
贾佳亚团队联手剑桥清华等共推评测新范式 一秒侦破大模型'高分低能”

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB原创
- 2024-07-19 13:55:25554浏览

这是继今年 4 月发布堪称 GPT-4 + DALL-E-3 的王炸产品超强视觉语言模型 Mini-Gemini 后,港中文贾佳亚团队再次提出的极具代表性的作品。在 MR-Ben 的“监督”下,大模型不仅要像学生那样会答题,还要像老师那样会阅卷,真实的推理能力无所遁形。
MR-Ben 细致地评测了不少国内外一线的开源和闭源模型,如 GPT4-Turbo、Cluade3.5-Sonnet、Mistral-Large、Zhipu-GLM4、Moonshot-v1、Yi-Large、Qwen2-70B、Deepseek-V2 等,并进行了详尽的分析。
哪些看似美丽的大模型会被“卸妆”,哪个模型地表最强?目前该工作所有代码和数据均已开源,一起来看看!
Project Page: https://randolph-zeng.github.io/Mr-Ben.github.io/
Arxiv Page: https://arxiv.org/abs/2406.13975
Github Repo: https://github.com/dvlab-research/Mr-Ben
MR-Ben 秒破大模型“高分低能”
人工智能领域进入 GPT 时刻后,学术界和产业界共同发力,每月甚至每周都有新的模型问世。
大模型层出不穷,用什么标准来衡量大模型的具体能力?目前的主流方向是使用人类的标准化考试——选择题和填空题的方式去进行大模型评测。使用这套测试方式的好处有很多, 简单来说可以分为以下几点:
• 标准化考试易于量化和评测,标准明确,对就是对错就是错。
• 指标直观,在国内高考或者美国高考 SAT 里取得怎么样的分数易于比较和理解。
• 量化结果天然具有话题性(如 GPT4 轻松通过美国律师认证资格考试极为吸引眼球)。
但如果深究大模型的训练方式,就会发现这种逐步作答的思维链方式生成最终答案,并不“靠谱”。
问题正是出现在分步作答的流程上!
预训练模型在预训练时早已见过数以万亿级别的词元,很难说被评测的模型是否早已见过相应的数据,从而通过“背题”的方式回答正确。而在分步作答的时候,模型是否是基于正确的理解推理选出正确的选项,我们不得而知,因为评测的方式主要靠检查最终的答案。
尽管学术界不断地对诸如 GSM8K、MMLU 等数据集进行升级改造,如在 GSM8K 上引入多语言版本的 MGSM 数据集,在 MMLU 的基础上引入更难的题目等,依然无法摆脱选择或填空的窠臼。
并且,这些数据集都已面临着严重的饱和问题,大语言模型在这些指标上的数值已经见顶,并逐渐丧失了区分度。
为此,贾佳亚团队联合 MIT、清华、剑桥等多家知名高校,与国内头部标注公司合作,标注了一个针对复杂问题推理过程的评测数据集 MR-Ben。
MR-Ben 基于 GSM8K、MMLU、LogiQA、MHPP 等大模型预训练必测数据集的题目,进行了“阅卷式”的范式改造,生成的新数据集更难、更有区分度,更能真实地反映模型推理能力!
而贾佳亚团队这次的工作还针对现存评测痛点进行了针对性的改进:
不是害怕数据泄露导致的大模型背题导致分数虚高吗?不用重新找题出卷,也不用把题目变形来测试模型的稳健性,MR-Ben 直接让模型从答题者的学生身份,转变为对答题过程的“阅卷”模式,让大模型当老师来测试它对知识点的掌握情况!
不是担心模型对解题过程毫无知觉,有可能出现“幻觉”或错误的理解,蒙对答案吗?MR-Ben 直接招聘一批高水平的硕博标注者,对大量题目的解题过程进行精心标注。把解题过程是否正确,出错的位置,出错的原因都细致指出,比对大模型的阅卷结果和人类专家的阅卷结果来测试模型的知识点掌握情况。
具体来说,贾佳亚团队针对市面上主流的评测数据集 GSM8K、MMLU、LogiQA、MHPP 等数据集进行整理,并分成了数理化生、代码、逻辑、医药等多个类别,同时区分了不同的难度等级。针对每个类别、收集到的每个问题,团队精心收集了对应的分步解题过程,并经由专业的硕博标注者进行培训和标注。
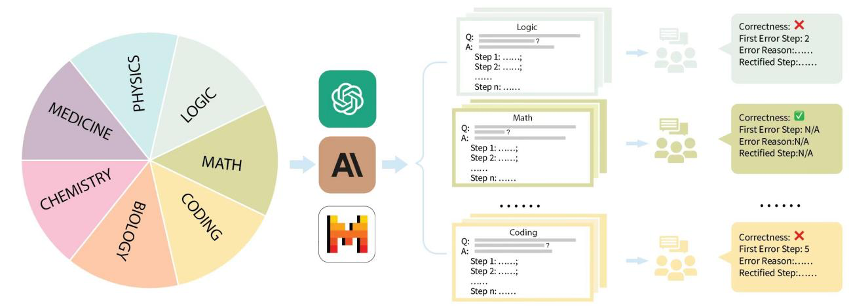
表现最佳大模型是它?
Next, let’s combine the specific examples given in MR-Ben’s work to see why the step-by-step method of generating final answers and related evaluations are unreliable.
As the evaluated "grading" model, GPT4-Turbo did not find the calculation errors hidden in the second step:
E.1 Mathematics
Subject: High School Mathematics
Question: Which smallest integer is divided by 4 as remainder 1, remainder 2 when divided by 3, remainder 2 when divided by 5?
Options: [A] 67 [B] 43 [C] 57 [D] 37
Answer: D
Sampling Model: Claude2
Model Solution Steps:
- Step 1: Check option A (67) when When 67 is divided by 4, the remainder is 3, not 1. So 67 is not the correct answer.
- Step 2: Check option B (43) When 43 is divided by 4, the remainder is 1. When 43 is divided by 3, the remainder is 3, not 2. So 43 is not the correct answer.
- Step 3: Check option C (57) When 57 is divided by 4, the remainder is 1. When 57 is divided by 3, the remainder is 0, not 2. So 57 is not the correct answer.
- Step 4: Check option D (37) When 37 is divided by 4, the remainder is 1. When 37 is divided by 3, the remainder is 1. When 37 is divided by 5, the remainder is 2.
-
Step 5: Option D (37) meets all conditions and is the correct answer.
Answer: Option D
Human annotation
Model answer correctness: Incorrect
First wrong step: Step 2
Model answer error reason:
In step 2, the model incorrectly calculated that the remainder of 43 divided by 4 is 1 instead of 3. The model assumes that when 43 is divided by 4 the remainder is 1, but the remainder should be 3. There is a calculation error here.The first correct step after correction: Step 2
When 43 is divided by 4, the remainder is 1. When 43 is divided by 3, the remainder is 1. When 43 is divided by 5, the remainder is 3, not 2. Therefore, 43 is not the correct answer.
Evaluation model: gpt-4-turbo
Model reply:
-Step 1: Step check the remainder of 67 divided by 4 and 3, and find that it meets the condition of being divided by 4 and remaining 3, which is a correct verification.
-Step 2: Check the remainders of dividing 43 by 4, 3, and 5, and find that the remainders of 1, 3, and 5 correctly match the expectations, except that the remainder of 5 does not meet the conditions.
-Step 3: Step Calculate the remainder of dividing 57 by 4 and 3, the remainders are 1 and 0 respectively. When 57 is divided by 3 the remainder does not meet the criteria.
-Step 4: Check and verify the remainders of dividing 37 by 4, 3, and 5. It is found that all expected remainders are accurate, and 37 meets all the conditions in the question.Is the solution process correct? Correct
The first error step: Not applicable
The reason for the first error step: Not applicable
It can be seen that when the question is given and the solution process is determined, the evaluation The language model method is transformed into allowing the model to "mark" the answer process, judge whether it is correct or incorrect, and point out the location and cause of the error. The accuracy of the solution process and the potential error locations can be calculated by comparing with the annotation results. The evaluation of model error steps and reasons can be handed over to GPT4 to determine whether the model is correct by comparing the explanation of the error reasons given by the annotator and the explanation of the error reasons of the model.
From the evaluation method, the method proposed by MR-Ben requires the model to conduct a detailed analysis of the premises, assumptions, and logic of each step in the problem-solving process, and to preview the reasoning process to determine whether the current step can lead to the correct direction. Answer. fenye1. This "grading" evaluation method is far more difficult than the evaluation method of just answering questions, but it can effectively avoid the problem of falsely high scores caused by the model's memorization of questions. It is difficult for a student who can only memorize questions to become a qualified marking teacher.
- Secondly, MR-Ben has achieved a large number of high-quality annotations by using manual and precise annotation process control, and the clever process design allows the evaluation method to be intuitively quantified.
- The Jiajiaya team also tested the top ten most representative language models and different versions. It can be seen that among the closed-source large language models, GPT4-Turbo has the best performance (although no calculation errors were found during "grading"). In most subjects, there are demos (k=1) and no demos. (k=0) are ahead of other models.
**Evaluation results of some open source large language models on the MR-Ben data set
It can be seen that the effects of some of the strongest open source large language models have caught up with some commercial models, and even the strongest closed source models are in MR-Ben. The performance on the Ben data set is still not saturated, and the difference between different models is large.
In addition, there are more interesting analyzes and findings in MR-Ben’s original paper, such as:

The open source models released by Qwen and Deepseek are not inferior to the PK closed source model even in the global echelon.
The pricing strategies and actual performance of different closed-source models are intriguing. Friends who are concerned about reasoning ability in usage scenarios can find their favorite model to use based on price and capabilities.
In low-resource scenarios, small models also have many highlights. In the MR-Ben evaluation, Phi-3-mini stood out among the small models, even higher than or the same as large models with tens of billions of parameters, showing the ability to fine-tune data importance.
MR-Ben scenes contain complex logical analysis and step-by-step inference. Too long context in Few-shot mode will confuse the model and cause a decline in performance.
MR-Ben has evaluated many generation-reflection-regeneration ablation experiments to check the differences between different prompting strategies and found that it has no effect on low-level models, and the effect on high-level models such as GPT4-Turbo is not obvious. On the contrary, for intermediate-level models, the effect is slightly improved because the wrong ones are always corrected and the right ones are corrected.
After roughly dividing the subjects evaluated by MR-Ben into knowledge-based, logical, computational, and algorithmic types, different models have their own advantages and disadvantages in different reasoning types.
The Jiajiaya team has uploaded a one-click evaluation method on github. All partners who are concerned about complex reasoning are welcome to evaluate and submit their own models. The team will update the corresponding leaderboard in a timely manner.
By the way, one-click evaluation using the official script only costs about 12M tokens. The process is very smooth, so give it a try!
Reference
Training Verifiers to Solve Math Word Problems (https://arxiv.org/abs/2110.14168)
Measuring Massive Multitask Language Understanding (https://arxiv.org/abs/2009.03300)
LogiQA: A Challenge Dataset for Machine Reading Comprehension with Logical Reasoning(https://arxiv.org/abs/2007.08124)
MHPP: Exploring the Capabilities and Limitations of Language Models Beyond Basic Code Generation(https://arxiv.org/abs/2405.11430)
Sparks of Artificial General Intelligence: Early experiments with GPT-4(https://arxiv.org/abs/2303.12712)
Qwen Technical Report(https://arxiv.org/abs/2309.16609)
DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model(https://arxiv.org/abs/2405.04434)
Textbooks Are All You Need(https://arxiv.org/abs/2306.11644)
Large Language Models Cannot Self- Correct Reasoning Yet(https://arxiv.org/abs/2310.01798)
以上是贾佳亚团队联手剑桥清华等共推评测新范式 一秒侦破大模型'高分低能”的详细内容。更多信息请关注PHP中文网其他相关文章!