


大家好,我又是 Mrzaizai2k!
在这个系列中,我想分享我解决发票关键信息提取(KIE)问题的方法。我们将探索如何利用 ChatGPT 和 Qwen2 等大型语言模型 (LLM) 进行信息提取。然后,我们将深入研究使用 PaddleOCR、零样本分类模型或 Llama 3.1 等 OCR 模型来对结果进行后处理。
— 天哪,这太令人兴奋了!
为了更上一层楼,我们将处理任何格式和任何语言的发票。是的,没错——这是真的!
分析需求
假设您需要构建一项服务,以任何语言从任何类型的发票中提取所有相关信息。就像您在此示例网站上找到的内容一样。
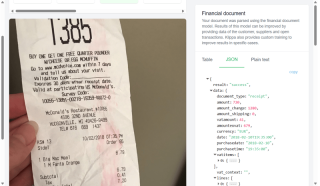
这是我们将使用的示例发票图像:

关键考虑因素
首先我们来详细分析一下需求。这将帮助我们为我们的系统选择正确的技术堆栈。虽然某些技术可能效果很好,但它们可能并不适合所有场景。以下是我们需要从上到下确定优先级的内容:
- 快速启动系统
- 确保准确性
-
使其在有限的计算资源上运行
- (例如,具有 12 GB VRAM 的 GPU RTX 3060 甚至 CPU)
-
保持合理的处理时间
- 每个发票在 CPU 上约 1 分钟,在 GPU 上约 10 秒
- 专注于仅提取有用且重要的细节
考虑到这些要求,我们不会进行任何微调。相反,我们将结合现有技术并将它们堆叠在一起,以便快速准确地获得任何格式和语言的结果。
作为基准,我注意到示例网站在大约 3-4 秒内处理发票。因此,在我们的系统中10秒的目标是完全可以实现的。
输出格式应与示例网站上使用的格式匹配:
查特普特
好吧,我们来谈谈第一个工具:ChatGPT。您可能已经知道它的使用有多么简单。那么,为什么还要阅读这个博客呢?好吧,如果我告诉您我可以帮助您优化令牌使用并加快处理速度呢?感兴趣了吗?请稍等——我会解释如何做。
基本方法
这是一个基本的代码片段。 (注意:代码可能并不完美——这更多的是关于想法而不是确切的实现)。您可以在我的存储库多语言发票 OCR 存储库中查看完整代码。
class OpenAIExtractor(BaseExtractor):
def __init__(self, config_path: str = "config/config.yaml"):
super().__init__(config_path)
self.config = self.config['openai']
self.model = self.config['model_name']
self.temperature = self.config['temperature']
self.max_tokens = self.config['max_tokens']
self.OPENAI_API_KEY = os.getenv('OPENAI_API_KEY')
from openai import OpenAI
self.client = OpenAI(api_key=self.OPENAI_API_KEY)
def _extract_invoice_llm(self, ocr_text, base64_image:str, invoice_template:str):
response = self.client.chat.completions.create(
model=self.model,
messages=[
{"role": "system", "content": """You are a helpful assistant that responds in JSON format with the invoice information in English.
Don't add any annotations there. Remember to close any bracket. Number, price and amount should be number, date should be convert to dd/mm/yyyy,
time should be convert to HH:mm:ss, currency should be 3 chracters like VND, USD, EUR"""},
{"role": "user", "content": [
{"type": "text", "text": f"From the image of the bill and the text from OCR, extract the information. The ocr text is: {ocr_text} \n. Return the key names as in the template is a MUST. The invoice template: \n {invoice_template}"},
{"type": "image_url", "image_url": {"url": f"data:image/png;base64,{base64_image}"}}
]}
],
temperature=self.temperature,
max_tokens=self.max_tokens,
)
return response.choices[0].message.content
def extract_json(self, text: str) -> dict:
start_index = text.find('{')
end_index = text.rfind('}') + 1
json_string = text[start_index:end_index]
json_string = json_string.replace('true', 'True').replace('false', 'False').replace('null', 'None')
result = eval(json_string)
return result
@retry_on_failure(max_retries=3, delay=1.0)
def extract_invoice(self, ocr_text, image: Union[str, np.ndarray], invoice_template:str) -> dict:
base64_image = self.encode_image(image)
invoice_info = self._extract_invoice_llm(ocr_text, base64_image,
invoice_template=invoice_template)
invoice_info = self.extract_json(invoice_info)
return invoice_info
好的,让我们看看结果
invoice {
"invoice_info": {
"amount": 32.0,
"amount_change": 0,
"amount_shipping": 0,
"vatamount": 0,
"amountexvat": 32.0,
"currency": "EUR",
"purchasedate": "28/06/2008",
"purchasetime": "17:46:26",
"vatitems": [
{
"amount": 32.0,
"amount_excl_vat": 32.0,
"amount_incl_vat": 32.0,
"amount_incl_excl_vat_estimated": false,
"percentage": 0,
"code": ""
}
],
"vat_context": "",
"lines": [
{
"description": "",
"lineitems": [
{
"title": "Lunettes",
"description": "",
"amount": 22.0,
"amount_each": 22.0,
"amount_ex_vat": 22.0,
"vat_amount": 0,
"vat_percentage": 0,
"quantity": 1,
"unit_of_measurement": "",
"sku": "",
"vat_code": ""
},
{
"title": "Chapeau",
"description": "",
"amount": 10.0,
"amount_each": 10.0,
"amount_ex_vat": 10.0,
"vat_amount": 0,
"vat_percentage": 0,
"quantity": 1,
"unit_of_measurement": "",
"sku": "",
"vat_code": ""
}
]
}
],
"paymentmethod": "CB EMV",
"payment_auth_code": "",
"payment_card_number": "",
"payment_card_account_number": "",
"payment_card_bank": "",
"payment_card_issuer": "",
"payment_due_date": "",
"terminal_number": "",
"document_subject": "",
"package_number": "",
"invoice_number": "",
"receipt_number": "000130",
"shop_number": "",
"transaction_number": "000148",
"transaction_reference": "",
"order_number": "",
"table_number": "",
"table_group": "",
"merchant_name": "G\u00e9ant Casino",
"merchant_id": "",
"merchant_coc_number": "",
"merchant_vat_number": "",
"merchant_bank_account_number": "",
"merchant_bank_account_number_bic": "",
"merchant_chain_liability_bank_account_number": "",
"merchant_chain_liability_amount": 0,
"merchant_bank_domestic_account_number": "",
"merchant_bank_domestic_bank_code": "",
"merchant_website": "",
"merchant_email": "",
"merchant_address": "Annecy",
"merchant_phone": "04.50.88.20.00",
"customer_name": "",
"customer_address": "",
"customer_phone": "",
"customer_website": "",
"customer_vat_number": "",
"customer_coc_number": "",
"customer_bank_account_number": "",
"customer_bank_account_number_bic": "",
"customer_email": "",
"document_language": ""
}
}
Test_Openai_Invoice Took 0:00:11.15
结果非常可靠,但处理时间是一个问题——它超出了我们的 10 秒限制。您可能还会注意到,输出包含大量空字段,这不仅会增加处理时间,还会引入错误并消耗更多令牌 - 本质上会花费更多金钱。
先进的方法
事实证明,我们只需要一个小小的调整就可以解决这个问题。
只需将以下句子添加到您的提示中:
“只输出有值的字段,不返回任何空字段。”
瞧!问题解决了!
invoice_info {
"invoice_info": {
"amount": 32,
"currency": "EUR",
"purchasedate": "28/06/2008",
"purchasetime": "17:46:26",
"lines": [
{
"description": "",
"lineitems": [
{
"title": "LUNETTES",
"description": "",
"amount": 22,
"amount_each": 22,
"amount_ex_vat": 22,
"vat_amount": 0,
"vat_percentage": 0,
"quantity": 1,
"unit_of_measurement": "",
"sku": "",
"vat_code": ""
},
{
"title": "CHAPEAU",
"description": "",
"amount": 10,
"amount_each": 10,
"amount_ex_vat": 10,
"vat_amount": 0,
"vat_percentage": 0,
"quantity": 1,
"unit_of_measurement": "",
"sku": "",
"vat_code": ""
}
]
}
],
"invoice_number": "000130"
}
}
Test_Openai_Invoice Took 0:00:05.79
哇,这真是一个改变游戏规则的人!现在结果更短、更精确,处理时间从 11.15 秒下降到仅 5.79 秒。通过这一单句调整,我们将成本和处理时间减少了约 50%。很酷吧?
在本例中,我使用的是 GPT-4o-mini,效果很好,但根据我的经验,Gemini Flash 表现更好 - 更快且免费!绝对值得一看。
您可以通过缩短模板来进一步优化,根据您的具体要求仅关注最重要的字段。
桨OCR
结果看起来相当不错,但仍然有一些缺失的字段,例如电话号码或收银员姓名,我们也想捕获这些字段。虽然我们可以简单地重新提示 ChatGPT,但仅依赖 LLM 可能是不可预测的 - 每次运行的结果可能会有所不同。此外,提示模板相当长(因为我们试图提取所有格式的所有可能信息),这可能会导致 ChatGPT “忘记”某些细节。
这就是 PaddleOCR 的用武之地 - 它通过提供精确的 OCR 文本来增强 LLM 的视觉能力,帮助模型准确地专注于需要提取的内容。
In my previous prompt, I used this structure:
{"type": "text", "text": f"From the image of the bill and the text from OCR, extract the information. The ocr text is: {ocr_text} \n.
Previously, I set ocr_text = '', but now we'll populate it with the output from PaddleOCR. Since I'm unsure of the specific language for now, I'll use English (as it's the most commonly supported). In the next part, I’ll guide you on detecting the language, so hang tight!
Here’s the updated code to integrate PaddleOCR:
ocr = PaddleOCR(lang='en', show_log=False, use_angle_cls=True, cls=True) result = ocr.ocr(np.array(image))
This is the OCR output.
"Geant Casino ANNECY BIENVENUE DANS NOTRE MAGASIN Caisse014 Date28/06/2008 VOTRE MAGASIN VOUS ACCUEILLE DU LUNDI AU SAMEDI DE 8H30 A21H00 TEL.04.50.88.20.00 LUNETTES 22.00E CHAPEAU 10.00E =TOTAL2) 32.00E CB EMV 32.00E Si vous aviez la carte fidelite, vous auriez cumule 11SMILES Caissier:000148/Heure:17:46:26 Numero de ticket :000130 Rapidite,confort d'achat budget maitrise.. Scan' Express vous attend!! Merci de votre visite A bientot"
As you can see, the results are pretty good. In this case, the invoice is in French, which looks similar to English, so the output is decent. However, if we were dealing with languages like Japanese or Chinese, the results wouldn't be as accurate.
Now, let’s see what happens when we combine the OCR output with ChatGPT.
invoice_info {
"invoice_info": {
"amount": 32,
"currency": "EUR",
"purchasedate": "28/06/2008",
"purchasetime": "17:46:26",
"lines": [
{
"description": "",
"lineitems": [
{
"title": "LUNETTES",
"description": "",
"amount": 22,
"amount_each": 22,
"amount_ex_vat": 22,
"vat_amount": 0,
"vat_percentage": 0,
"quantity": 1,
"unit_of_measurement": "",
"sku": "",
"vat_code": ""
},
{
"title": "CHAPEAU",
"description": "",
"amount": 10,
"amount_each": 10,
"amount_ex_vat": 10,
"vat_amount": 0,
"vat_percentage": 0,
"quantity": 1,
"unit_of_measurement": "",
"sku": "",
"vat_code": ""
}
]
}
],
"paymentmethod": "CB EMV",
"receipt_number": "000130",
"transaction_number": "000130",
"merchant_name": "G\u00e9ant Casino",
"customer_email": "",
"customer_name": "",
"customer_address": "",
"customer_phone": ""
}
}
Test_Openai_Invoice Took 0:00:06.78
Awesome! It uses a few more tokens and takes slightly longer, but it returns additional fields like payment_method, receipt_number, and cashier. That’s a fair trade-off and totally acceptable!
Language Detection
Right now, we’re facing two major challenges. First, PaddleOCR cannot automatically detect the language, which significantly affects the OCR output, and ultimately impacts the entire result. Second, most LLMs perform best with English, so if the input is in another language, the quality of the results decreases.
To demonstrate, I’ll use a challenging example.
Here’s a Japanese invoice:

Let’s see what happens if we fail to auto-detect the language and use lang='en' to extract OCR on this Japanese invoice.
The result
'TEL045-752-6131 E TOP&CIubQJMB-FJ 2003 20130902 LNo.0102 No0073 0011319-2x198 396 00327111 238 000805 VR-E--E 298 003276 9 -435 298 001093 398 000335 138 000112 7 2x158 316 A000191 92 29 t 2.111 100) 10.001 10.001 7.890'
As you can see, the result is pretty bad.
Now, let’s detect the language using a zero-shot classification model. In this case, I’m using "facebook/metaclip-b32-400m". This is one of the best ways to detect around 80 languages supported by PaddleOCR without needing fine-tuning while still maintaining accuracy.
def initialize_language_detector(self):
# Initialize the zero-shot image classification model
self.image_classifier = pipeline(task="zero-shot-image-classification",
model="facebook/metaclip-b32-400m",
device=self.device,
batch_size=8)
def _get_lang(self, image: Image.Image) -> str:
# Define candidate labels for language classification
candidate_labels = [f"language {key}" for key in self.language_dict]
# Perform inference to classify the language
outputs = self.image_classifier(image, candidate_labels=candidate_labels)
outputs = [{"score": round(output["score"], 4), "label": output["label"] } for output in outputs]
# Extract the language with the highest score
language_names = [entry['label'].replace('language ', '') for entry in outputs]
scores = [entry['score'] for entry in outputs]
abbreviations = [self.language_dict.get(language) for language in language_names]
first_abbreviation = abbreviations[0]
lang = 'en' # Default to English
if scores[0] > self.language_thresh:
lang = first_abbreviation
print("The source language", abbreviations)
return lang
Let's see the result
Recognized Text:
{'ori_text': '根岸 東急ストア TEL 045-752-6131 領収証 [TOP2C!UbO J3カード」 クレヅッ 卜でのお支払なら 200円で3ボイン卜 お得なカード! 是非こ入会下さい。 2013年09月02日(月) レジNO. 0102 NOO07さ と う 001131 スダフエウ卜チーネ 23 単198 1396 003271 オインイ年 ユウ10 4238 000805 ソマ一ク スモー一クサーモン 1298 003276 タカナン ナマクリーム35 1298 001093 ヌテラ スフレクト 1398 000335 バナサ 138 000112 アボト 2つ 単158 1316 A000191 タマネキ 429 合計 2,111 (内消費税等 100 現金 10001 お預り合計 110 001 お釣り 7 890',
'ori_language': 'ja',
'text': 'Negishi Tokyu Store TEL 045-752-6131 Receipt [TOP2C!UbO J3 Card] If you pay with a credit card, you can get 3 points for 200 yen.A great value card!Please join us. Monday, September 2, 2013 Cashier No. 0102 NOO07 Satou 001131 Sudafue Bucine 23 Single 198 1396 003271 Oinyen Yu 10 4238 000805 Soma Iku Smo Iku Salmon 1298 003276 Takanan Nama Cream 35 1 298 001093 Nutella Sprect 1398 000335 Banasa 138 000112 Aboto 2 AA 158 1316 A000191 Eggplant 429 Total 2,111 (including consumption tax, etc. 100 Cash 10001 Total deposited 110 001 Change 7 890',
'language': 'en',}
The results are much better now! I also translated the original Japanese into English. With this approach, the output will significantly improve for other languages as well.
Summary
In this blog, we explored how to extract key information from invoices by combining LLMs and OCR, while also optimizing processing time, minimizing token usage, and improving multilingual support. By incorporating PaddleOCR and a zero-shot language detection model, we boosted both accuracy and reliability across different formats and languages. I hope these examples help you grasp the full process, from initial concept to final implementation.
Reference:
Mrzaizai2k - Multilanguage invoice ocr
More
If you’d like to learn more, be sure to check out my other posts and give me a like! It would mean a lot to me. Thank you.
- Real-Time Data Processing with MongoDB Change Streams and Python
- Replay Attack: Let’s Learn
- Reasons to Write
以上是关键信息提取的实用方法(第 1 部分)的详细内容。更多信息请关注PHP中文网其他相关文章!

 Python vs. C:了解关键差异Apr 21, 2025 am 12:18 AM
Python vs. C:了解关键差异Apr 21, 2025 am 12:18 AMPython和C 各有优势,选择应基于项目需求。1)Python适合快速开发和数据处理,因其简洁语法和动态类型。2)C 适用于高性能和系统编程,因其静态类型和手动内存管理。
 Python vs.C:您的项目选择哪种语言?Apr 21, 2025 am 12:17 AM
Python vs.C:您的项目选择哪种语言?Apr 21, 2025 am 12:17 AM选择Python还是C 取决于项目需求:1)如果需要快速开发、数据处理和原型设计,选择Python;2)如果需要高性能、低延迟和接近硬件的控制,选择C 。
 达到python目标:每天2小时的力量Apr 20, 2025 am 12:21 AM
达到python目标:每天2小时的力量Apr 20, 2025 am 12:21 AM通过每天投入2小时的Python学习,可以有效提升编程技能。1.学习新知识:阅读文档或观看教程。2.实践:编写代码和完成练习。3.复习:巩固所学内容。4.项目实践:应用所学于实际项目中。这样的结构化学习计划能帮助你系统掌握Python并实现职业目标。
 最大化2小时:有效的Python学习策略Apr 20, 2025 am 12:20 AM
最大化2小时:有效的Python学习策略Apr 20, 2025 am 12:20 AM在两小时内高效学习Python的方法包括:1.回顾基础知识,确保熟悉Python的安装和基本语法;2.理解Python的核心概念,如变量、列表、函数等;3.通过使用示例掌握基本和高级用法;4.学习常见错误与调试技巧;5.应用性能优化与最佳实践,如使用列表推导式和遵循PEP8风格指南。
 在Python和C之间进行选择:适合您的语言Apr 20, 2025 am 12:20 AM
在Python和C之间进行选择:适合您的语言Apr 20, 2025 am 12:20 AMPython适合初学者和数据科学,C 适用于系统编程和游戏开发。1.Python简洁易用,适用于数据科学和Web开发。2.C 提供高性能和控制力,适用于游戏开发和系统编程。选择应基于项目需求和个人兴趣。
 Python与C:编程语言的比较分析Apr 20, 2025 am 12:14 AM
Python与C:编程语言的比较分析Apr 20, 2025 am 12:14 AMPython更适合数据科学和快速开发,C 更适合高性能和系统编程。1.Python语法简洁,易于学习,适用于数据处理和科学计算。2.C 语法复杂,但性能优越,常用于游戏开发和系统编程。
 每天2小时:Python学习的潜力Apr 20, 2025 am 12:14 AM
每天2小时:Python学习的潜力Apr 20, 2025 am 12:14 AM每天投入两小时学习Python是可行的。1.学习新知识:用一小时学习新概念,如列表和字典。2.实践和练习:用一小时进行编程练习,如编写小程序。通过合理规划和坚持不懈,你可以在短时间内掌握Python的核心概念。
 Python与C:学习曲线和易用性Apr 19, 2025 am 12:20 AM
Python与C:学习曲线和易用性Apr 19, 2025 am 12:20 AMPython更易学且易用,C 则更强大但复杂。1.Python语法简洁,适合初学者,动态类型和自动内存管理使其易用,但可能导致运行时错误。2.C 提供低级控制和高级特性,适合高性能应用,但学习门槛高,需手动管理内存和类型安全。


热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

Video Face Swap
使用我们完全免费的人工智能换脸工具轻松在任何视频中换脸!

热门文章
热工具

螳螂BT
Mantis是一个易于部署的基于Web的缺陷跟踪工具,用于帮助产品缺陷跟踪。它需要PHP、MySQL和一个Web服务器。请查看我们的演示和托管服务。

EditPlus 中文破解版
体积小,语法高亮,不支持代码提示功能

ZendStudio 13.5.1 Mac
功能强大的PHP集成开发环境

安全考试浏览器
Safe Exam Browser是一个安全的浏览器环境,用于安全地进行在线考试。该软件将任何计算机变成一个安全的工作站。它控制对任何实用工具的访问,并防止学生使用未经授权的资源。

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)

