
Mamba作者新作:将Llama3蒸馏成混合线性 RNN

- 王林原创
- 2024-09-02 13:41:301007浏览
딥 러닝 분야에서 Transformer가 큰 성공을 거둘 수 있었던 열쇠는 어텐션 메커니즘입니다. 어텐션 메커니즘을 통해 Transformer 기반 모델은 입력 시퀀스와 관련된 부분에 집중하여 더 나은 상황 이해를 달성할 수 있습니다. 그러나 어텐션 메커니즘의 단점은 계산 오버헤드가 높고 입력 크기에 따라 2차적으로 증가하여 Transformer가 매우 긴 텍스트를 처리하기 어렵게 만든다는 것입니다.
얼마 전 Mamba의 출현으로 이러한 상황이 깨졌고, 이는 컨텍스트 길이가 증가함에 따라 선형 확장을 달성할 수 있습니다. Mamba가 출시됨에 따라 이러한 상태 공간 모델(SSM)은 이미 중소 규모에서 Transformer와 일치하거나 능가할 수 있을 뿐만 아니라 시퀀스 길이에 대한 선형 확장성을 유지하여 Mamba에 유리한 배포 특성을 제공합니다.
간단히 말하면 Mamba는 먼저 입력에 따라 SSM을 다시 매개변수화할 수 있는 간단하지만 효과적인 선택 메커니즘을 도입하여 모델이 관련 없는 정보 및 관련 데이터를 필터링하면서 필요한 정보를 무기한 유지할 수 있도록 합니다.
최근 "The Mamba in the Llama: Distilling and Acceleating Hybrid Models"라는 제목의 논문에서는 Attention 레이어의 가중치를 재사용함으로써 대형 트랜스포머를 대형 하이브리드 선형 RNN으로 증류할 수 있음을 입증했습니다. 대부분의 빌드 품질을 유지하면서.
주의 계층의 4분의 1을 포함하는 결과 하이브리드 모델은 채팅 벤치마크에서 원래 Transformer와 비슷한 성능을 달성하고 채팅 벤치마크 및 일반 벤치마크의 데이터 사용 성능을 능가합니다. 오픈 소스 하이브리드 Mamba 모델. 1조 개의 토큰으로 처음부터 훈련되었습니다. 또한 이 연구에서는 Mamba 및 하이브리드 모델에 대한 추론 속도를 높이는 하드웨어 인식 추측 디코딩 알고리즘을 제안합니다.

논문 주소: https://arxiv.org/pdf/2408.15237
이 연구에서 가장 성능이 좋은 모델은 Llama3-8B-Instruct Distilled에서 나온 것입니다. , GPT-4에 비해 AlpacaEval 2에서 29.61의 길이 제어 승률을 달성했으며 MT-Bench에서 7.35의 승률을 달성하여 최고의 명령 조정 선형 RNN 모델을 능가했습니다.
방법
KD(Knowledge Distillation)는 대형 모델(교사 모델)에서 소형 모델(학생 모델) 모델로 지식을 전달하는 데 사용되는 모델 압축 기술입니다. ), 이는 교사 네트워크의 행동을 모방하도록 학생 네트워크를 훈련시키는 것을 목표로 합니다. 이 연구의 목표는 Transformer의 성능이 원래 언어 모델과 비슷하도록 증류하는 것입니다.
본 연구에서는 점진적 증류, 감독된 미세 조정 및 방향성 선호 최적화를 결합한 다단계 증류 방법을 제안합니다. 일반 증류와 비교하여 이 방법은 더 나은 혼란과 다운스트림 평가 결과를 얻을 수 있습니다.
본 연구에서는 Transformer의 지식 대부분이 원본 모델에서 전달된 MLP 계층에 유지된다고 가정하고 증류된 LLM의 미세 조정 및 정렬 단계에 중점을 둡니다. 이 단계에서는 MLP 계층이 동결된 상태로 유지되고 Mamba 계층이 훈련됩니다.
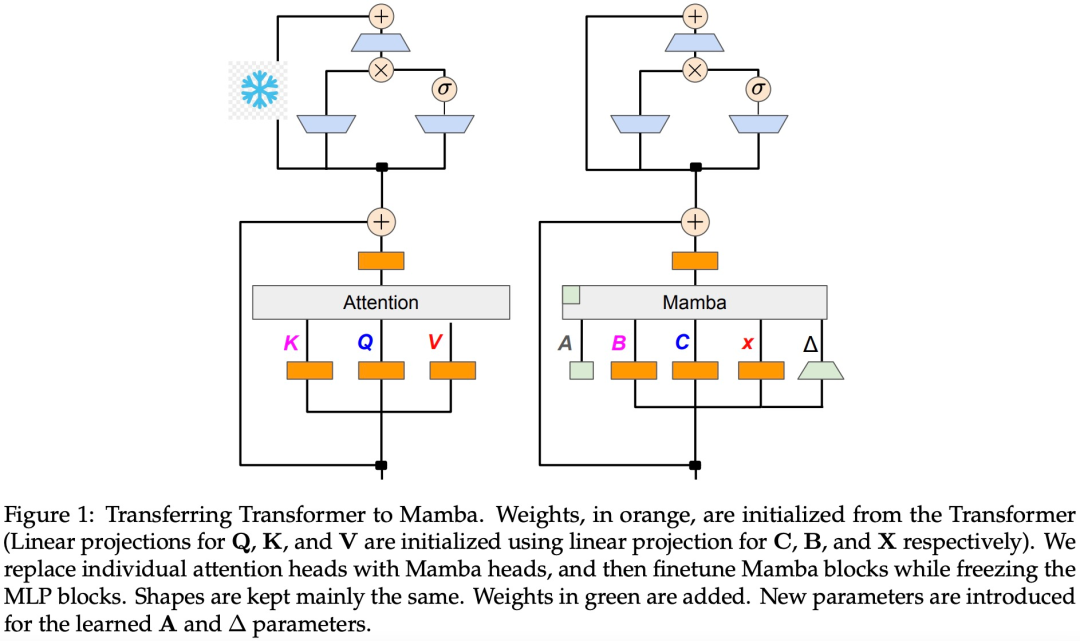
이 연구는 선형 RNN과 주의 메커니즘 사이에 자연스러운 연결이 있다고 믿습니다. 어텐션 공식은 소프트맥스를 제거하여 선형화할 수 있습니다.
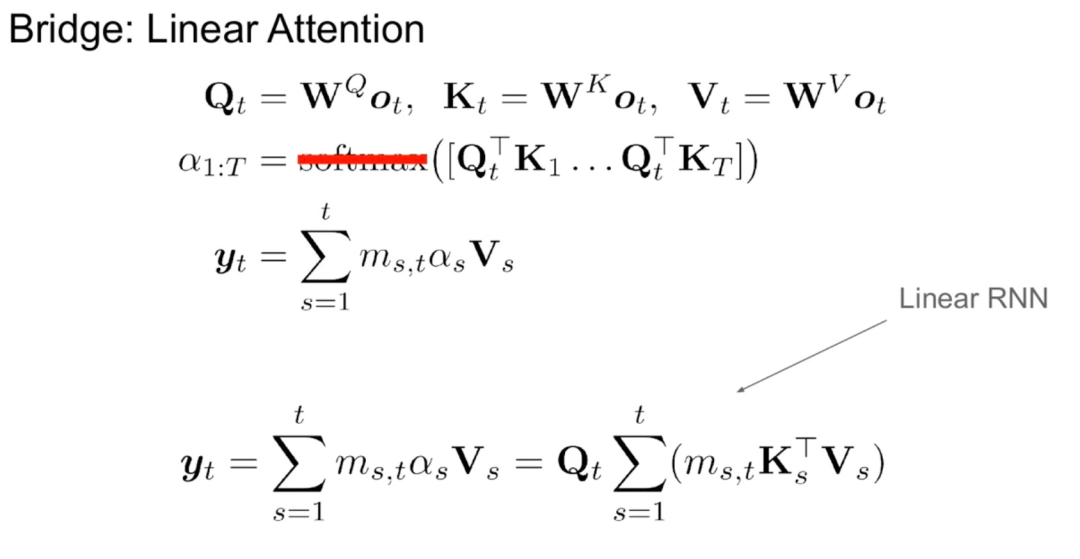
그러나 어텐션을 선형화하면 모델 성능이 저하됩니다. 효율적인 증류 선형 RNN을 설계하기 위해 본 연구에서는 선형 RNN의 용량을 효율적인 방식으로 확장하면서 원래의 Transformer 매개변수화에 최대한 가깝게 접근합니다. 본 연구에서는 새로운 모델이 정확한 원래 주의 함수를 포착하도록 시도하지 않고 대신 선형화된 형태를 증류의 출발점으로 사용합니다.
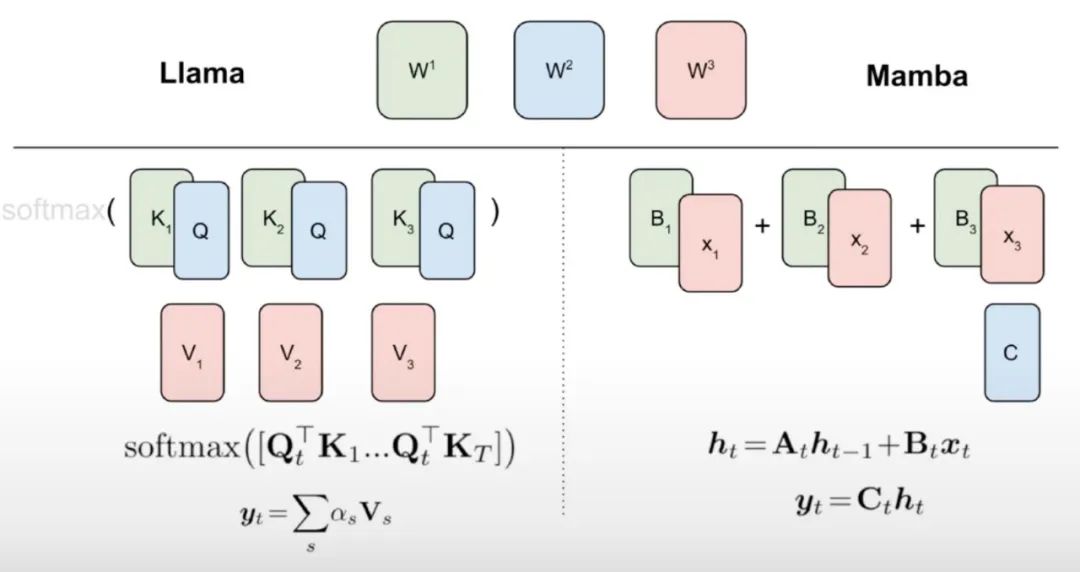
알고리즘 1에서 볼 수 있듯이 이 연구에서는 Attention 메커니즘의 표준 Q, K, V 헤드를 Mamba 이산화에 직접 입력한 다음 결과 선형 RNN을 적용합니다. 이는 대략적인 초기화를 위해 선형 주의를 사용하는 것으로 생각할 수 있으며 모델이 확장된 숨겨진 상태를 통해 더 풍부한 상호 작용을 학습할 수 있도록 합니다.

이 연구에서는 Transformer 어텐션 헤드를 미세 조정된 선형 RNN 레이어로 직접 대체하여 Transformer MLP 레이어를 변경하지 않고 훈련시키지 않습니다. 이 접근 방식은 헤드 간에 키와 값을 공유하는 그룹화된 쿼리 주의와 같은 다른 구성 요소도 처리해야 합니다. 연구팀은 이 아키텍처가 많은 Mamba 시스템에서 사용되는 것과 달리 이 초기화를 통해 모든 주의 블록을 선형 RNN 블록으로 대체할 수 있다는 점에 주목했습니다.
이 연구에서는 하드웨어 인식 다단계 생성을 사용하여 선형 RNN 추측 디코딩을 위한 새로운 알고리즘도 제안합니다.
Algorithmus 2 und Abbildung 2 zeigen den vollständigen Algorithmus. Dieser Ansatz behält nur einen verborgenen RNN-Zustand zur Überprüfung im Cache und treibt ihn basierend auf dem Erfolg des mehrstufigen Kernels langsam voran. Da das Destillationsmodell Transformatorschichten enthält, erweitert diese Studie die spekulative Dekodierung auch auf eine Attention/RNN-Hybridarchitektur. In diesem Aufbau führt die RNN-Schicht eine Verifizierung gemäß Algorithmus 2 durch, während die Transformer-Schicht nur eine parallele Verifizierung durchführt.
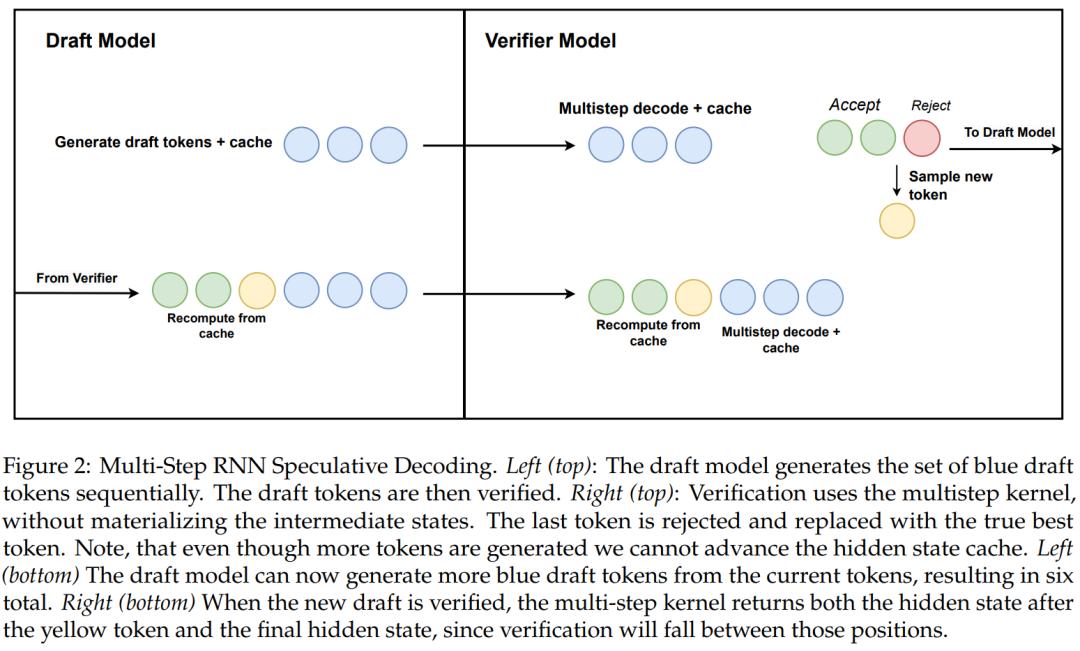

Um die Wirksamkeit dieser Methode zu überprüfen, wurden in der Studie Mamba 7B und Mamba 2.8B als Zielmodelle für Spekulationen verwendet. Die Ergebnisse sind in Tabelle 1 aufgeführt.
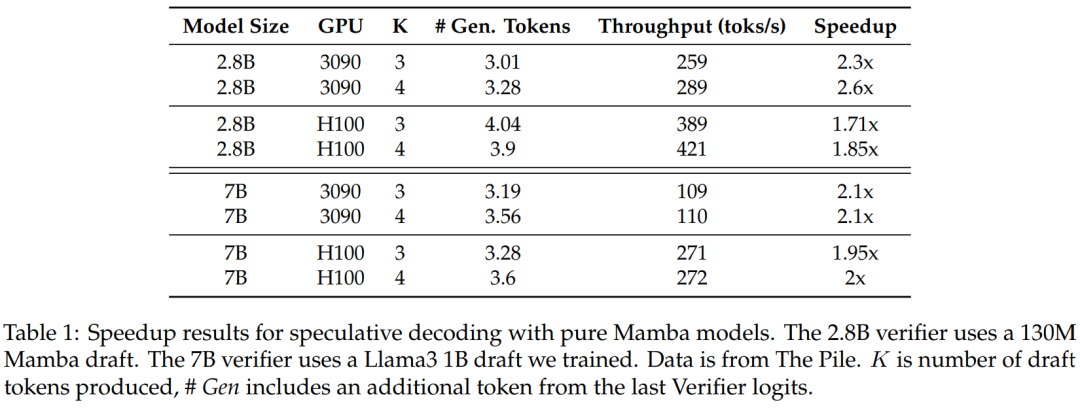
Abbildung 3 zeigt die Leistungsmerkmale des Multi-Step-Kernels selbst.
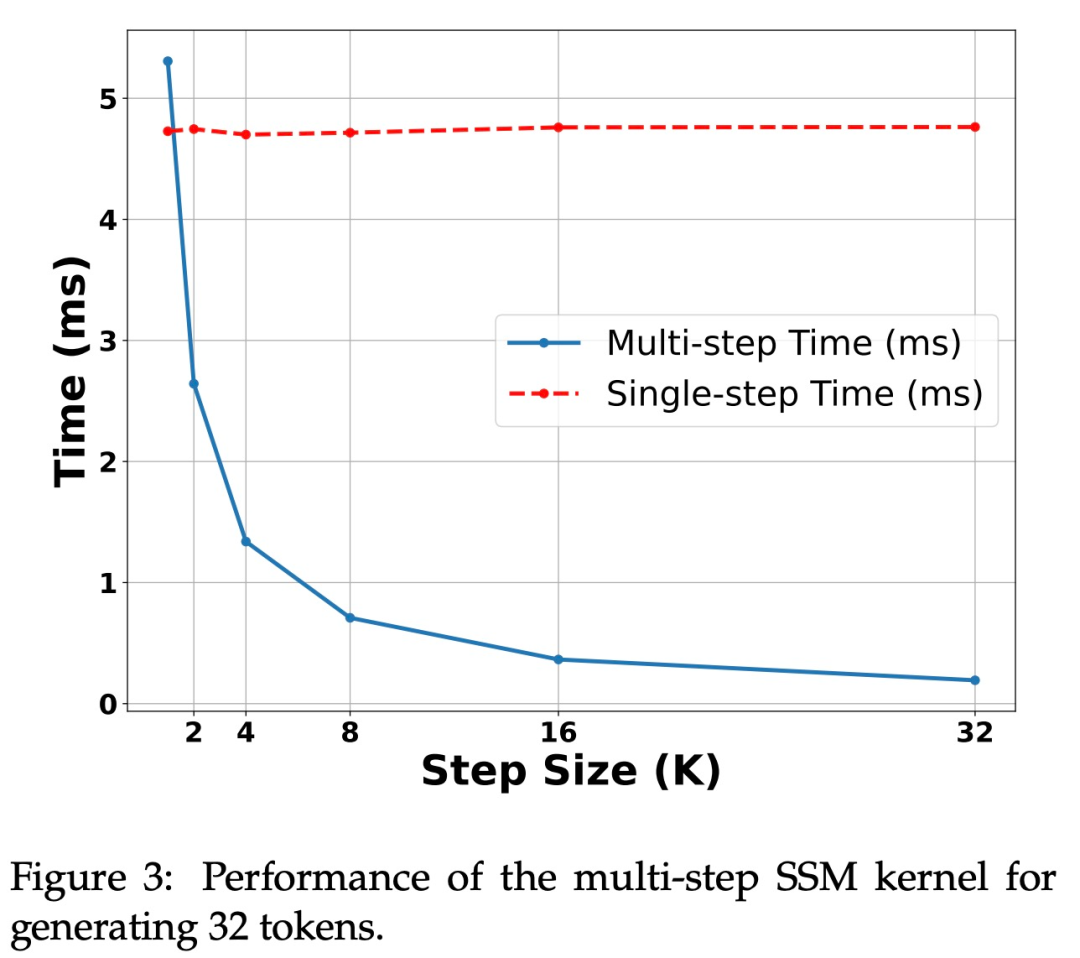
Beschleunigung auf der H100-GPU. Der in dieser Studie vorgeschlagene Algorithmus zeigt eine starke Leistung auf der Ampere-GPU, wie in Tabelle 1 oben gezeigt. Aber es gibt große Herausforderungen für die H100-GPU. Dies liegt hauptsächlich daran, dass GEMM-Operationen zu schnell sind, wodurch der durch Caching- und Neuberechnungsvorgänge verursachte Overhead stärker spürbar wird. Tatsächlich erzielte eine einfache Implementierung des untersuchten Algorithmus (unter Verwendung mehrerer verschiedener Kernel-Aufrufe) eine erhebliche Beschleunigung auf der 3090-GPU, jedoch überhaupt keine Beschleunigung auf der H100.
Experimente und Ergebnisse
Diese Studie verwendet zwei LLM-Chat-Modelle für Experimente: Zephyr-7B basiert auf dem Mistral-7B-Modell und Llama-3 Instruct 8B. Für das lineare RNN-Modell verwendet diese Studie eine Hybridversion von Mamba und Mamba2 mit Aufmerksamkeitsschichten von 50 %, 25 %, 12,5 % bzw. 0 % und nennt 0 % ein reines Mamba-Modell. Mamba2 ist eine Architekturvariante von Mamba, die hauptsächlich für aktuelle GPU-Architekturen entwickelt wurde.
Bewertung beim Chat-Benchmark
Tabelle 2 zeigt die Leistung des Modells beim Chat-Benchmark. Das wichtigste verglichene Modell ist das große Transformer-Modell. Die Ergebnisse zeigen:
Das destillierte Hybrid-Mamba-Modell (50 %) erzielt ähnliche Ergebnisse wie das Lehrermodell im MT-Benchmark und ist hinsichtlich der LC-Gewinnrate und etwas besser als das Lehrermodell im AlpacaEval-Benchmark Gesamtgewinnquote.
Die Leistung der destillierten Hybrid-Mamba (25 % und 12,5 %) ist etwas schlechter als die des Lehrermodells im MT-Benchmark, aber selbst mit mehr Parametern in AlpcaaEval übertrifft sie immer noch einige große Transformer.
Die Genauigkeit des destillierten reinen (0 %) Mamba-Modells nimmt erheblich ab.
Es ist erwähnenswert, dass das destillierte Hybridmodell eine bessere Leistung erbringt als Falcon Mamba, das von Grund auf mit mehr als 5T-Tokens trainiert wird.
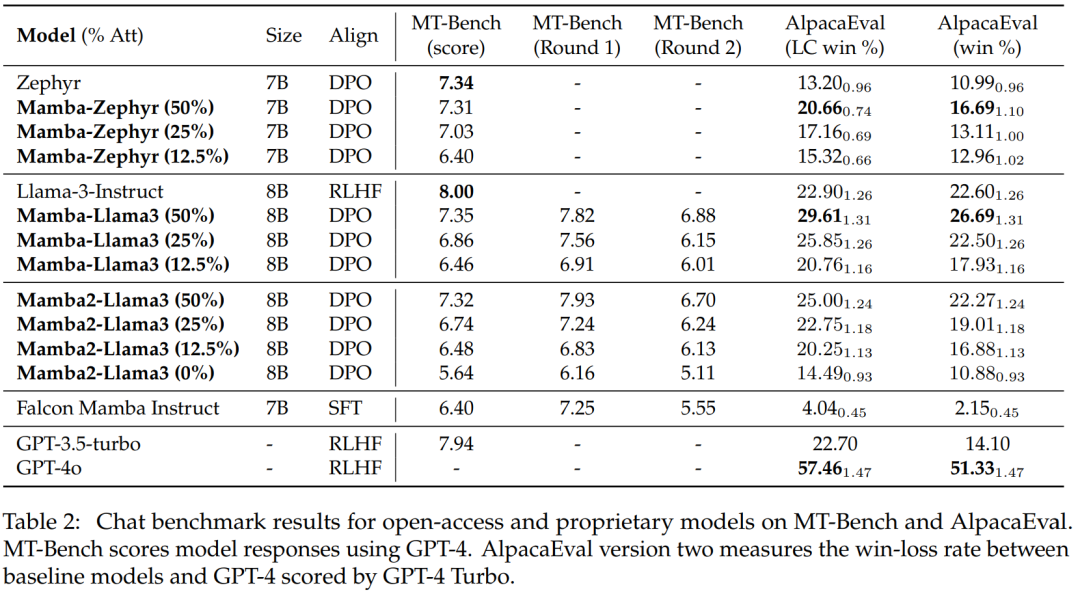
Allgemeine Benchmark-Auswertung
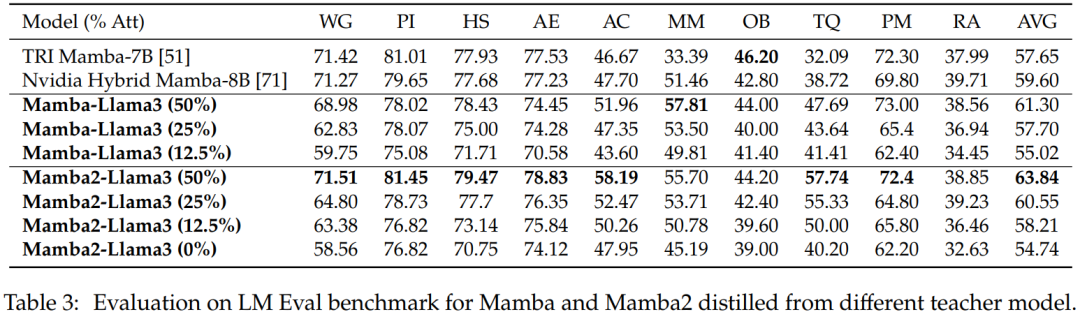
Nullstichprobenauswertung. Tabelle 3 zeigt die Zero-Shot-Leistung von Mamba und Mamba2, destilliert aus verschiedenen Lehrermodellen beim LM Eval-Benchmark. Hybride Mamba-Llama3- und Mamba2-Llama3-Modelle, die aus Llama-3 Instruct 8B destilliert wurden, schneiden besser ab als Open-Source-TRI-Mamba- und Nvidia-Mamba-Modelle, die von Grund auf trainiert wurden.
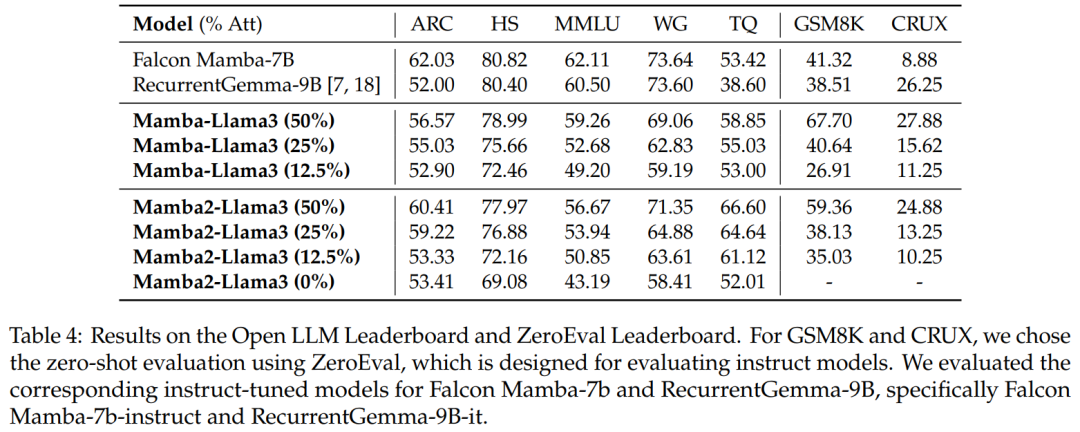
Benchmark-Bewertung. Tabelle 4 zeigt, dass die Leistung des destillierten Hybridmodells mit dem besten linearen Open-Source-RNN-Modell im Open LLM Leaderboard übereinstimmt und gleichzeitig das entsprechende Open-Source-Anweisungsmodell in GSM8K und CRUX übertrifft.
Hybride spekulative Dekodierung
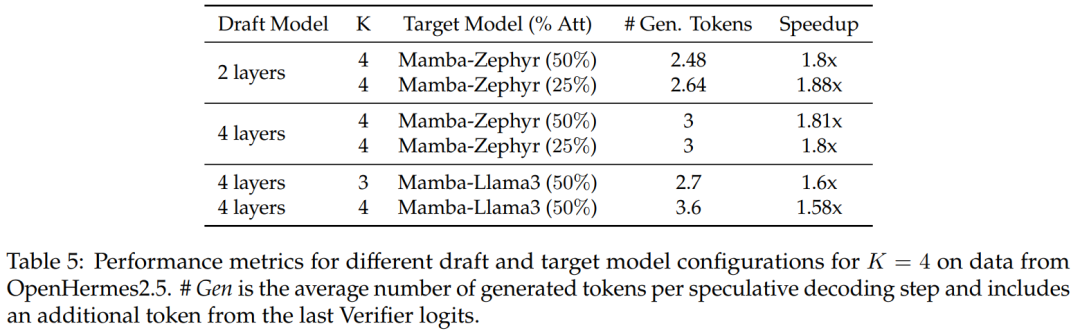
Für die 50 %- und 25 %-Destillationsmodelle im Vergleich zur nicht spekulativen Basislinie, diese Studie Über 1,8-fache Beschleunigung auf Zephyr-Hybrid erreicht.
Experimente zeigen auch, dass das in dieser Studie trainierte 4-Schicht-Entwurfsmodell eine höhere Empfangsrate erreicht, aber aufgrund der Vergrößerung des Entwurfsmodells auch der zusätzliche Overhead größer wird. In der nachfolgenden Arbeit wird sich diese Forschung auf die Verkleinerung dieser Entwurfsmodelle konzentrieren.
Vergleich mit anderen Destillationsmethoden: Tabelle 6 (links) vergleicht die Ratlosigkeit verschiedener Modellvarianten. Die Studie führte eine Destillation innerhalb einer Epoche mit Ultrachat als Samenaufforderung durch und verglich die Verwirrung. Es stellt sich heraus, dass das Entfernen weiterer Schichten die Situation verschlimmert. Die Studie verglich die Destillationsmethode auch mit früheren Basislinien und stellte fest, dass die neue Methode einen geringeren Abbau aufwies, während das Distill Hyena-Modell anhand des WikiText-Datensatzes unter Verwendung eines viel kleineren Modells trainiert wurde und einen größeren Verwirrungsgrad des Abbaus aufwies.
表 6(右)展示了单独使用 SFT 或 DPO 不会产生太大的改进,而使用 SFT + DPO 会产生最佳分数。
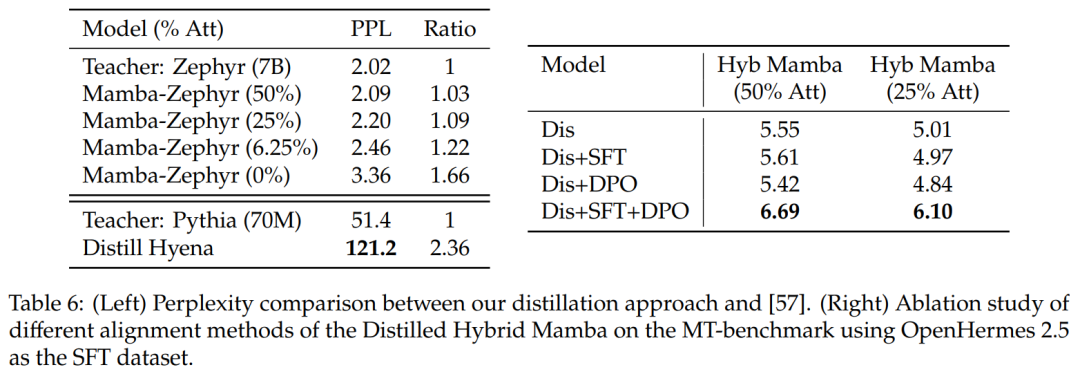
表 7 比较了几种不同模型的消融研究。表 7(左)展示了使用各种初始化的蒸馏结果,表 7(右)显示渐进式蒸馏和将注意层与 Mamba 交错带来的收益较小。
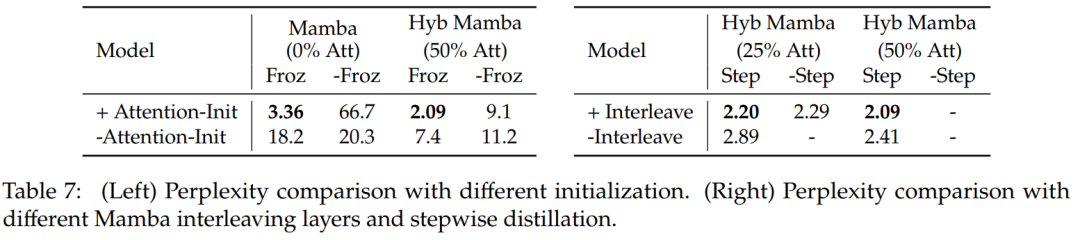
表 8 比较了使用两种不同初始化方法的混合模型的性能:结果证实注意力权重的初始化至关重要。

表 9 比较了有 Mamba 块和没有 Mamba 块的模型的性能。有 Mamba 块的模型性能明显优于没有 Mamba 块的模型。这证实了添加 Mamba 层至关重要,并且性能的提高不仅仅归功于剩余的注意力机制。

感兴趣的读者可以阅读论文原文,了解更多研究内容。
以上是Mamba作者新作:将Llama3蒸馏成混合线性 RNN的详细内容。更多信息请关注PHP中文网其他相关文章!