
多模态模型评测框架lmms-eval发布!全面覆盖,低成本,零污染

- 王林原创
- 2024-08-21 16:38:07557浏览

AIxiv专栏是本站发布学术、技术内容的栏目。过去数年,本站AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢迎投稿或者联系报道。投稿邮箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com
随着大模型研究的深入,如何将其推广到更多的模态上已经成为了学术界和产业界的热点。最近发布的闭源大模型如 GPT-4o、Claude 3.5 等都已经具备了超强的图像理解能力,LLaVA-NeXT、MiniCPM、InternVL 等开源领域模型也展现出了越来越接近闭源的性能。
在这个「亩产八万斤」,「10 天一个 SoTA」的时代,简单易用、标准透明、可复现的多模态评估框架变得越来越重要,而这并非易事。
为解决以上问题,来自南洋理工大学 LMMs-Lab 的研究人员联合开源了 LMMs-Eval,这是一个专为多模态大型模型设计的评估框架,为多模态模型(LMMs)的评测提供了一站式、高效的解决方案。

代码仓库: https://github.com/EvolvingLMMs-Lab/lmms-eval
官方主页: https://lmms-lab.github.io/
论文地址: https://arxiv.org/abs/2407.12772
榜单地址:https://huggingface.co/spaces/lmms-lab/LiveBench
自 2024 年 3 月发布以来, LMMs-Eval 框架已经收到了来自开源社区、公司和高校等多方的协作贡献。现已在 Github 上获得 1.1K Stars,超过 30+ contributors,总计包含 80 多个数据集和 10 多个模型,并且还在持续增加中。

标准化测评框架
为了提供一个标准化的测评平台,LMMs-Eval 包含了以下特性:
统一接口: LMMs-Eval 在文本测评框架 lm-evaluation-harness 的基础上进行了改进和扩展,通过定义模型、数据集和评估指标的统一接口,方便了使用者自行添加新的多模态模型和数据集。
一键式启动:LMMs-Eval 在 HuggingFace 上托管了 80 多个(且数量不断增加)数据集,这些数据集精心从原始来源转换而来,包括所有变体、版本和分割。用户无需进行任何准备,只需一条命令,多个数据集和模型将被自动下载并测试,等待几分钟时间即可获得结果。
透明可复现:LMMs-Eval 内置了统一的 logging 工具,模型回答的每一题以及正确与否都会被记录下来, 保证了可复现性和透明性。同时也方便比较不同模型的优势与缺陷。
LMMs-Eval 的愿景是未来的多模态模型不再需要自行编写数据处理、推理以及提交代码。在当今多模态测试集高度集中的环境下,这种做法既不现实,测得的分数也难以与其他模型直接对比。通过接入 LMMs-Eval,模型训练者可以将更多精力集中在模型本身的改进和优化上,而不是在评测和对齐结果上耗费时间。
评测的「不可能三角」
LMMs-Eval 的最终目标是找到一种 1. 覆盖广 2. 成本低 3. 零数据泄露 的方法来评估 LMMs。然而,即使有了 LMMs-Eval,作者团队发现想同时做到这三点困难重重,甚至是不可能的。
如下图所示,当他们将评估数据集扩展到 50 多个时,执行这些数据集的全面评估变得非常耗时。此外,这些基准在训练期间也容易受到污染的影响。为此, LMMs-Eval 提出了 LMMs-Eval-Lite 来兼顾广覆盖和低成本。他们也设计了 LiveBench 来做到低成本和零数据泄露。

LMMs-Eval-Lite: 广覆盖轻量级评估

대형 모델을 평가할 때 수많은 매개변수와 테스트 작업으로 인해 평가 작업에 소요되는 시간과 비용이 급격히 증가하는 경우가 많습니다. 따라서 사람들은 평가를 위해 더 작은 데이터 세트를 사용하거나 특정 데이터 세트를 사용하는 경우가 많습니다. 그러나 제한된 평가로 인해 모델 기능에 대한 이해가 부족한 경우가 많습니다. 평가의 다양성과 평가 비용을 모두 고려하기 위해 LMMs-Eval은 LMMs-Eval-Lite

LMMs-Eval-을 출시했습니다. Lite. 우리는 모델 개발 중에 유용하고 빠른 신호를 제공하여 오늘날 테스트의 부풀어오르는 문제를 피하기 위해 단순화된 벤치마크 세트를 구축하고 있습니다. 모델 간의 절대 점수와 상대 순위가 전체 세트와 유사하게 유지되는 기존 테스트 세트의 하위 세트를 찾을 수 있다면 이러한 데이터 세트를 정리하는 것이 안전하다고 간주할 수 있습니다.
데이터 세트에서 데이터 핵심 포인트를 찾기 위해 LMMs-Eval은 먼저 CLIP 및 BGE 모델을 사용하여 다중 모달 평가 데이터 세트를 벡터 임베딩 형태로 변환하고 k-탐욕 클러스터링 방법을 사용하여 데이터의 주요 포인트. 테스트에서 이러한 소규모 데이터 세트는 여전히 전체 세트와 유사한 평가 기능을 보여주었습니다.

이후 LMMs-Eval은 동일한 방법을 사용하여 더 많은 데이터 세트를 포함하는 Lite 버전을 생성했습니다. 이러한 데이터 세트는 사람들이 개발 중에 평가 비용을 절약하여 모델 성능을 신속하게 판단할 수 있도록 설계되었습니다

LiveBench: LMM의 동적 테스트
기존 벤치마크는 고정된 질문과 답변을 사용한 정적 평가에 중점을 둡니다. 다중 모드 연구가 진행됨에 따라 오픈 소스 모델은 점수 비교에서는 GPT-4V와 같은 상용 모델보다 우수한 경우가 많지만 실제 사용자 경험에서는 뒤떨어집니다. 동적 사용자 지향 Chatbots Arenas 및 WildVision은 모델 평가에 점점 더 인기를 얻고 있지만 수천 개의 사용자 선호도를 수집해야 하며 평가하는 데 비용이 매우 많이 듭니다.
LiveBench의 핵심 아이디어는 오염 제로를 달성하고 비용을 낮게 유지하기 위해 지속적으로 업데이트되는 데이터 세트에서 모델의 성능을 평가하는 것입니다. 저작팀은 웹에서 평가 데이터를 수집하고 뉴스, 커뮤니티 포럼 등 웹사이트에서 최신 글로벌 정보를 자동으로 수집하는 파이프라인을 구축했습니다. 정보의 적시성과 신뢰성을 보장하기 위해 저자 팀은 CNN, BBC, 일본의 아사히 신문, 중국의 신화 통신사 및 Reddit과 같은 포럼을 포함한 60개 이상의 뉴스 매체에서 출처를 선택했습니다. 구체적인 단계는 다음과 같습니다.
홈페이지의 스크린샷을 캡처하고 광고 및 뉴스가 아닌 요소를 제거합니다.
GPT4-V, Claude-3-Opus 및 Gemini-1.5-Pro와 같이 현재 사용 가능한 가장 강력한 다중 모드 모델을 사용하여 질문 및 답변 세트를 디자인합니다.
정확성과 관련성을 보장하기 위해 다른 모델이 검토하고 수정한 질문입니다.
최종 질문과 답변 세트는 수동으로 검토되며, 매달 약 500개의 질문이 수집되며, 100~300개가 최종 라이브벤치 질문 세트로 유지됩니다.
LLaVA-Wilder 및 Vibe-Eval의 채점 기준을 사용하여 제공된 표준 답변을 기준으로 점수를 매기는 채점 모델이며 점수 범위는 [1, 10]입니다. 기본 채점 모델은 GPT-4o이며 Claude-3-Opus 및 Gemini 1.5 Pro도 대안으로 포함되어 있습니다. 최종 보고된 결과는 0~100 범위의 정확도 측정항목으로 변환된 점수를 기반으로 합니다.
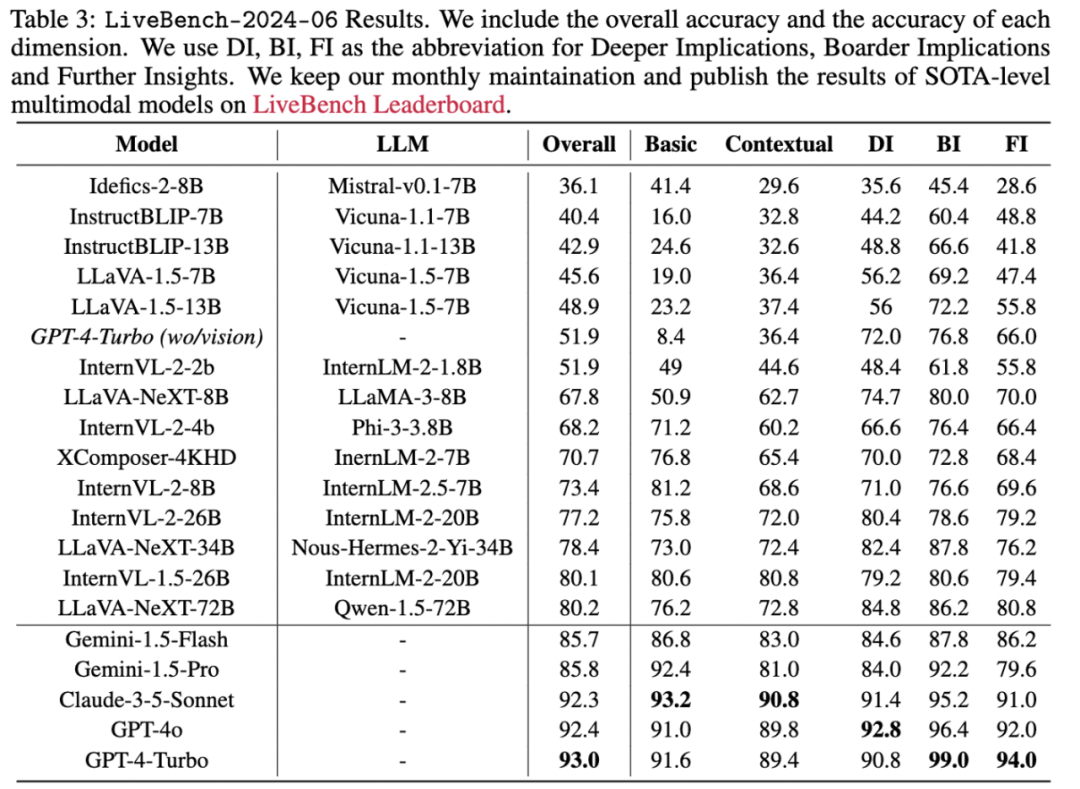
향후에는 동적으로 업데이트되는 목록에서 매월 동적으로 업데이트되는 다중 모달 모델의 최신 평가 데이터와 목록의 최신 평가 결과를 볼 수도 있습니다.
以上是多模态模型评测框架lmms-eval发布!全面覆盖,低成本,零污染的详细内容。更多信息请关注PHP中文网其他相关文章!