


In this tutorial, we’ll build a simple chat interface that allows users to upload a PDF, retrieve its content using OpenAI’s API, and display the responses in a chat-like interface using Streamlit. We will also leverage @pinata to upload and store the PDF files.
Let's have a little glance at what we are building before moving forward:
Prerequisites :
- Basic knowledge of Python
- Pinata API key (for uploading PDFs)
- OpenAI API key (for generating responses)
- Streamlit installed (for building the UI)
Step 1: Project Setup
Start by creating a new Python project directory:
mkdir chat-with-pdf cd chat-with-pdf python3 -m venv venv source venv/bin/activate pip install streamlit openai requests PyPDF2
Now, create a .env file in the root of your project and add the following environment variables:
PINATA_API_KEY=<your pinata api key> PINATA_SECRET_API_KEY=<your pinata secret key> OPENAI_API_KEY=<your openai api key> </your></your></your>
One have to manage OPENAI_API_KEY by own as it's paid.But let's go through the process of creating api keys in Pinita.
So, before proceeding further let us know what Pinata is why we are using it.

Pinata is a service that provides a platform for storing and managing files on IPFS (InterPlanetary File System), a decentralized and distributed file storage system.
- Decentralized Storage: Pinata helps you store files on IPFS, a decentralized network.
- Easy to Use: It provides user-friendly tools and APIs for file management.
- File Availability: Pinata keeps your files accessible by "pinning" them on IPFS.
- NFT Support: It's great for storing metadata for NFTs and Web3 apps.
- Cost-Effective: Pinata can be a cheaper alternative to traditional cloud storage.
Let's create required tokens by signin:
Next step is to verify your registered email :

After verifying signin to generate api keys :

After that go to API Key Section and Create New API Keys:
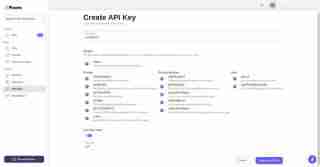
Finally, keys are successfully generated.Please copy that keys and save it in your code editor.
OPENAI_API_KEY=<your openai api key> PINATA_API_KEY=dfc05775d0c8a1743247 PINATA_SECRET_API_KEY=a54a70cd227a85e68615a5682500d73e9a12cd211dfbf5e25179830dc8278efc </your>
Step 2: PDF Upload using Pinata
We’ll use Pinata’s API to upload PDFs and get a hash (CID) for each file. Create a file named pinata_helper.py to handle the PDF upload.
import os # Import the os module to interact with the operating system
import requests # Import the requests library to make HTTP requests
from dotenv import load_dotenv # Import load_dotenv to load environment variables from a .env file
# Load environment variables from the .env file
load_dotenv()
# Define the Pinata API URL for pinning files to IPFS
PINATA_API_URL = "https://api.pinata.cloud/pinning/pinFileToIPFS"
# Retrieve Pinata API keys from environment variables
PINATA_API_KEY = os.getenv("PINATA_API_KEY")
PINATA_SECRET_API_KEY = os.getenv("PINATA_SECRET_API_KEY")
def upload_pdf_to_pinata(file_path):
"""
Uploads a PDF file to Pinata's IPFS service.
Args:
file_path (str): The path to the PDF file to be uploaded.
Returns:
str: The IPFS hash of the uploaded file if successful, None otherwise.
"""
# Prepare headers for the API request with the Pinata API keys
headers = {
"pinata_api_key": PINATA_API_KEY,
"pinata_secret_api_key": PINATA_SECRET_API_KEY
}
# Open the file in binary read mode
with open(file_path, 'rb') as file:
# Send a POST request to Pinata API to upload the file
response = requests.post(PINATA_API_URL, files={'file': file}, headers=headers)
# Check if the request was successful (status code 200)
if response.status_code == 200:
print("File uploaded successfully") # Print success message
# Return the IPFS hash from the response JSON
return response.json()['IpfsHash']
else:
# Print an error message if the upload failed
print(f"Error: {response.text}")
return None # Return None to indicate failure
Step 3: Setting up OpenAI
Next, we’ll create a function that uses the OpenAI API to interact with the text extracted from the PDF. We’ll leverage OpenAI’s gpt-4o or gpt-4o-mini model for chat responses.
Create a new file openai_helper.py:
import os
from openai import OpenAI
from dotenv import load_dotenv
# Load environment variables from .env file
load_dotenv()
# Initialize OpenAI client with the API key
OPENAI_API_KEY = os.getenv("OPENAI_API_KEY")
client = OpenAI(api_key=OPENAI_API_KEY)
def get_openai_response(text, pdf_text):
try:
# Create the chat completion request
print("User Input:", text)
print("PDF Content:", pdf_text) # Optional: for debugging
# Combine the user's input and PDF content for context
messages = [
{"role": "system", "content": "You are a helpful assistant for answering questions about the PDF."},
{"role": "user", "content": pdf_text}, # Providing the PDF content
{"role": "user", "content": text} # Providing the user question or request
]
response = client.chat.completions.create(
model="gpt-4", # Use "gpt-4" or "gpt-4o mini" based on your access
messages=messages,
max_tokens=100, # Adjust as necessary
temperature=0.7 # Adjust to control response creativity
)
# Extract the content of the response
return response.choices[0].message.content # Corrected access method
except Exception as e:
return f"Error: {str(e)}"
Step 4: Building the Streamlit Interface
Now that we have our helper functions ready, it’s time to build the Streamlit app that will upload PDFs, fetch responses from OpenAI, and display the chat.
Create a file named app.py:
import streamlit as st
import os
import time
from pinata_helper import upload_pdf_to_pinata
from openai_helper import get_openai_response
from PyPDF2 import PdfReader
from dotenv import load_dotenv
# Load environment variables
load_dotenv()
st.set_page_config(page_title="Chat with PDFs", layout="centered")
st.title("Chat with PDFs using OpenAI and Pinata")
uploaded_file = st.file_uploader("Upload your PDF", type="pdf")
# Initialize session state for chat history and loading state
if "chat_history" not in st.session_state:
st.session_state.chat_history = []
if "loading" not in st.session_state:
st.session_state.loading = False
if uploaded_file is not None:
# Save the uploaded file temporarily
file_path = os.path.join("temp", uploaded_file.name)
with open(file_path, "wb") as f:
f.write(uploaded_file.getbuffer())
# Upload PDF to Pinata
st.write("Uploading PDF to Pinata...")
pdf_cid = upload_pdf_to_pinata(file_path)
if pdf_cid:
st.write(f"File uploaded to IPFS with CID: {pdf_cid}")
# Extract PDF content
reader = PdfReader(file_path)
pdf_text = ""
for page in reader.pages:
pdf_text += page.extract_text()
if pdf_text:
st.text_area("PDF Content", pdf_text, height=200)
# Allow user to ask questions about the PDF
user_input = st.text_input("Ask something about the PDF:", disabled=st.session_state.loading)
if st.button("Send", disabled=st.session_state.loading):
if user_input:
# Set loading state to True
st.session_state.loading = True
# Display loading indicator
with st.spinner("AI is thinking..."):
# Simulate loading with sleep (remove in production)
time.sleep(1) # Simulate network delay
# Get AI response
response = get_openai_response(user_input, pdf_text)
# Update chat history
st.session_state.chat_history.append({"user": user_input, "ai": response})
# Clear the input box after sending
st.session_state.input_text = ""
# Reset loading state
st.session_state.loading = False
# Display chat history
if st.session_state.chat_history:
for chat in st.session_state.chat_history:
st.write(f"**You:** {chat['user']}")
st.write(f"**AI:** {chat['ai']}")
# Auto-scroll to the bottom of the chat
st.write("<style>div.stChat {overflow-y: auto;}</style>", unsafe_allow_html=True)
# Add three dots as a loading indicator if still waiting for response
if st.session_state.loading:
st.write("**AI is typing** ...")
else:
st.error("Could not extract text from the PDF.")
else:
st.error("Failed to upload PDF to Pinata.")
Step 5: Running the App
To run the app locally, use the following command:
streamlit run app.py
Our file is successfully uploaded in Pinata Platform :

Step 6: Explaining the Code
Pinata Upload
- The user uploads a PDF file, which is temporarily saved locally and uploaded to Pinata using the upload_pdf_to_pinata function. Pinata returns a hash (CID), which represents the file stored on IPFS.
PDF Extraction
- Setelah fail dimuat naik, kandungan PDF diekstrak menggunakan PyPDF2. Teks ini kemudiannya dipaparkan dalam kawasan teks.
Interaksi OpenAI
- Pengguna boleh bertanya soalan tentang kandungan PDF menggunakan input teks. Fungsi get_openai_response menghantar pertanyaan pengguna bersama kandungan PDF ke OpenAI, yang mengembalikan respons yang berkaitan.
Kod akhir tersedia dalam repo github ini :
https://github.com/Jagroop2001/chat-with-pdf
Itu sahaja untuk blog ini! Nantikan lebih banyak kemas kini dan teruskan membina apl yang menakjubkan! ?✨
Selamat mengekod! ?
以上是使用 Pinata、OpenAI 和 Streamlit 与您的 PDF 聊天的详细内容。更多信息请关注PHP中文网其他相关文章!

 Python vs. C:了解关键差异Apr 21, 2025 am 12:18 AM
Python vs. C:了解关键差异Apr 21, 2025 am 12:18 AMPython和C 各有优势,选择应基于项目需求。1)Python适合快速开发和数据处理,因其简洁语法和动态类型。2)C 适用于高性能和系统编程,因其静态类型和手动内存管理。
 Python vs.C:您的项目选择哪种语言?Apr 21, 2025 am 12:17 AM
Python vs.C:您的项目选择哪种语言?Apr 21, 2025 am 12:17 AM选择Python还是C 取决于项目需求:1)如果需要快速开发、数据处理和原型设计,选择Python;2)如果需要高性能、低延迟和接近硬件的控制,选择C 。
 达到python目标:每天2小时的力量Apr 20, 2025 am 12:21 AM
达到python目标:每天2小时的力量Apr 20, 2025 am 12:21 AM通过每天投入2小时的Python学习,可以有效提升编程技能。1.学习新知识:阅读文档或观看教程。2.实践:编写代码和完成练习。3.复习:巩固所学内容。4.项目实践:应用所学于实际项目中。这样的结构化学习计划能帮助你系统掌握Python并实现职业目标。
 最大化2小时:有效的Python学习策略Apr 20, 2025 am 12:20 AM
最大化2小时:有效的Python学习策略Apr 20, 2025 am 12:20 AM在两小时内高效学习Python的方法包括:1.回顾基础知识,确保熟悉Python的安装和基本语法;2.理解Python的核心概念,如变量、列表、函数等;3.通过使用示例掌握基本和高级用法;4.学习常见错误与调试技巧;5.应用性能优化与最佳实践,如使用列表推导式和遵循PEP8风格指南。
 在Python和C之间进行选择:适合您的语言Apr 20, 2025 am 12:20 AM
在Python和C之间进行选择:适合您的语言Apr 20, 2025 am 12:20 AMPython适合初学者和数据科学,C 适用于系统编程和游戏开发。1.Python简洁易用,适用于数据科学和Web开发。2.C 提供高性能和控制力,适用于游戏开发和系统编程。选择应基于项目需求和个人兴趣。
 Python与C:编程语言的比较分析Apr 20, 2025 am 12:14 AM
Python与C:编程语言的比较分析Apr 20, 2025 am 12:14 AMPython更适合数据科学和快速开发,C 更适合高性能和系统编程。1.Python语法简洁,易于学习,适用于数据处理和科学计算。2.C 语法复杂,但性能优越,常用于游戏开发和系统编程。
 每天2小时:Python学习的潜力Apr 20, 2025 am 12:14 AM
每天2小时:Python学习的潜力Apr 20, 2025 am 12:14 AM每天投入两小时学习Python是可行的。1.学习新知识:用一小时学习新概念,如列表和字典。2.实践和练习:用一小时进行编程练习,如编写小程序。通过合理规划和坚持不懈,你可以在短时间内掌握Python的核心概念。
 Python与C:学习曲线和易用性Apr 19, 2025 am 12:20 AM
Python与C:学习曲线和易用性Apr 19, 2025 am 12:20 AMPython更易学且易用,C 则更强大但复杂。1.Python语法简洁,适合初学者,动态类型和自动内存管理使其易用,但可能导致运行时错误。2.C 提供低级控制和高级特性,适合高性能应用,但学习门槛高,需手动管理内存和类型安全。


热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

Video Face Swap
使用我们完全免费的人工智能换脸工具轻松在任何视频中换脸!

热门文章
热工具

EditPlus 中文破解版
体积小,语法高亮,不支持代码提示功能

ZendStudio 13.5.1 Mac
功能强大的PHP集成开发环境

DVWA
Damn Vulnerable Web App (DVWA) 是一个PHP/MySQL的Web应用程序,非常容易受到攻击。它的主要目标是成为安全专业人员在合法环境中测试自己的技能和工具的辅助工具,帮助Web开发人员更好地理解保护Web应用程序的过程,并帮助教师/学生在课堂环境中教授/学习Web应用程序安全。DVWA的目标是通过简单直接的界面练习一些最常见的Web漏洞,难度各不相同。请注意,该软件中

螳螂BT
Mantis是一个易于部署的基于Web的缺陷跟踪工具,用于帮助产品缺陷跟踪。它需要PHP、MySQL和一个Web服务器。请查看我们的演示和托管服务。

mPDF
mPDF是一个PHP库,可以从UTF-8编码的HTML生成PDF文件。原作者Ian Back编写mPDF以从他的网站上“即时”输出PDF文件,并处理不同的语言。与原始脚本如HTML2FPDF相比,它的速度较慢,并且在使用Unicode字体时生成的文件较大,但支持CSS样式等,并进行了大量增强。支持几乎所有语言,包括RTL(阿拉伯语和希伯来语)和CJK(中日韩)。支持嵌套的块级元素(如P、DIV),

