



Filing an issue
For my first contribution, I filed an issue to add a new feature to another project which is to add a new flag option to display the tokens used for the prompt and the completion generation.
 Feat: chat completion token info flag option
#8
Feat: chat completion token info flag option
#8
 Feat: chat completion token info flag option
#8
Feat: chat completion token info flag option
#8

Description
A flag option that gives the user a count of tokens sent and received. I think that it is an important feature that guides the user to stay within the token budget when making a chat completions request!
Implementation
To do this, we would need to add another option flag which could be -t and --token-usage. When a user includes this flag to their command, it should display in clear detail how many tokens were used in the generation of the completion, and how many tokens were used in the prompt.
I chose to contribute to fadingNA's open source project, chat-minal, a CLI tool written in Python that allows you to leverage OpenAI to do various things, such as using it to generate a code review, file conversion, generating markdown from text, and summarizing text.
My pull request
I have written code in Python before, but it is not my strongest skill. So contributing to this project provides a challenging but good learning experience for me.
The challenge is that I would have to read and understand someone else's code, and provide a proper solution in a way that it does not break the design of the code. Understanding the flow is crucial so that I can efficiently add the feature without having to make big changes in the code and keep the code consistent.
FEAT: Token usage flag
#9
Feature
Added the feature to include a --token_usage flag option for the user. This option gives the user the information of how many tokens were used for the prompt and generated completion.
Implementation
The solution I came up with based on the code design is to check for the existence of the token_usage flag. I do not want the code to check any unnecessary if statements if the token_usage flag was not used, so I made two separate identical loop logic, with the difference of checking the the existence of usage_metadata inside chunk.
if token_usage:
for chunk in runnable.stream({"input_text": input_text}):
print(chunk.content, end="", flush=True)
answer.append(chunk.content)
if chunk.usage_metadata:
completion_tokens = chunk.usage_metadata.get('output_tokens')
prompt_tokens = chunk.usage_metadata.get('input_tokens')
else:
for chunk in runnable.stream({"input_text": input_text}):
print(chunk.content, end="", flush=True)
answer.append(chunk.content)
Display
At the end of the execution of get_completions() method, a check for the flag token_usage is added, which then displays the token usage details to stderr if the flag was used.
if token_usage:
logger.error(f"Tokens used for completion: <span class="pl-s1"><span class="pl-kos">{completion_tokens}</span>"</span>)
logger.error(f"Tokens used for prompt: <span class="pl-s1"><span class="pl-kos">{prompt_tokens}</span>"</span>)
My solution
Retrieving the token usage
if token_usage:
for chunk in runnable.stream({"input_text": input_text}):
print(chunk.content, end="", flush=True)
answer.append(chunk.content)
if chunk.usage_metadata:
completion_tokens = chunk.usage_metadata.get('output_tokens')
prompt_tokens = chunk.usage_metadata.get('input_tokens')
else:
for chunk in runnable.stream({"input_text": input_text}):
print(chunk.content, end="", flush=True)
answer.append(chunk.content)
Originally, the code only had one for loop which retrieves the content from a stream and appends it to an array which forms the response of the completion.
Why did I write it this way?
My reasoning behind duplicating the for while adding the distinct if block is to prevent the code from repeatedly checking the if block even if the user is not using the newly added --token_usage flag. So instead, I check for the existence of the flag firstly, and then decide which for loop to execute.
Realization
Even though my pull request has been accepted by the project owner, I realized late that this way adds complexity to the code's maintainability. For example, if there are changes required in the for loop for processing the stream, that means modifying the code twice since there are two identical for loops.
What I think I could do as an improvement for it is to make it into a function so that any changes required can be done in one function only, keeping the maintainability of the code. This just proves that even if I wrote the code with optimization in mind, there are still other things that I can miss which is crucial to a project, which in this case, is maintainability.
Receiving a pull request
My tool, genereadme, also received a contribution. I received a PR from Mounayer, which is to add the same feature to my project.
feat: added a new flag that displays the number of tokens sent in prompt and received in completion
#13

Description
Closes #12.
- Added a new flag --token-usage which when given, prints the number of tokens that were sent in the prompt and the number of tokens that were returned in the completion to `stderr.
This simply required the addition for another flag check --token-usage:
.option("--token-usage", "Show prompt and completion token usage")
I've also made sure to keep your naming conventions/formatting style consistent, in the for loop that does the chat completion for each file processed, I have accumulated the total tokens sent and received:
promptTokens += response.usage.prompt_tokens;
completionTokens += response.usage.completion_tokens;
which I then display at the end of program run-time if the --token-usage flag is provided as such:
if (program.opts().tokenUsage) {
console.error(`Prompt tokens: <span class="pl-s1"><span class="pl-kos">${promptTokens}</span>`</span>);
console.error(`Completion tokens: <span class="pl-s1"><span class="pl-kos">${completionTokens}</span>`</span>);
}
- Updated README.md to explain the new flag.
Testing
Test 1
genereadme examples/sum.js --token-usage
This should display something like:
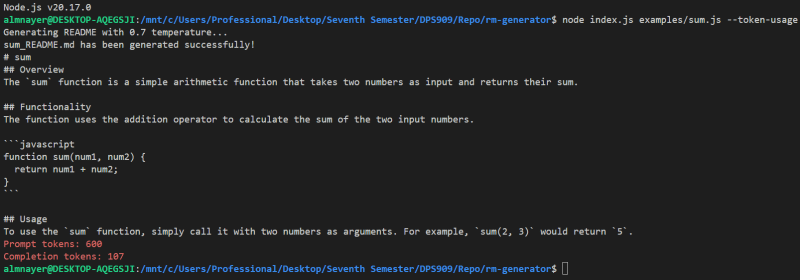
Test 2
You can try it out with multiple files too, i.e.:
genereadme examples/sum.js examples/createUser.js --token-usage
This time, instead of having to read someone else's code, someone had to read mine and contribute to it. It is nice knowing that someone is able to contribute to my project. To me, it means that they understood how my code works, so they were able to add the feature without breaking anything or adding any complexity to the code base.
With that being mentioned, reading code is also a skill that is not to be underestimated. My code is nowhere near perfect and I know there are still places I can improve on, so credit is also due to being able to read and understand code.
This specific pull request did not really require any back and forth changes as the code that was written by Mounayer is what I would have written myself.
以上是My first open source contribution的详细内容。更多信息请关注PHP中文网其他相关文章!

 Python中的合并列表:选择正确的方法May 14, 2025 am 12:11 AM
Python中的合并列表:选择正确的方法May 14, 2025 am 12:11 AMTomergelistsinpython,YouCanusethe操作员,estextMethod,ListComprehension,Oritertools
 如何在Python 3中加入两个列表?May 14, 2025 am 12:09 AM
如何在Python 3中加入两个列表?May 14, 2025 am 12:09 AM在Python3中,可以通过多种方法连接两个列表:1)使用 运算符,适用于小列表,但对大列表效率低;2)使用extend方法,适用于大列表,内存效率高,但会修改原列表;3)使用*运算符,适用于合并多个列表,不修改原列表;4)使用itertools.chain,适用于大数据集,内存效率高。
 Python串联列表字符串May 14, 2025 am 12:08 AM
Python串联列表字符串May 14, 2025 am 12:08 AM使用join()方法是Python中从列表连接字符串最有效的方法。1)使用join()方法高效且易读。2)循环使用 运算符对大列表效率低。3)列表推导式与join()结合适用于需要转换的场景。4)reduce()方法适用于其他类型归约,但对字符串连接效率低。完整句子结束。
 Python执行,那是什么?May 14, 2025 am 12:06 AM
Python执行,那是什么?May 14, 2025 am 12:06 AMpythonexecutionistheprocessoftransformingpypythoncodeintoExecutablestructions.1)InternterPreterReadSthecode,ConvertingTingitIntObyTecode,whepythonvirtualmachine(pvm)theglobalinterpreterpreterpreterpreterlock(gil)the thepythonvirtualmachine(pvm)
 Python:关键功能是什么May 14, 2025 am 12:02 AM
Python:关键功能是什么May 14, 2025 am 12:02 AMPython的关键特性包括:1.语法简洁易懂,适合初学者;2.动态类型系统,提高开发速度;3.丰富的标准库,支持多种任务;4.强大的社区和生态系统,提供广泛支持;5.解释性,适合脚本和快速原型开发;6.多范式支持,适用于各种编程风格。
 Python:编译器还是解释器?May 13, 2025 am 12:10 AM
Python:编译器还是解释器?May 13, 2025 am 12:10 AMPython是解释型语言,但也包含编译过程。1)Python代码先编译成字节码。2)字节码由Python虚拟机解释执行。3)这种混合机制使Python既灵活又高效,但执行速度不如完全编译型语言。
 python用于循环与循环时:何时使用哪个?May 13, 2025 am 12:07 AM
python用于循环与循环时:何时使用哪个?May 13, 2025 am 12:07 AMuseeAforloopWheniteratingOveraseQuenceOrforAspecificnumberoftimes; useAwhiLeLoopWhenconTinuingUntilAcIntiment.ForloopSareIdeAlforkNownsences,而WhileLeleLeleLeleLoopSituationSituationSituationsItuationSuationSituationswithUndEtermentersitations。
 Python循环:最常见的错误May 13, 2025 am 12:07 AM
Python循环:最常见的错误May 13, 2025 am 12:07 AMpythonloopscanleadtoerrorslikeinfiniteloops,modifyingListsDuringteritation,逐个偏置,零indexingissues,andnestedloopineflinefficiencies


热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

Video Face Swap
使用我们完全免费的人工智能换脸工具轻松在任何视频中换脸!

热门文章
热工具

适用于 Eclipse 的 SAP NetWeaver 服务器适配器
将Eclipse与SAP NetWeaver应用服务器集成。

SublimeText3 英文版
推荐:为Win版本,支持代码提示!

SecLists
SecLists是最终安全测试人员的伙伴。它是一个包含各种类型列表的集合,这些列表在安全评估过程中经常使用,都在一个地方。SecLists通过方便地提供安全测试人员可能需要的所有列表,帮助提高安全测试的效率和生产力。列表类型包括用户名、密码、URL、模糊测试有效载荷、敏感数据模式、Web shell等等。测试人员只需将此存储库拉到新的测试机上,他就可以访问到所需的每种类型的列表。

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)

安全考试浏览器
Safe Exam Browser是一个安全的浏览器环境,用于安全地进行在线考试。该软件将任何计算机变成一个安全的工作站。它控制对任何实用工具的访问,并防止学生使用未经授权的资源。

