinterpreterpreterpreterpreterlock(gil)the thepythonvirtualmachine(pvm)
 Python:关键功能是什么May 14, 2025 am 12:02 AM
Python:关键功能是什么May 14, 2025 am 12:02 AMPython的关键特性包括:1.语法简洁易懂,适合初学者;2.动态类型系统,提高开发速度;3.丰富的标准库,支持多种任务;4.强大的社区和生态系统,提供广泛支持;5.解释性,适合脚本和快速原型开发;6.多范式支持,适用于各种编程风格。
 Python:编译器还是解释器?May 13, 2025 am 12:10 AM
Python:编译器还是解释器?May 13, 2025 am 12:10 AMPython是解释型语言,但也包含编译过程。1)Python代码先编译成字节码。2)字节码由Python虚拟机解释执行。3)这种混合机制使Python既灵活又高效,但执行速度不如完全编译型语言。
 python用于循环与循环时:何时使用哪个?May 13, 2025 am 12:07 AM
python用于循环与循环时:何时使用哪个?May 13, 2025 am 12:07 AMuseeAforloopWheniteratingOveraseQuenceOrforAspecificnumberoftimes; useAwhiLeLoopWhenconTinuingUntilAcIntiment.ForloopSareIdeAlforkNownsences,而WhileLeleLeleLeleLoopSituationSituationSituationsItuationSuationSituationswithUndEtermentersitations。
 Python循环:最常见的错误May 13, 2025 am 12:07 AM
Python循环:最常见的错误May 13, 2025 am 12:07 AMpythonloopscanleadtoerrorslikeinfiniteloops,modifyingListsDuringteritation,逐个偏置,零indexingissues,andnestedloopineflinefficiencies


热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

Video Face Swap
使用我们完全免费的人工智能换脸工具轻松在任何视频中换脸!

热门文章
热工具

SublimeText3 英文版
推荐:为Win版本,支持代码提示!

SecLists
SecLists是最终安全测试人员的伙伴。它是一个包含各种类型列表的集合,这些列表在安全评估过程中经常使用,都在一个地方。SecLists通过方便地提供安全测试人员可能需要的所有列表,帮助提高安全测试的效率和生产力。列表类型包括用户名、密码、URL、模糊测试有效载荷、敏感数据模式、Web shell等等。测试人员只需将此存储库拉到新的测试机上,他就可以访问到所需的每种类型的列表。

安全考试浏览器
Safe Exam Browser是一个安全的浏览器环境,用于安全地进行在线考试。该软件将任何计算机变成一个安全的工作站。它控制对任何实用工具的访问,并防止学生使用未经授权的资源。

Atom编辑器mac版下载
最流行的的开源编辑器

记事本++7.3.1
好用且免费的代码编辑器

