
构建一个简单的图查询引擎

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB原创
- 2024-08-21 22:47:39667浏览
在过去的 2 篇博客中,我们了解了如何安装 neo4j 并将数据加载到其中。在这篇博客中,我们将了解如何构建一个简单的图形查询引擎来回答我们的问题,但从 neo4j 检索数据。
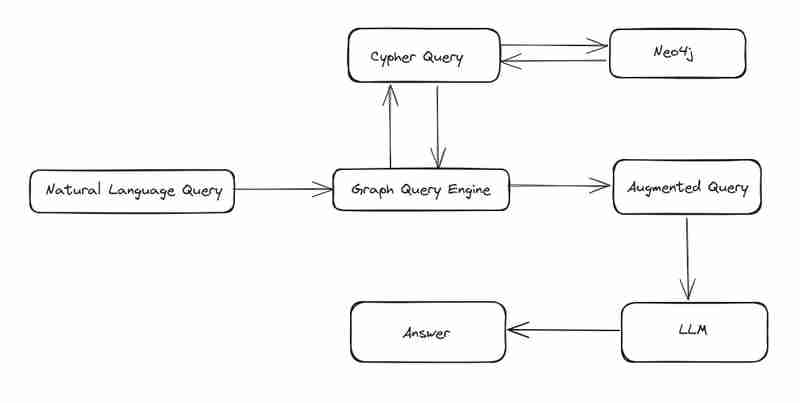
第 1 步:构建 CYPHER 查询
要构建密码查询,我们需要向 GPT 提供架构信息、属性信息以及我们的问题。使用此元数据 GPT 将为我们提供查询。
我已经构建了提示,为每个用户输入返回 3 个查询
- 正则表达式 - 此查询将具有正则表达式模式来匹配 graphDB 中的数据
- 编辑相似度 - 此查询将使用阈值分数大于 0.5 的编辑相似度来匹配并从图形数据库中获取数据。
- 基于嵌入的匹配 - 我们已经将嵌入推送到我们的数据库中,因此此查询将使用用户查询的嵌入,并使用余弦相似度的分数重新排序完整列表。也许这也可以改进以返回前 5 名。
class GraphQueryEngine:
def __init__(self):
self.client = OpenAI(api_key="")
self.url = "bolt://localhost:7687"
self.auth = ("neo4j", "neo4j@123")
def get_response(self, user_input):
"""Used to get cypher queries from user input"""
completion = self.client.beta.chat.completions.parse(
model="gpt-4o-2024-08-06",
messages=[
{"role": "system",
"content": "You are an expert in generating Cypher queries for a Neo4j database. Your task is to understand the input and generate only Cypher read queries. Do not return anything other than the Cypher queries, as the returned result will be executed directly in the database."},
{"role": "user",
"content": f"""
Schema Information:
NODES: Product_type - Contains the distinct types of products such as headphones/mobiles/laptops/washing machines, Product_details - Contains products within a product_type for example apple, samsung within mobiles, DELL within laptops
NODE PROPERTIES: In node Product_type there are name(name of the product type - String), embedding(embedding of the name), and in node Product_details there are name(name of the product - string), price(price of the product - integer), description(description of the product), product_release_date(when product was release on - date), available_stock(stock left - integer), review_rating(product review - float)
DIRECTION OF RELATIONSHIPS: Node Product_type is connected to node Product_details using relationship CONTAINS
Based on the schema, generate three read-only Cypher queries related to Product_type (e.g., chairs, headphones, fridge) or Product_details (e.g., name, description) or combination of both. Ensure that product category uses Product_type and product name/ price
Query 1: Use regular expressions (avoid 'contains') - Exclude the 'embedding' property from the result.
Query 2: Use `apoc.text.levenshteinSimilarity > 0.5` - Exclude the 'embedding' property from the result.
Query 3: Use `gds.similarity.cosine()` to reorder nodes based on similarity scores. The query must include a `%s` placeholder for embedding input but exclude the 'embedding' property in the result.
Generate targeted queries using relationships only when necessary. The embedding property should only be used in the logic and must not appear in the query results.
Strictly return only the Cypher queries with no embeddings. The returned result will be executed directly in the database.
{user_input}
"""},
],
)
response = completion.choices[0].message.content
completion = self.client.beta.chat.completions.parse(
model="gpt-4o-2024-08-06",
messages=[
{"role": "system",
"content": "You are an expert in parsing generating Cypher queries."},
{"role": "user",
"content": f"""Use this input - {response} and parse and return only the cypher queries from the input, ensure that in the cypher query if it returns embeddings then remove the embeddings alone from the query"""},
],
response_format=CypherQuery,
)
event = completion.choices[0].message.parsed
cypher_queries = event.cypher_queries
print("################################## CYPHER QUERIES ######################################")
for query in cypher_queries:
print(query)
return cypher_queries
第 2 步 - 在第三个查询中填充嵌入
- 第三个查询使用 gds.similarity.cosine() 因此我们将用户查询转换为嵌入并将其填充到第三个查询中
def populate_embedding_in_query(self, user_input, cypher_queries):
"""Used to add embeddings of the user input in the 3rd query"""
model = "text-embedding-3-small"
user_input = user_input.replace("\n", " ")
embeddings = self.client.embeddings.create(input=[user_input], model=model).data[0].embedding
cypher_queries[2] = cypher_queries[2] % embeddings
return cypher_queries
第 3 步 - 查询数据库
- 使用准备好的密码查询查询数据库
def execute_read_query(self, query):
"""Execute the cypher query"""
results = []
with GraphDatabase.driver(self.url, auth=self.auth) as driver:
with driver.session() as session:
try:
result = session.run(query)
# Collect the result from the read query
records = [record.data() for record in result]
if records:
results.append(records)
except Exception as error:
print(f"Error in executing query")
return results
def fetch_data(self, cypher_queries):
"""Return the fetched data from DB post formatting"""
results = None
for idx in range(len(cypher_queries)):
try:
results = self.execute_read_query(cypher_queries[idx])
if results:
if idx == len(cypher_queries) - 1:
results = results[0][:10]
break
except Exception:
pass
return results
第 4 步 - 增强一代
- 使用获取的数据命中GPT,使用增强生成技术,借助增强信息生成用户查询的响应
def get_final_response(self, user_input, fetched_data):
"""Augumented generation using data fetched from DB"""
completion = self.client.beta.chat.completions.parse(
model="gpt-4o-2024-08-06",
messages=[
{"role": "system",
"content": "You are a chatbot for an ecommerce website, you help users to identify their desired products"},
{"role": "user", "content": f"""User query - {user_input}
Use the below metadata to answer my query
{fetched_data}
"""},
],
)
response = completion.choices[0].message.content
return response
完整代码
from openai import OpenAI
from pydantic import BaseModel
from typing import List
from neo4j import GraphDatabase
class CypherQuery(BaseModel):
cypher_queries: List[str]
class GraphQueryEngine:
def __init__(self):
self.client = OpenAI(api_key="")
self.url = "bolt://localhost:7687"
self.auth = ("neo4j", "neo4j@123")
def populate_embedding_in_query(self, user_input, cypher_queries):
"""Used to add embeddings of the user input in the 3rd query"""
model = "text-embedding-3-small"
user_input = user_input.replace("\n", " ")
embeddings = self.client.embeddings.create(input=[user_input], model=model).data[0].embedding
cypher_queries[2] = cypher_queries[2] % embeddings
return cypher_queries
def execute_read_query(self, query):
"""Execute the cypher query"""
results = []
with GraphDatabase.driver(self.url, auth=self.auth) as driver:
with driver.session() as session:
try:
result = session.run(query)
# Collect the result from the read query
records = [record.data() for record in result]
if records:
results.append(records)
except Exception as error:
print(f"Error in executing query")
return results
def get_response(self, user_input):
"""Used to get cypher queries from user input"""
completion = self.client.beta.chat.completions.parse(
model="gpt-4o-2024-08-06",
messages=[
{"role": "system",
"content": "You are an expert in generating Cypher queries for a Neo4j database. Your task is to understand the input and generate only Cypher read queries. Do not return anything other than the Cypher queries, as the returned result will be executed directly in the database."},
{"role": "user",
"content": f"""
Schema Information:
NODES: Product_type - Contains the distinct types of products such as headphones/mobiles/laptops/washing machines, Product_details - Contains products within a product_type for example apple, samsung within mobiles, DELL within laptops
NODE PROPERTIES: In node Product_type there are name(name of the product type - String), embedding(embedding of the name), and in node Product_details there are name(name of the product - string), price(price of the product - integer), description(description of the product), product_release_date(when product was release on - date), available_stock(stock left - integer), review_rating(product review - float)
DIRECTION OF RELATIONSHIPS: Node Product_type is connected to node Product_details using relationship CONTAINS
Based on the schema, generate three read-only Cypher queries related to Product_type (e.g., chairs, headphones, fridge) or Product_details (e.g., name, description) or combination of both. Ensure that product category uses Product_type and product name/ price
Query 1: Use regular expressions (avoid 'contains') - Exclude the 'embedding' property from the result.
Query 2: Use `apoc.text.levenshteinSimilarity > 0.5` - Exclude the 'embedding' property from the result.
Query 3: Use `gds.similarity.cosine()` to reorder nodes based on similarity scores. The query must include a `%s` placeholder for embedding input but exclude the 'embedding' property in the result.
Generate targeted queries using relationships only when necessary. The embedding property should only be used in the logic and must not appear in the query results.
Strictly return only the Cypher queries with no embeddings. The returned result will be executed directly in the database.
{user_input}
"""},
],
)
response = completion.choices[0].message.content
completion = self.client.beta.chat.completions.parse(
model="gpt-4o-2024-08-06",
messages=[
{"role": "system",
"content": "You are an expert in parsing generating Cypher queries."},
{"role": "user",
"content": f"""Use this input - {response} and parse and return only the cypher queries from the input, ensure that in the cypher query if it returns embeddings then remove the embeddings alone from the query"""},
],
response_format=CypherQuery,
)
event = completion.choices[0].message.parsed
cypher_queries = event.cypher_queries
print("################################## CYPHER QUERIES ######################################")
for query in cypher_queries:
print(query)
return cypher_queries
def get_final_response(self, user_input, fetched_data):
"""Augumented generation using data fetched from DB"""
completion = self.client.beta.chat.completions.parse(
model="gpt-4o-2024-08-06",
messages=[
{"role": "system",
"content": "You are a chatbot for an ecommerce website, you help users to identify their desired products"},
{"role": "user", "content": f"""User query - {user_input}
Use the below metadata to answer my query
{fetched_data}
"""},
],
)
response = completion.choices[0].message.content
return response
def fetch_data(self, cypher_queries):
"""Return the fetched data from DB post formatting"""
results = None
for idx in range(len(cypher_queries)):
try:
results = self.execute_read_query(cypher_queries[idx])
if results:
if idx == len(cypher_queries) - 1:
results = results[0][:10]
break
except Exception:
pass
return results
让我们尝试一下
user_input = input("Enter your question : ")
query_engine = GraphQueryEngine()
cypher_queries = query_engine.get_response(user_input)
cypher_queries = query_engine.populate_embedding_in_query(user_input, cypher_queries)
fetched_data = query_engine.fetch_data(cypher_queries)
response = query_engine.get_final_response(user_input, fetched_data)
输出
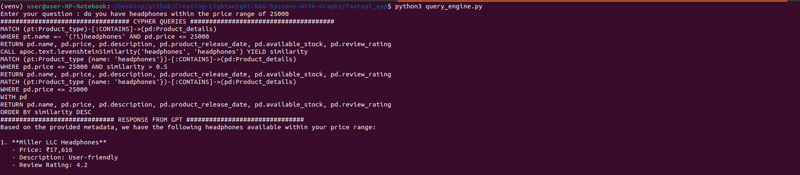

在下一篇博客中,我们将构建一个简单的 FastAPI 应用程序,将此设置公开为 API。
希望这有帮助...!!!
LinkedIn - https://www.linkedin.com/in/praveenr2998/
Github - https://github.com/praveenr2998/Creating-Lightweight-RAG-Systems-With-Graphs/blob/main/fastapi_app/query_engine.py
以上是构建一个简单的图查询引擎的详细内容。更多信息请关注PHP中文网其他相关文章!
声明:
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系admin@php.cn