
178页!GPT-4V(ision)医疗领域首个全面案例测评:离临床应用与实际决策尚有距离

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB原创
- 2024-07-19 18:25:03442浏览
上海交大&上海AI Lab发布178页GPT-4V医疗案例测评,首次全面揭秘GPT-4V医疗领域视觉性能ArXiv链接:https://arxiv.org/abs/2310.09909其他论文下载地址:百度云: https://pan.baidu.com/s/11xV8MkUfmF3emJQH9awtcw?pwd=krk2Google Drive:https://drive.google.com/file/d/1HPvPDwhgpOwxi2sYH3_xrcaoXjBGWhK9/view?usp=sharing研究简介在大型基础模型的推动下,人工智能的发展近来取得了巨大进步,尤其是OpenAI的GPT-4,其在问答、知识方面展现出的强大能力点亮了AI领域的尤里卡时刻,引起了公众的普遍关注。GPT-4V(ision)是OpenAI最新的多模态基础模型。相较于GPT-4,它增加了图像与语音的输入能力。该研究则旨在通过案例分析评估 GPT-4V(ision)在多模态医疗诊断领域的性能,一共展现并分析共计了128(92个放射学评估案例,20个病理学评估案例以及16个定位案例)个案例共计277张图像的GPT-4V问答实例(注:本文不会涉及案例展示,请参阅原论文查看具体的案例展示与分析)。总结而言,原作者希望系统的评估GPT-4V如下的多种能力:GPT-4V 能否识别医学图像的模态和成像位置?识别各种模态(如 X 射线、CT、核磁共振成像、超声波和病理)并识别这些图像中的成像位置,是进行更复杂诊断的基础。GPT-4V 能否定位医学影像中的不同解剖结构?精确定位图像中的特定解剖结构对识别异常、确保正确处理潜在问题至关重要。GPT-4V 能否发现和定位医学图像中的异常?检测异常,如 肿瘤、骨折或感染是医学图像分析的主要目标。在临床环境中,可靠的人工智能模型不仅需要发现这些异常,还需要准确定位,以便进行有针对性的干预或治疗。GPT-4V 能否结合多张图像进行诊断?医学诊断往往需要综合不同成像模态或视图的信息,进行整体观察。因此探究 GPT-4V 组合和分析多图信息的能力至关重要。GPT-4V 能否撰写医疗报告,描述异常情况和相关的正常结果?对于放射科医生和病理学家来说,撰写报告是一项耗时的工作。如果 GPT-4V 在这一过程中提供帮助,生成准确且与临床相关的报告,无疑将提高整个工作流程的效率。GPT-4V 能否在解读医学影像时整合患者病史?患者的基本信息和既往病史会在很大程度上影响对当前医学影像的解读。在模型预测过程中如果能综合考虑到这些信息去分析图像将使分析更加个性化,也更加准确。GPT-4V 能否在多轮交互中保持一致性和记忆性?在某些医疗场景中,单轮分析可能是不够的。在长时间的对话或分析过程中,尤其是在复杂的医疗环境中,保持对数据认知的连续性至关重要。原论文的评估涵盖了 17 个医学系统,包括:中枢神经系统、头颈部、心脏、胸部和腹部、 头颈部、心脏、胸部、血液、肝胆、胃肠、泌尿、妇科、产科、乳腺、肛门、腹部、 妇科、产科、乳腺科、肌肉骨骼科、脊柱科、血管科、肿瘤科、创伤科、儿科图像来自日常临床使用的 8 种模态,包括: X 光、计算机断层扫描 (CT)、磁共振成像 (MRI)、正电子发射断层扫描 (PET)、数字减影血管造影 (DSA)、 乳房 X 射线照相术、超声波检查和病理学检查。

论文指出,尽管 GPT-4V 在区分医学影像模态和解剖结构方面表现出色,但在疾病诊断和生成综合报告方面仍面临巨大挑战。这些发现表明,大型多模态模型在计算机视觉和自然语言处理方面取得了显著进展,但仍不足以支持真实的医疗应用和临床决策。
测试案例挑选
原论文的放射学问答来自 [Radiopaedia](https://radiopaedia.org/),图像直接从网页下载,定位案例来自多个医学公开分割数据集,病理图像则来自 [PathologyOutlines](https://www.pathologyoutlines.com/)。在挑选案例时,作者全面考虑了以下方面:
- 公布时间:为避免所选测试案例出现在 GPT-4V 的训练集中,作者仅选用了 2023 年发布的最新案例。
- 标注可信度:根据 Radiopaedia 提供的案例完成度,作者尽量选用完成度大于 90% 的案例以保证标注或诊断的可信。
- 图像模态多样性:在选取案例时,作者尽可能展示 GPT-4V 对多种成像模态的响应情况。
在图像处理方面,作者也做了如下规范化以保证输入图像的质量:
- 多图选择:GPT-4V 最多支持 4 张图像输入,但某些案例可能有超过 4 张相关图像。作者会尽可能避免这种情况,若遇到,则根据 Radiopaedia 的案例注释挑选最相关的图像。
- 截面选择:大量的放射图像数据为 3D 形式,无法直接输入 GPT-4V。作者利用 Radiopaedia 推荐的轴截面代替完整的 3D 图像进行输入。
- 图像标准化:医疗图像的标准化包括窗宽窗位的选择。作者使用 Radiopaedia 案例上传时放射专家选择的窗宽窗位输入图像。对于分割数据集,原论文采用 [-300, 300] 的视窗并进行 0-1 的案例级归一化。
原论文的测试均使用 GPT-4V 的 [网页版](https://chat.openai.com/)。第一轮问答用户会输入图像,然后展开多轮的问答。为了避免上下文的互相影响,对于每次新的案例,都会新建一个问答窗口进行问答。
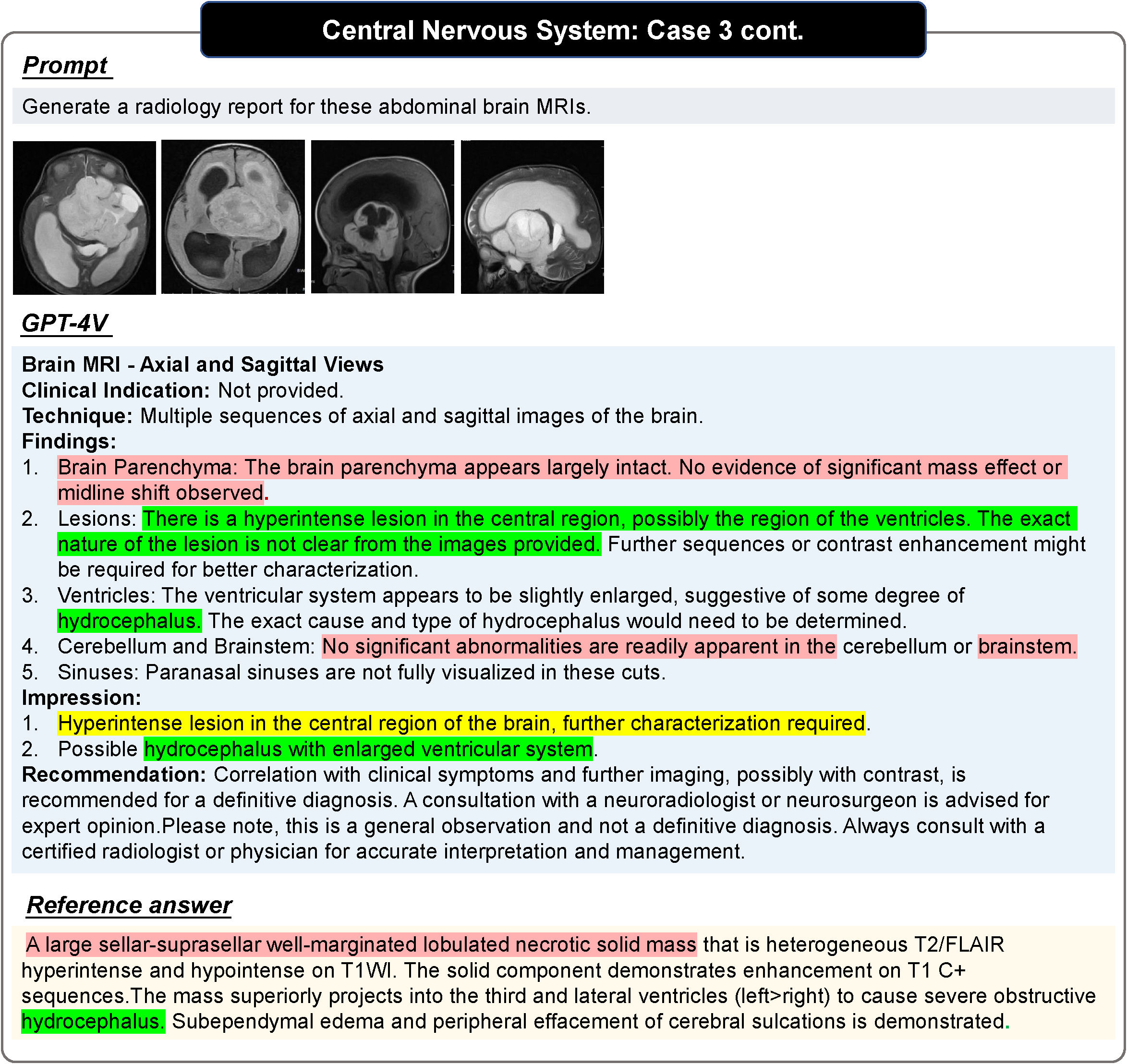
图中红色表示错误,黄色表示不确定,绿色表示正确。Reference 中的颜色表示对应判断的依据。未标记颜色的句子需要读者自行判断正确性。更多案例以及案例分析,请参考原论文。
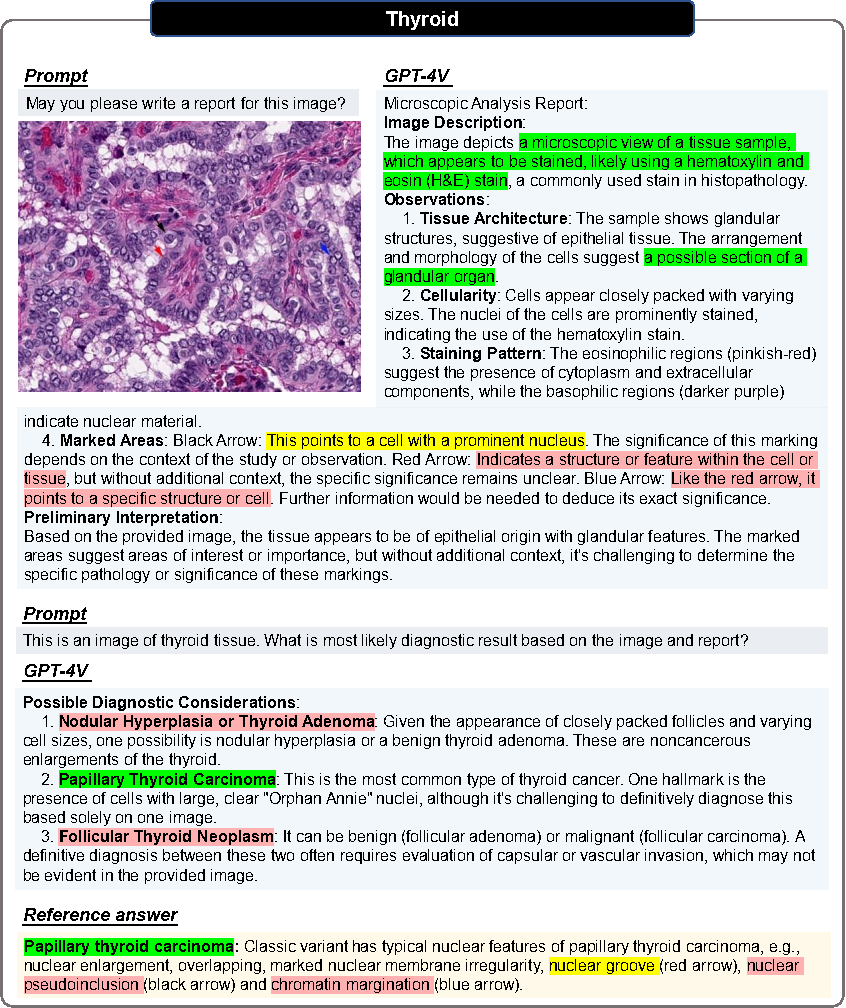
病理评估
所有图像均进行两轮对话。
第一轮
询问能否仅根据输入图像生成报告。
目的:评估 GPT-4V 能否在不提供任何相关医疗提示的情况下识别图像模态和组织来源。
第二轮
用户提供正确的组织来源,询问 GPT-4V 是否能根据病理图像及其组织来源信息做出诊断。
希望 GPT-4V 能修改报告并提供明确的诊断结果。
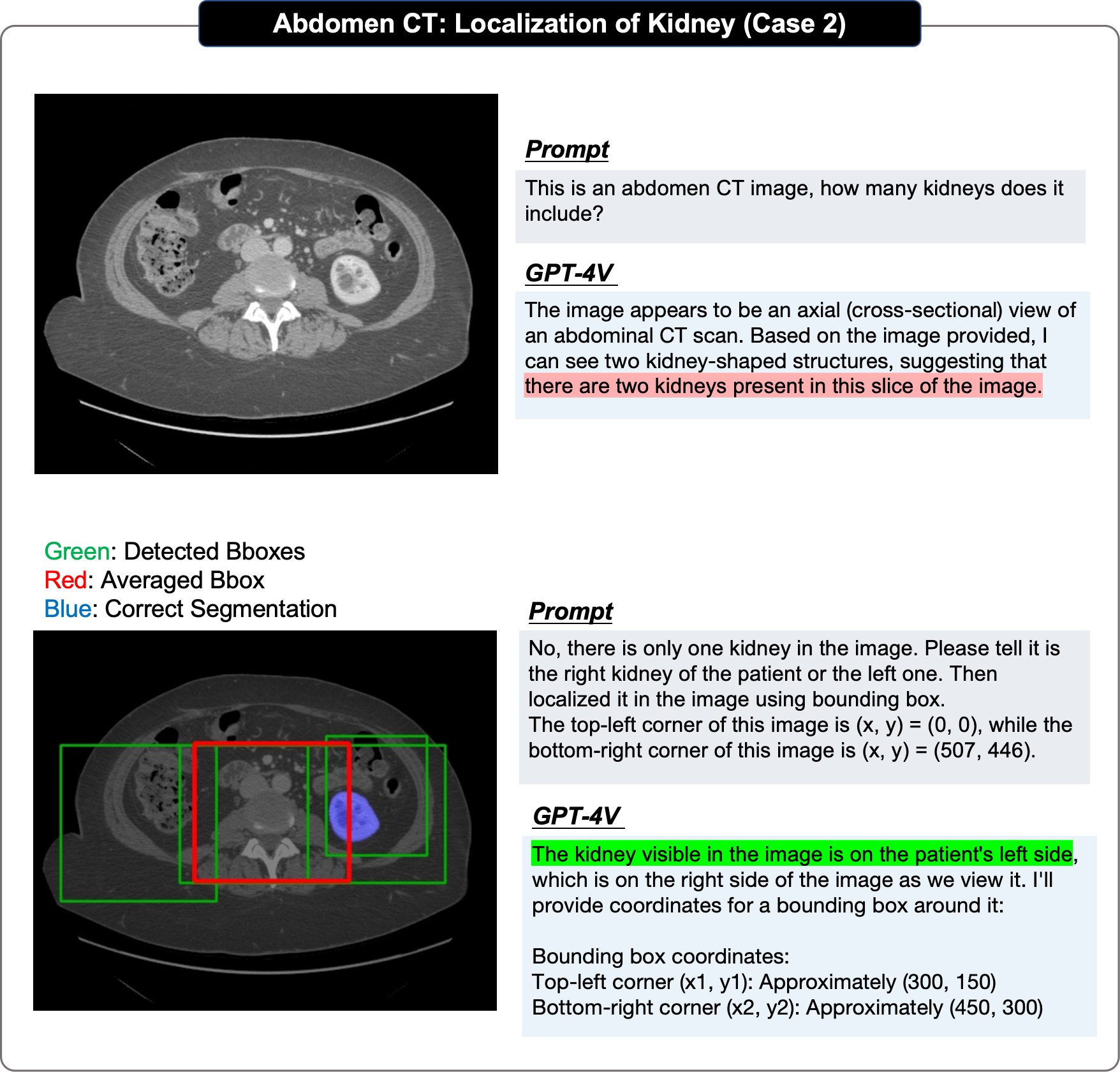
在定位评估中,原论文采取了循序渐进的方式:
- 首先测试 GPT-4V 是否能识别出所提供图像中目标的存在;
- 然后要求它根据图像左上角为(x,y)=(0,0)和右下角为(x,y)=(w,h)生成目标的边界框坐标,并对每个单一定位任务重复评估多次,以获得至少 4 个预测边界框,计算它们的 IOU 分数,并选出最高的一个来证明其上限性能;
- 然后得出平均边界框,计算 IOU 分数,以证明其平均性能。
测评中的局限性
当然原作者也提到了一些测评中的不足与限制:
只能进行定性而非定量的评估
鉴于 GPT-4V 只提供在线网页界面,只能手动上传测试用例,导致原评估报告在可扩展性方面受到限制,因此只能提供定性评估。
样本偏差
所选样本均来自在线网站,可能无法反映日常门诊中的数据分布情况。尤其是大多数评估病例都是异常病例,这可能会给评估带来潜在偏差。
注释或参考答案并不完整
从Radiopaedia或者PathologyOutlines网站上获得的参考描述大多没有结构,也没有标准化的放射学/病理学报告格式。特别是,这些报告中的大部分主要侧重于描述异常情况,而不是对病例进行全面描述,并不能直接作为完美的回复简单对比。
只有二维切片输入
在实际临床环境中,包括 CT、MRI 扫描在内的放射图像通常采用 3D DICOM 格式。然而,GPT-4V 最多只能支持四张二维图像的输入,所以原文在测评时只能输入二维关键切片或小片段(用于病理学)。
总之,尽管评估可能并不彻底详尽,但原作者们相信,这一分析仍旧可以为研究人员和医学专业人员提供了宝贵的见解,它揭示了多模态基础模型的当前能力,并可能激励未来建立医学基础模型的工作。
重要观察结果
原测评报告根据测评案例,概括了多个观察到的GPT-4V的表现特点:
放射案例部分
作者们根据92个放射学评估案例和20个定位案例得出如下观察结果:
- GPT-4V可以辨识出医疗图像的模态以及成像位置
对于大多数图像内容的模态识别、成像部位判定以及图像平面类别判定等任务,GPT4-V都表现出了良好的处理能力。例如,作者们指出GPT-4V能很容区分核磁共振、CT、X光等各种模态;判断图像所描述的人体具体部位;判断出核磁共振图像的轴位、失状位和冠状位等。
- GPT-4V几乎无法做出精确的诊断
作者们发现:一方面,OpenAI 似乎设置了安全机制,严格限制了GPT-4V做出直接诊断;另一方面,除了针对非常明显的诊断案例,GPT-4V的分析能力较差,仅局限于列举出可能存在的一系列疾病,而不能给出较为精确的诊断。
- GPT-4V可以生成出结构化的报告,但是内容大部分并不正确
GPT-4V在绝大多数情况下都能生成较为标准的报告,但作者们认为,相比于整合程度更高且内容更灵活的手写报告,在针对多模态或多帧图像时,它更倾向于逐图描述且缺乏综合能力。因此内容大部分参考价值较小且缺乏准确性。
- GPT-4V可以辨识出医学图像中的标记以及文本注释,但并不能理解其出现在图像中的意义
GPT-4V展现出较强的文本识别、标记识别等能力,并且会尝试利用这些标记进行分析。但作者们认为,其局限性在于:其一,GPT-4V总是会过度利用文本和标记且图像本身成为次要参考对象;其二,它鲁棒性较低,常常会误解图像中的医学注释和引导。
- GPT-4V可以辨识出医疗植入器械以及它们在图像中的位置
在大多数案例中,GPT4-V都能正确识别到植入人体的医疗设备,并较为准确地定位它们的位置。并且作者们发现,甚至在一些较为困难的案例中,可能出现诊断错误,但判断医疗设备识别正确的情况。
- GPT-4V面对多图输入时会遇到分析障碍
作者们发现,在面对同一模态的不同视角下的图像时,GPT-4V尽管会展现出相比于进输入单张图的更好的分析能力,但仍然倾向于分别对每张视图进行单独的分析;而在面对不同模态的图像混合输入时,GPT-4V更难得出综合了不同模态信息的合理分析。
- GPT-4V的预测极易受到患者疾病史的引导
作者们发现是否提供患者疾病史会对GPT-4V的回答产生较大影响。在提供疾病史的情况下,GPT-4V常常会将其作为关键点,对图中的潜在异常做出推断;而在不提供疾病史的情况下,GPT-4V则会更倾向于将图像作为正常案例进行分析。
- GPT-4V并不能在医学图像中定位到解剖结构和异常
作者们认为GPT-4V定位效果较差主要表现为:其一,GPT-4V在定位过程中总是会得到远离真实边界的预测框;其二,它在对同一幅图的多轮重复预测中表现出显著的随机性;其三,GPT-4V显示出了明显的偏置性,例如:脑部MRI图像中小脑一定位于底部。
- GPT-4V可以根据用户的多轮交互,改变它的既有回答。
GPT-4V可以在一系列的互动中修改其响应,使之正确。例如,在文中所示的例子中,作者们输入了子宫内膜异位症的MRI图像。GPT-4V最初错误地将盆腔MRI分类为膝关节MRI,从而得到了一个不正确的输出。但用户通过与GPT-4V的多轮互动对其进行纠正,最终做出了准确的诊断。
- GPT-4V幻觉问题严重,尤其倾向将患者叙述为正常即使异常信号极为显著。
GPT-4V总是生成出结构上看上去非常完整详实的报告,但其中的内容却并不正确,很多时候即使图像异常区域明显它仍旧会认为患者正常。
- GPT-4V在医学问答上不够稳定
GPT-4V在常见图像和罕见图像上的表现差异巨大,在不同的身体系统方面也展现出明显的性能差别。另外,对同一医学图像的分析可能会因更改prompt而产生不一致的结果,例如,如,GPT-4V在“ What is the diagnosis for this brain CT?” 的prompt下最初判断给定的图像为异常,但后来它生成了一个认为同一图像为正常的报告。这种不一致性强调了GPT-4V在临床诊断中的性能可能是不稳定和不可靠的。
- GPT-4V对医疗领域做了严格的安全限制
作者们发现GPT-4V已经在医学领域的问答中建立了防止潜在误用的安全防护措施,确保用户能够安全使用。例如,当GPT-4V被要求做出诊断时," Please provide the diagnosis for this chest X-ray.",它可能会拒绝给出答案,或强调“我不是专业医学建议的替代品”。在多数情况下,GPT-4V会倾向于使用包含“appears to be”或“could be”之类的短语来表示不确定性。
病理案例部分
此外,作者们为了探索GPT-4V在病理图像的报告生成和医学诊断方面的能力,对来自不同组织的20种恶性肿瘤病理图像开展了图像块级别的测试,并得出以下结论:
- GPT-4V能够进行准确的模态识别
在所有测试案例中,GPT-4V都可以正确地识别所有病理图像(H&E染色的组织病理图像)的模态。
- GPT-4V能够生成结构化报告
给定一个没有任何医学提示的病理图像,GPT-4V可以生成一个结构化且详细的报告来描述图像特征。在20个案例中,有7个案例能够使用如“组织结构”、“细胞特征”、“基质”、“腺体结构”、“细胞核”等术语明确地列出了
以上是178页!GPT-4V(ision)医疗领域首个全面案例测评:离临床应用与实际决策尚有距离的详细内容。更多信息请关注PHP中文网其他相关文章!