
机器人版的「斯坦福小镇」来了,专为具身智能研究打造

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB原创
- 2024-07-22 14:24:11652浏览
Die erste simulierte interaktive 3D-Gesellschaft, die speziell für verschiedene Roboter entwickelt wurde.
Erinnern Sie sich an Stanfords KI-Stadt? Dies ist eine virtuelle Umgebung, die von KI-Forschern in Stanford erstellt wurde. In dieser kleinen Stadt leben, arbeiten, knüpfen und verlieben sich ganz normal 25 KI-Agenten. Jeder Agent hat seine eigene Persönlichkeit und Hintergrundgeschichte. Das Verhalten und das Gedächtnis des Agenten werden durch große Sprachmodelle gesteuert, die die Erfahrungen des Agenten speichern und abrufen und auf der Grundlage dieser Erinnerungen Aktionen planen. (Siehe „Stanfords „virtuelle Stadt“ ist Open Source: 25 KI-Agenten erhellen „Westworld““)
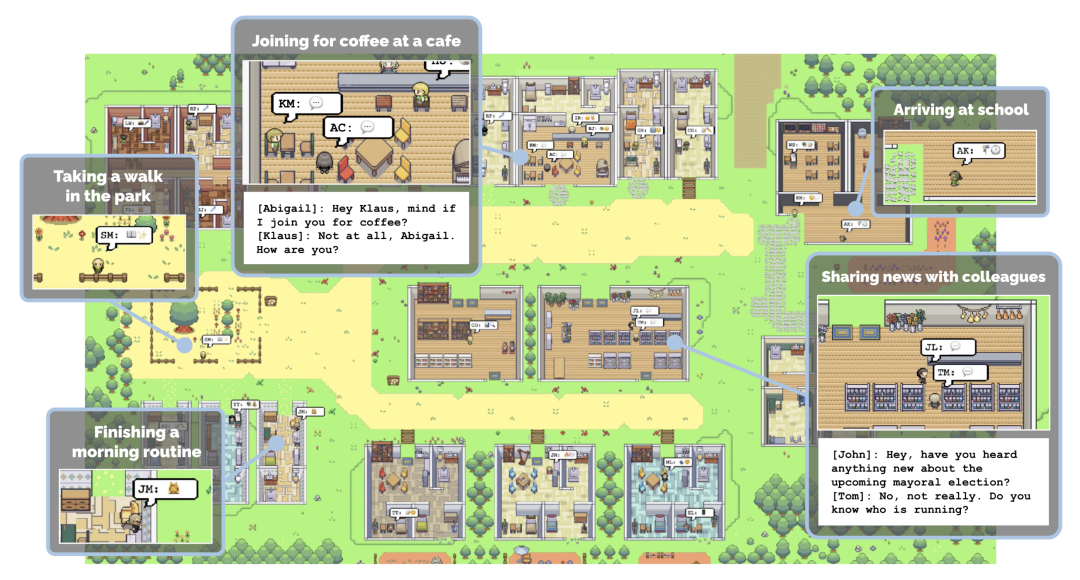
In ähnlicher Weise hat kürzlich eine Gruppe von Forschern des Shanghai Artificial Intelligence Laboratory OpenRobotLab und anderer Institutionen eine Gruppe von Forschern hat auch eine virtuelle Stadt geschaffen. Unter ihnen leben jedoch Roboter und NPCs.  Mit 100.000 interaktiven Szenen und 89 verschiedenen Szenenkategorien ist diese Stadt die erste simulierte interaktive 3D-Gesellschaft, die speziell für verschiedene Roboter entwickelt wurde.
Mit 100.000 interaktiven Szenen und 89 verschiedenen Szenenkategorien ist diese Stadt die erste simulierte interaktive 3D-Gesellschaft, die speziell für verschiedene Roboter entwickelt wurde.

Die Autoren gaben an, dass sie diese Umgebung entworfen haben, um das Problem der Datenknappheit im Bereich der verkörperten Intelligenz zu lösen. Wie wir alle wissen, war die Erforschung des Skalierungsgesetzes im Bereich der verkörperten Intelligenz aufgrund der hohen Kosten für die Erhebung realer Daten schwierig. Daher wird das Simulation-to-Real-Paradigma (Sim2Real) zu einem entscheidenden Schritt bei der Erweiterung des verkörperten Modelllernens.
Die virtuelle Umgebung, die sie für Roboter entworfen haben, heißt GRUtopia. Das Projekt umfasst hauptsächlich:
1 Szenendatensatz. Enthält 100.000 interaktive, fein kommentierte Szenen, die frei zu Umgebungen im Stadtmaßstab kombiniert werden können. Im Gegensatz zu früheren Arbeiten, die sich hauptsächlich auf das Zuhause konzentrierten, deckt GRScenes 89 verschiedene Szenenkategorien ab und schließt damit die Lücke in serviceorientierten Umgebungen (in denen Roboter typischerweise zunächst eingesetzt werden).
2. GREinwohner. Hierbei handelt es sich um ein durch ein großes Sprachmodell (LLM) gesteuertes Nicht-Spieler-Charaktersystem (NPC), das für soziale Interaktion, Aufgabengenerierung und Aufgabenzuweisung verantwortlich ist und dadurch soziale Szenarien für verkörperte KI-Anwendungen simuliert.
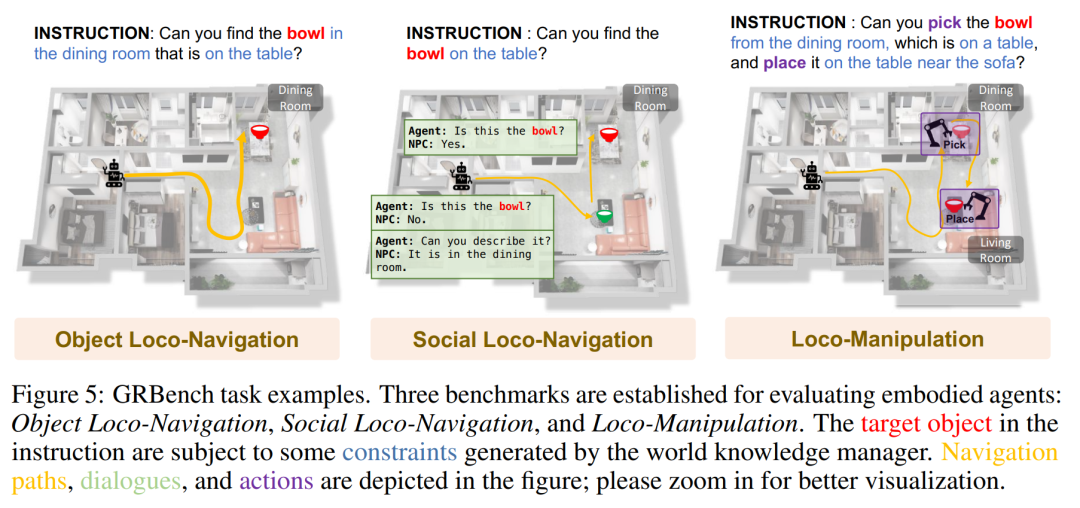
3. Benchmark GRBench. Es werden verschiedene Roboter unterstützt, der Schwerpunkt liegt jedoch auf Beinrobotern als Hauptagenten, und es werden mittelschwere Aufgaben vorgeschlagen, die Objektlokalisierungsnavigation, soziale Lokalisierungsnavigation und Lokalisierungsmanipulation umfassen.
Die Autoren hoffen, dass diese Arbeit den Mangel an qualitativ hochwertigen Daten in diesem Bereich lindern und eine umfassendere Bewertung der verkörperten KI-Forschung ermöglichen wird.

Papiertitel: GRUtopia: Dream General Robots in a City at Scale
Papieradresse: https://arxiv.org/pdf/2407.10943
Projektadresse: https://github .com/OpenRobotLab/GRUtopia
GRScenes: Vollständig interaktive Umgebungen im großen Maßstab
Um eine Plattform für die Schulung und Bewertung verkörperter Agenten aufzubauen, ist eine vollständig interaktive Umgebung mit verschiedenen Szenen- und Objektressourcen ein Muss. Unverzichtbar. Daher haben die Autoren einen großen synthetischen 3D-Szenendatensatz gesammelt, der verschiedene Objektressourcen als Grundlage der GRUtopia-Plattform enthält.
Vielfältige, realistische Szenen
Aufgrund der begrenzten Anzahl und Kategorie von Open-Source-3D-Szenendaten sammelte der Autor zunächst etwa 100.000 hochwertige synthetische Szenen von Designer-Websites, um verschiedene Szenenprototypen zu erhalten. Anschließend bereinigten sie diese Szenenprototypen, kommentierten sie mit Semantik auf Regions- und Objektebene und kombinierten sie schließlich zu Städten, die als grundlegende Spielwiese des Roboters dienten.
Wie in Abbildung 2-(a) gezeigt, enthält der vom Autor erstellte Datensatz zusätzlich zu gewöhnlichen Heimszenen auch 30 % anderer Szenenkategorien, wie z. B. Restaurants, Büros, öffentliche Orte, Hotels, Unterhaltung, usw. Die Autoren überprüften zunächst 100 fein kommentierte Szenen aus einem umfangreichen Datensatz für das Open-Source-Benchmarking. Diese 100 Szenen umfassen 70 Heimszenen und 30 Geschäftsszenen, wobei die Heimszene aus umfassenden Gemeinschaftsbereichen und anderen unterschiedlichen Bereichen besteht und die Geschäftsszenen gängige Typen wie Krankenhäuser, Supermärkte, Restaurants, Schulen, Bibliotheken und Büros abdecken.
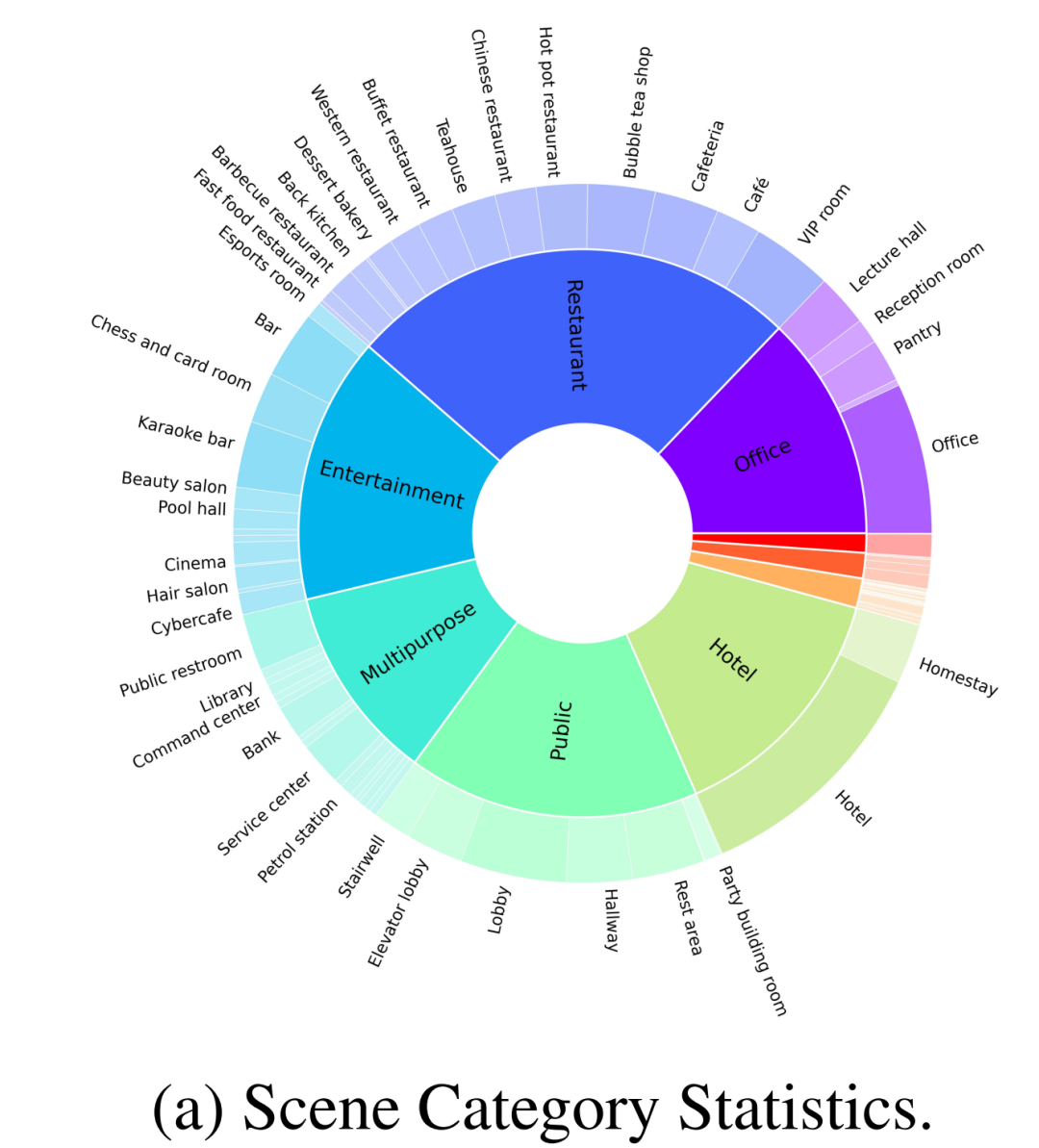
Selain itu, penulis juga bekerjasama dengan beberapa pereka profesional untuk memperuntukkan objek mengikut tabiat hidup manusia untuk menjadikan adegan ini lebih realistik, seperti yang ditunjukkan dalam Rajah 1, yang biasanya diabaikan dalam karya terdahulu.
Objek interaktif dengan anotasi peringkat separa
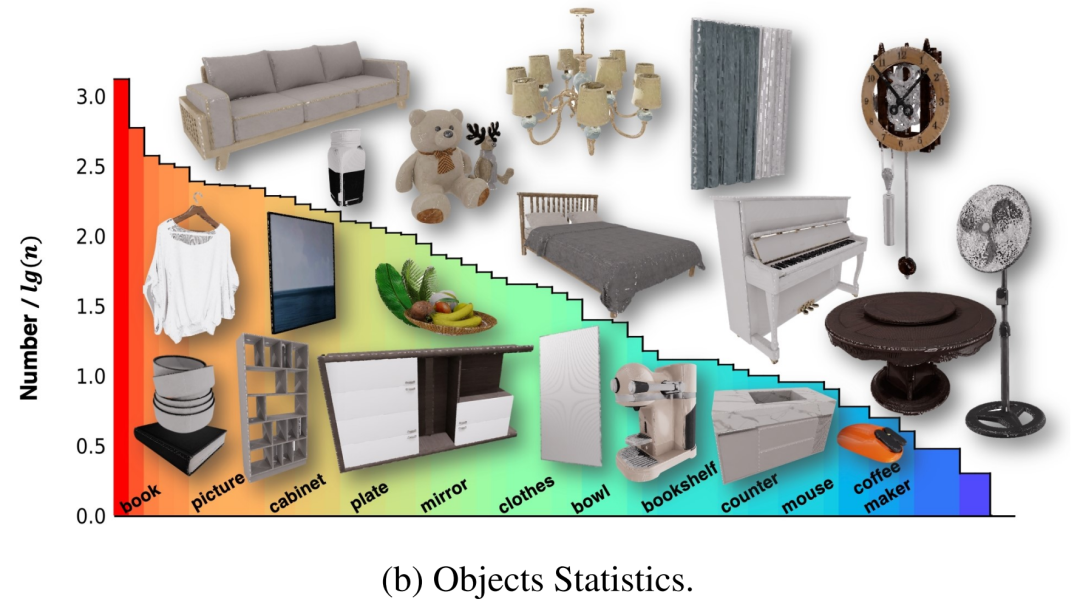
Adegan ini pada asalnya mengandungi berbilang objek 3D, tetapi sesetengah daripadanya tidak dimodelkan secara dalaman, jadi robot tidak dapat dilatih untuk berinteraksi dengan objek ini. Untuk menyelesaikan masalah ini, pengarang bekerja dengan pasukan profesional untuk mengubah suai aset ini dan mencipta objek lengkap yang membolehkan mereka berinteraksi dengan cara yang boleh dipercayai secara fizikal. Selain itu, untuk menyediakan maklumat yang lebih komprehensif yang membolehkan ejen berinteraksi dengan aset ini, penulis melampirkan label bahagian berbutir halus dalam bentuk X pada bahagian interaktif semua objek dalam NVIDIA Omniverse. Akhir sekali, 100 adegan mengandungi 2956 objek interaktif dan 22001 objek bukan interaktif dalam 96 kategori, dan taburannya ditunjukkan dalam Rajah 2-(b).
Anotasi multimodal hierarki
Akhir sekali, untuk mencapai interaksi pelbagai mod ejen yang terkandung dengan persekitaran dan NPC, adegan dan objek ini juga perlu diberi anotasi linguistik. Tidak seperti set data pemandangan 3D berbilang mod sebelumnya yang hanya memfokuskan pada tahap objek atau hubungan antara objek, pengarang juga mempertimbangkan butiran yang berbeza bagi elemen pemandangan, seperti hubungan antara objek dan wilayah. Memandangkan kekurangan label rantau, pengarang mula-mula mereka bentuk antara muka pengguna untuk menganotasi kawasan dengan poligon pada pandangan mata burung tempat kejadian, yang kemudiannya boleh melibatkan hubungan objek-rantau dalam anotasi linguistik. Untuk setiap objek, mereka menggesa VLM berkuasa (seperti GPT-4v) dengan imej berbilang paparan yang diberikan untuk memulakan anotasi, yang kemudiannya diperiksa oleh manusia. Anotasi linguistik yang terhasil menyediakan asas untuk tugasan yang terkandung dalam penjanaan tanda aras berikutnya. . Sistem NPC ini dinamakan GRResidents. Salah satu cabaran utama dalam membina watak maya yang realistik dalam adegan 3D ialah menyepadukan keupayaan persepsi 3D. Walau bagaimanapun, watak maya boleh mengakses anotasi pemandangan dan keadaan dalaman dunia simulasi dengan mudah, yang membolehkan keupayaan persepsi yang berkuasa. Untuk tujuan ini, pengarang mereka bentuk Pengurus Pengetahuan Dunia (WKM) untuk mengurus pengetahuan dinamik keadaan dunia masa nyata dan menyediakan akses melalui satu siri antara muka data. Dengan WKM, NPC boleh mendapatkan semula pengetahuan yang diperlukan dan melakukan pembumian objek yang terperinci melalui panggilan fungsi berparameter, yang membentuk teras keupayaan sentimen mereka.
World Knowledge Manager (WKM)
Tanggungjawab utama WKM adalah untuk menguruskan pengetahuan persekitaran maya secara berterusan dan menyediakan pengetahuan adegan lanjutan kepada NPC. Secara khusus, WKM memperoleh anotasi hierarki dan pengetahuan pemandangan daripada set data dan bahagian belakang simulator masing-masing, dan membina graf pemandangan sebagai perwakilan pemandangan, di mana setiap nod mewakili contoh objek dan tepi mewakili hubungan ruang antara objek. Pengarang mengguna pakai hubungan spatial yang ditakrifkan dalam Sr3D sebagai ruang hubungan. WKM mengekalkan graf pemandangan ini pada setiap langkah simulasi. Selain itu, WKM juga menyediakan tiga antara muka data teras untuk mengekstrak pengetahuan daripada graf pemandangan:
1, find_diff (sasaran, objek): membandingkan perbezaan antara objek sasaran dan satu set objek lain 2, get_info (objek, jenis): Dapatkan pengetahuan objek mengikut jenis atribut yang diperlukan
3.
LLM PlannerModul membuat keputusan NPC ialah perancang berasaskan LLM, yang terdiri daripada tiga bahagian (Rajah 3): modul storan yang digunakan untuk menyimpan sejarah sembang antara NPC dan ejen lain Seorang pengaturcara LLM menggunakan antara muka WKM untuk menanyakan pengetahuan pemandangan; dan pembesar suara LLM digunakan untuk mencerna sejarah sembang dan pengetahuan yang ditanya untuk menjana balasan. Apabila NPC menerima mesej, ia mula-mula menyimpan mesej dalam ingatan dan kemudian memajukan sejarah yang dikemas kini kepada pengaturcara LLM. Kemudian, pengaturcara akan berulang kali memanggil antara muka data untuk menanyakan pengetahuan pemandangan yang diperlukan. Akhirnya, pengetahuan dan sejarah dihantar kepada penceramah LLM, yang menjana respons. . maklumat. LLM belakang NPC dalam eksperimen ini termasuk GPT-4o, InternLM2-Chat-20B dan Llama-3-70BInstruct.
図 4 に示すように、参考実験では著者らは人間参加型評価を使用しました。 NPC はオブジェクトをランダムに選択してそれを説明し、ヒューマン・アノテーターはその説明に基づいてオブジェクトを選択します。ヒューマン・アノテーターが説明に対応する正しいオブジェクトを見つけることができれば、参照は成功します。グラウンディング実験では、GPT-4o はヒューマン アノテーターの役割を果たし、NPC によって配置されたオブジェクトの説明を提供しました。 NPC が対応するオブジェクトを見つけることができれば、接地は成功します。
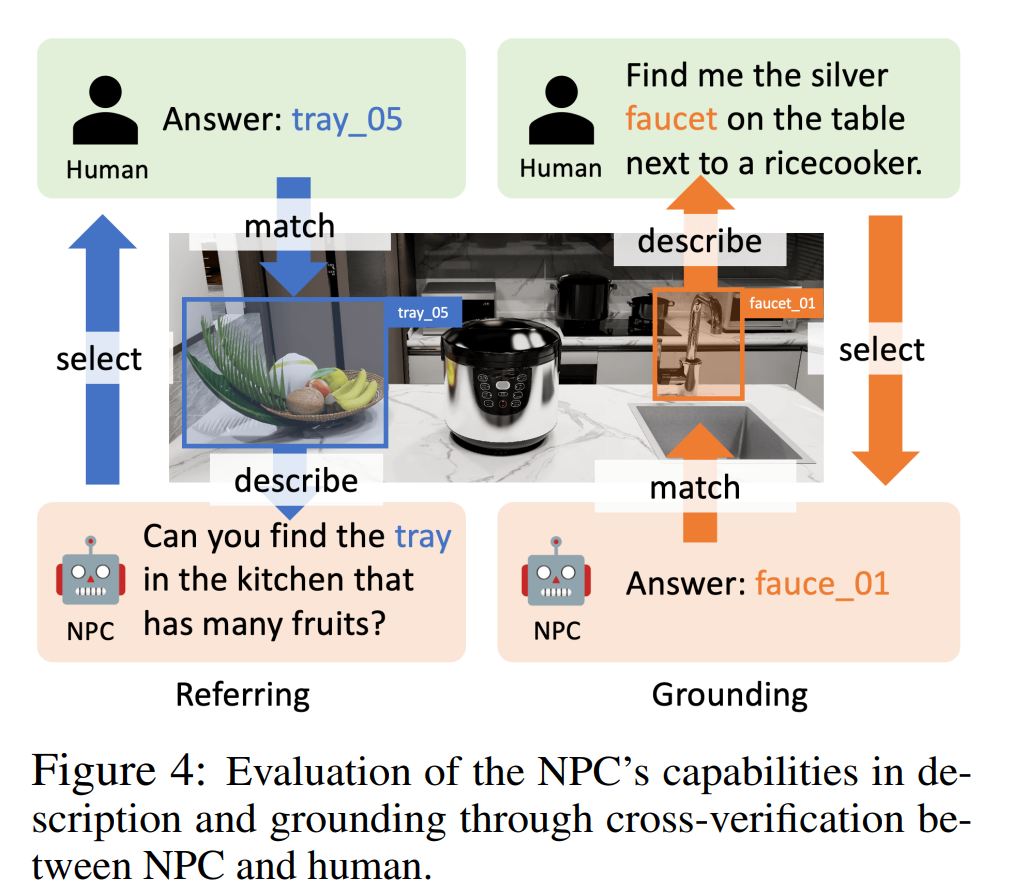
表 2 の成功率 (参照およびグラウンディング) は、さまざまな LLM の精度率がそれぞれ 95.9% ~ 100% および 83.3% ~ 93.2% であることを示しており、NPC フレームワークがさまざまな LLM を参照できることが検証されています。そして接地精度。
オブジェクト中心の QA 実験で、著者らは、ナビゲーション タスクの質問に答えることでオブジェクト レベルの情報をエージェントに提供する NPC の能力を評価しました。彼らは、現実世界のシナリオをシミュレートするオブジェクト中心のナビゲーション プロットを生成するパイプラインを設計しました。これらのシナリオでは、エージェントは NPC に質問して情報を取得し、その回答に基づいてアクションを実行します。エージェントの質問が与えられると、著者はその回答と実際の回答の間の意味論的な類似性に基づいて NPC を評価します。表 2 (QA) に示されている総合スコアは、NPC が正確で有用なナビゲーション支援を提供できることを示しています。
GRBench: 身体化エージェントを評価するためのベンチマーク
GRBench は、ロボット エージェントの機能を評価するための包括的な評価ツールです。日常のタスクを処理するロボット エージェントの能力を評価するために、GRBench にはオブジェクト ローカリゼーション ナビゲーション、ソーシャル ローカリゼーション ナビゲーション、およびローカリゼーション オペレーションの 3 つのベンチマークが含まれています。これらのベンチマークの難易度は徐々に上がり、ロボットに必要なスキルも上がります。
脚式ロボットの優れた地形横断能力により、著者はそれをメインエージェントとして優先しました。ただし、大規模なシナリオでは、現在のアルゴリズムでは高レベルの認識、計画、および低レベルの制御を同時に実行し、満足のいく結果を達成することが困難です。
GRBench の最新の進歩により、シミュレーションにおける単一スキルの高精度ポリシーのトレーニングの実現可能性が証明されました。これに触発されて、GRBench の初期バージョンは高レベルのタスクに焦点を当て、学習ベースの制御戦略を API として提供します。歩いて選んで配置します。その結果、ベンチマークはより現実的な物理環境を提供し、シミュレーションと現実世界の間のギャップを埋めます。
下の図は、GRBench タスクの例をいくつか示しています。
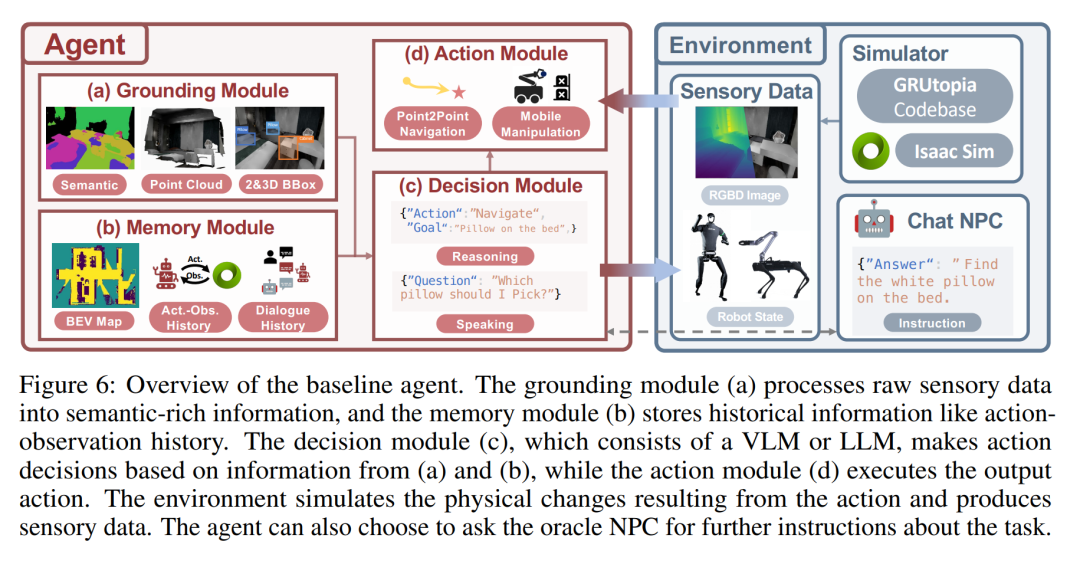
下の図は、ベースライン エージェントの概要です。グラウンディング モジュール (a) は生の感覚データを処理して意味論的に豊富な情報を生成し、メモリ モジュール (b) は行動観察履歴などの履歴情報を保存します。決定モジュール (c) は VLM または LLM で構成され、(a) と (b) からの情報に基づいてアクションの決定を行い、アクション モジュール (d) は出力アクションを実行します。環境は、行動によってもたらされる物理的な変化をシミュレートし、感覚データを生成します。エージェントは、タスクに関するさらなる指示をアドバイザー NPC に求めることを選択できます。
定量的な評価結果
著者は、3 つのベンチマーク テストで、異なる大規模モデル バックエンドの下で大規模モデル駆動型エージェント フレームワークの比較分析を実行しました。表 4 に示すように、ランダム戦略のパフォーマンスが 0 に近いことがわかり、タスクが単純ではないことがわかりました。比較的優れた大規模モデルをバックエンドとして使用すると、3 つのベンチマークすべてで全体的なパフォーマンスが大幅に向上することが観察されました。対話において Qwen が GPT-4o よりも優れたパフォーマンスを発揮したことを彼らが観察したことは言及する価値があります (表 5 を参照)。
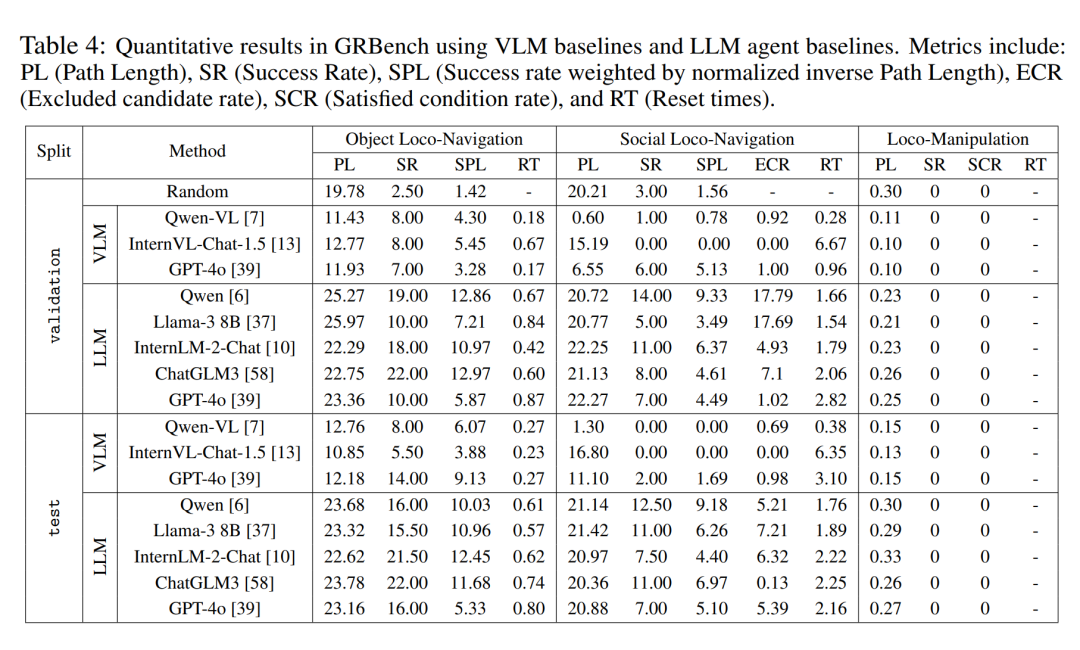

さらに、意思決定にマルチモーダル大規模モデルを直接使用する場合と比較して、この記事で提案されているエージェント フレームワークは明らかな優位性を示しています。これは、現在の最先端のマルチモーダル大規模モデルでさえ、現実世界の具体化されたタスクに対する強力な一般化機能に欠けていることを示しています。ただし、この記事の方法にも改善の余地がかなりあります。このことは、ナビゲーションのような長年研究されてきた課題であっても、より現実世界に近い課題設定を導入した場合には、未だ完全な解決には程遠いことを示している。
定性評価結果
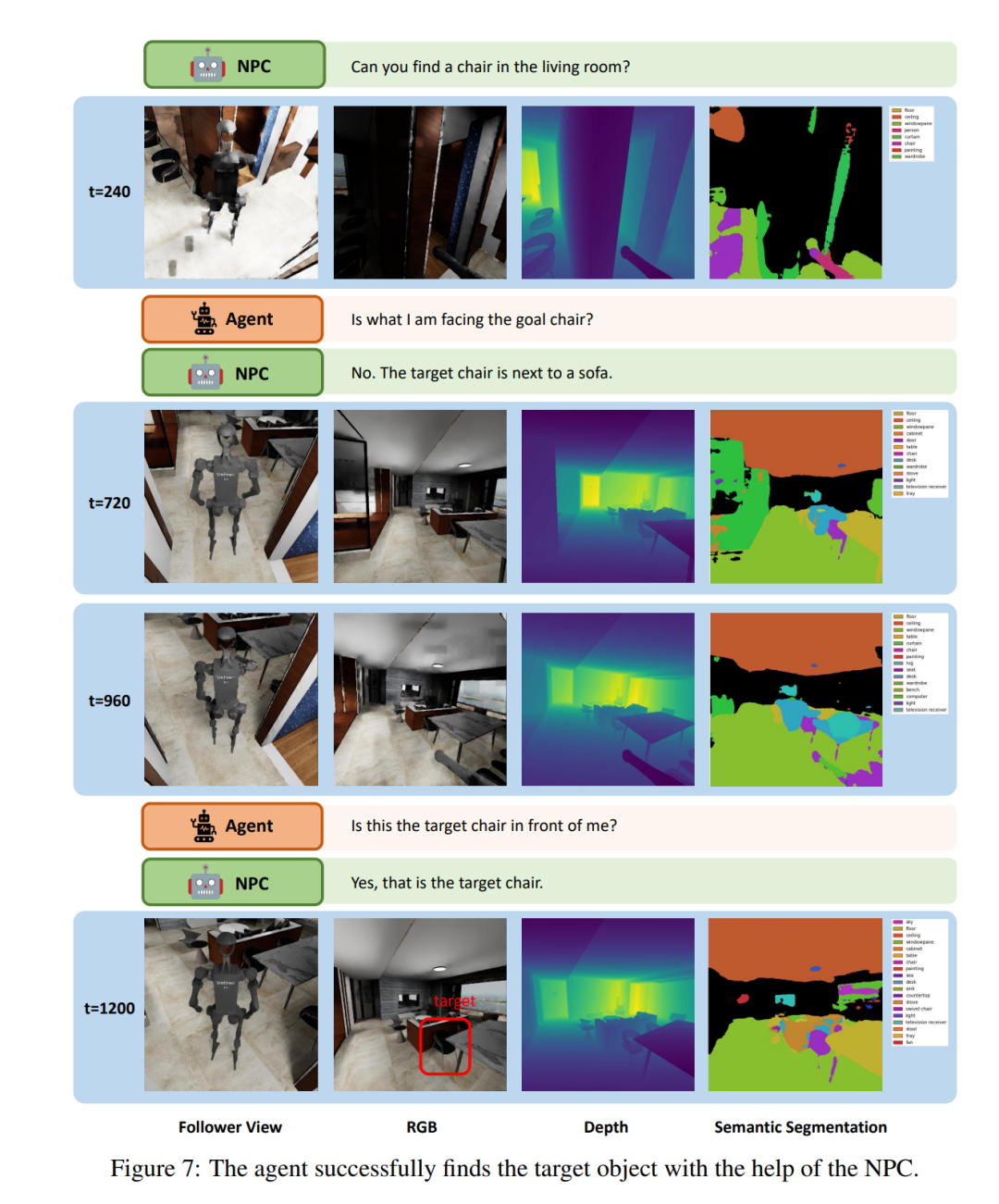
图 7 展示了 LLM 智能体在「社会定位导航」(Social Loco-Navigation)任务中执行的一个小片段,以说明智能体如何与 NPC 互动。该智能体最多可与 NPC 对话三次,以查询更多任务信息。在 t = 240 时,智能体导航到一把椅子前,询问 NPC 这把椅子是否是目标椅子。然后,NPC 提供有关目标的周边信息,以减少模糊性。在 NPC 的协助下,智能体通过类似人类行为的交互过程成功识别了目标椅子。这表明,本文中的 NPC 能够为研究人与机器人的互动和协作提供自然的社会互动。
以上是机器人版的「斯坦福小镇」来了,专为具身智能研究打造的详细内容。更多信息请关注PHP中文网其他相关文章!