
Ibis 声明式多引擎数据堆栈

- 王林原创
- 2024-07-19 03:34:101454浏览
长话短说
我最近看到了 Julien Hurault 撰写的关于多引擎数据堆栈的 Ju Data Engineering Newsletter。这个想法很简单;我们希望轻松地将代码移植到任何后端,同时保留随着新后端和功能的开发而扩展管道的灵活性。这至少需要以下高级工作流程:
- 使用 DuckDB、Polars、DataFusion、chdb 等将 SQL 查询的一部分卸载到无服务器引擎。
- 适合各种开发和部署场景的适当大小的管道。例如,开发人员可以在本地工作并放心地交付生产。
- 自动将数据库样式优化应用到您的管道。
在这篇文章中,我们深入探讨如何通过编程语言实现多引擎管道;我们建议使用可用于交互式和批处理用例的 Dataframe API,而不是 SQL。具体来说,我们展示了如何将管道分解为更小的部分,并在 DuckDB、pandas 和 Snowflake 上执行它们。我们还讨论了多引擎数据堆栈的优势,并重点介绍了该领域的新兴趋势。
这篇文章中实现的代码可以在 GitHub 上找到^[为了快速尝试 repo,我还提供了一个 nix flake]。时事通讯中的参考工作以及原始实现在这里。
概述
多引擎数据堆栈管道的工作原理如下:一些数据进入 S3 存储桶,进行预处理以删除任何重复项,然后加载到 Snowflake 表中,在其中使用 ML 或 Snowflake 特定函数进一步转换^[请注意我们不会去实现 Snowflake 中可能实现的事物类型,并假设这是工作流程的要求]。该管道将订单作为 parquet 文件保存到登陆位置,经过预处理,然后存储在 S3 存储桶中的暂存位置。然后,暂存数据会加载到 Snowflake 中,以将下游 BI 工具连接到它。该管道通过 SQL dbt 连接在一起,每个后端都有一个模型,并且时事通讯选择 Dagster 作为编排工具。
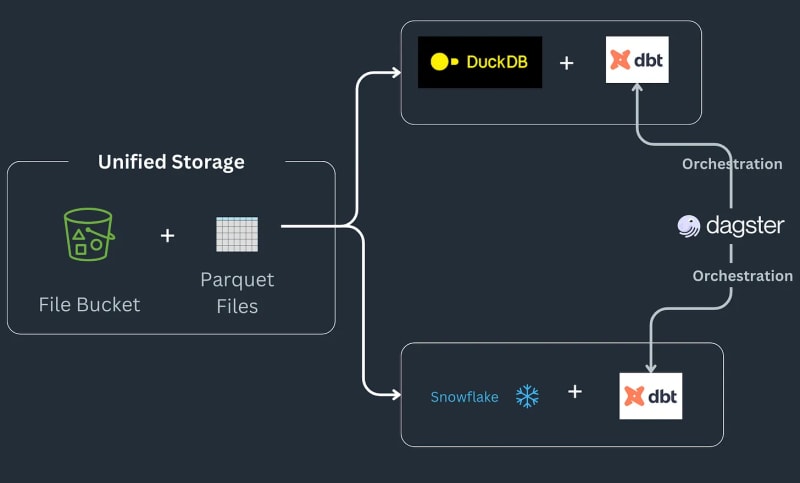
今天,我们将深入研究如何将 pandas 代码转换为 Ibis 表达式,重现 Julien Hurault 的多引擎堆栈示例 1 的完整示例。我们不使用 dbt 模型和 SQL,而是使用 ibis 和一些 Python 从 shell 编译和编排 SQL 引擎。通过将代码重写为 Ibis 表达式,我们可以以声明方式构建具有延迟执行的数据管道。此外,Ibis 支持 20 多个后端,因此我们只需编写一次代码即可将 ibis.exprs 移植到多个后端。为了进一步简化,我们将 Dagster 提供的调度和任务编排2 留给读者。
多引擎数据栈核心概念
以下是 Julien 时事通讯中概述的多引擎数据堆栈的核心概念:
- 多引擎数据堆栈:这个概念涉及结合不同的数据引擎,如 Snowflake、Spark、DuckDB 和 BigQuery。这种方法旨在降低成本、限制供应商锁定并提高灵活性。 Julien 提到,对于某些基准查询,与 Snowflake 相比,使用 DuckDB 可以显着降低成本。
- 跨引擎查询层的开发:新闻通讯重点介绍了技术进步,这些进步允许数据团队将 SQL 或 Dataframe 代码从一个引擎无缝转换到另一个引擎。这一发展对于保持不同引擎的效率至关重要。
- Apache Iceberg 和替代方案的使用: 虽然 Apache Iceberg 被视为潜在的统一存储层,但其集成尚未成熟,无法在 dbt 项目中使用。相反,Julien 在他的概念验证 (PoC) 中选择使用存储在 S3 中的 Parquet 文件,由 DuckDB 和 Snowflake 访问。
- PoC 中的编排和引擎: 在该项目中,Julien 使用 Dagster 作为编排器,这简化了 dbt 项目中不同引擎的作业调度。此 PoC 中组合的引擎是 DuckDB 和 Snowflake。
为什么选择 DataFrames 和 Ibis?
虽然上面的管道对于 ETL 和 ELT 来说很好,但有时我们需要完整的编程语言的功能,而不是像 SQL 这样的查询语言,例如调试、测试、复杂的 UDF 等。对于科学探索,交互式计算至关重要,因为数据科学家需要快速迭代代码、可视化结果并根据数据做出决策。
DataFrame 是这样一种数据结构:DataFrame 用于处理有序数据并以交互方式对其应用计算操作。它们提供了能够通过 SQL 样式操作处理大数据的灵活性,而且还提供了较低级别的控制来编辑单元格级别更改(如 Excel 工作表)。 通常,期望所有数据都在内存中处理并且通常适合内存。此外,DataFrame 可以轻松地在延迟/批处理和交互模式之间来回切换。
DataFrames 擅长 ^[没有双关语] 使人们能够应用用户定义的函数并将用户从 SQL 的限制中释放出来,即您现在可以重用代码,测试您的操作,轻松扩展关系机制以执行复杂的操作。 DataFrame 还可以轻松地将数据的表格表示快速转换为机器学习库所期望的数组和张量。
专业和进程中的数据库,例如DuckDB for OLAP3 正在模糊像 Snowflake 这样的远程重量级数据库和像 pandas 这样符合人体工程学的库之间的界限。我们相信这是一个机会,允许 DataFrame 处理大于内存的数据,同时保持本地 Python shell 的交互性期望和开发人员的感觉,让大于内存的数据感觉很小。
技术深度探讨
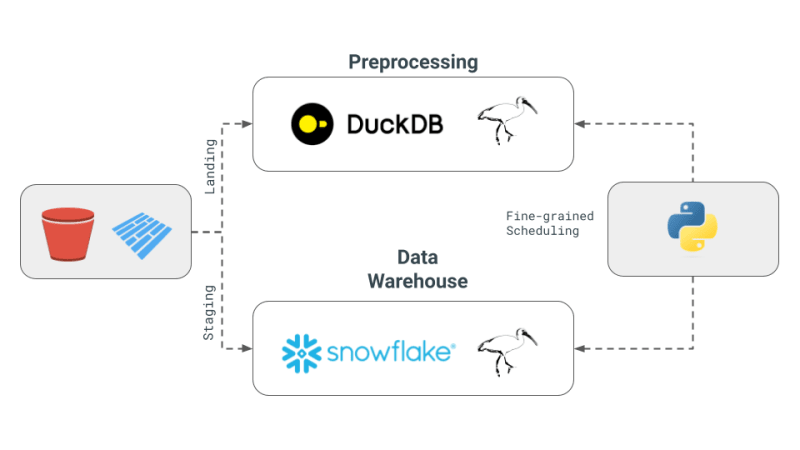
我们的实现重点关注之前提出的 4 个概念:
- 多引擎数据栈:我们将使用 DuckDB、pandas 和 Snowflake 作为引擎。
- 跨引擎查询层:我们将使用 Ibis 编写表达式并编译它们以在 DuckDB、pandas 和 Snowflake 上运行。
- Apache Iceberg 和替代方案:我们将使用本地存储的 Parquet 文件作为我们的存储层,并期望使用 s3fs 包轻松扩展到 S3。
- PoC 中的编排和引擎:我们将专注于引擎的细粒度调度,而将编排留给读者。与编排框架相比,细粒度调度更适合 Ray、Dask、PySpark。 Dagster、Airflow 等
用pandas实现

pandas 是典型的 DataFrame 库,也许提供了实现上述工作流程的最简单方法。首先,我们借用时事通讯中的实现来生成随机数据。
#| echo: false
import pandas as pd
from multi_engine_stack_ibis.generator import generate_random_data
generate_random_data("landing/orders.parquet")
df = pd.read_parquet("landing/orders.parquet")
deduped = df.drop_duplicates(["order_id", "dt"])
pandas 的实现在风格上是命令式的,并且被设计成可以容纳内存的数据。 pandas API 很难编译为 SQL 及其所有细微差别,并且很大程度上位于其自己的特殊位置,将 Python 可视化、绘图、机器学习、人工智能和复杂处理库结合在一起。
pt.write_pandas(
conn,
deduped,
table_name="T_ORDERS",
auto_create_table=True,
quote_identifiers=False,
table_type="temporary"
)
使用 pandas 运算符进行重复数据删除后,我们准备将数据发送到 Snowflake。 Snowflake 有一个名为 write_pandas 的方法,对于我们的用例来说非常方便。
使用 Ibis aka Ibisify 实施
pandas 的一个限制是它有自己的 API,不能完全映射回关系代数。 Ibis 就是这样一个库,它实际上是由构建 pandas 的人构建的,以提供可以映射回多个 SQL 后端的健全的表达式系统。 Ibis 从 dplyr R 包中汲取灵感,构建了一个新的表达式系统,可以轻松映射回关系代数,从而编译为 SQL。它在风格上也是声明性的,使我们能够在完整的逻辑计划或表达式上应用数据库风格优化。 Ibis 是实现可组合性的关键组件,正如优秀的可组合代码中所强调的那样。
#| echo: false
import pathlib
import ibis
import ibis.backends.pandas.executor
import ibis.expr.types.relations
from ibis import _
from multi_engine_stack_ibis.generator import generate_random_data
from multi_engine_stack_ibis.utils import (MyExecutor, checkpoint_parquet,
create_table_snowflake,
replace_unbound)
from multi_engine_stack_ibis.connections import make_ibis_snowflake_connection
ibis.backends.pandas.executor.PandasExecutor = MyExecutor
setattr(ibis.expr.types.relations.Table, "checkpoint_parquet", checkpoint_parquet)
setattr(
ibis.expr.types.relations.Table,
"create_table_snowflake",
create_table_snowflake,
)
ibis.set_backend("pandas")
p_staging = pathlib.Path("staging/staging.parquet")
p_landing = pathlib.Path("landing/orders.parquet")
snow_backend = make_ibis_snowflake_connection(database="MULTI_ENGINE", schema="PUBLIC", warehouse="COMPUTE_WH")
expr = (
ibis.read_parquet(p_landing)
.mutate(
row_number=ibis.row_number().over(group_by=[_.order_id], order_by=[_.dt]))
.filter(_.row_number == 0)
.checkpoint_parquet(p_staging)
.create_table_snowflake("T_ORDERS")
)
expr
Ibis 表达式将自身打印为类似于数据库中传统逻辑计划的计划。逻辑计划是关系代数运算符的树,描述需要执行的计算。然后,该计划由查询优化器优化,并转换为由查询执行器执行的物理计划。 Ibis 表达式与逻辑计划类似,它们描述需要执行的计算,但不会立即执行。相反,它们被编译成 SQL 并在需要时在后端执行。逻辑计划通常比 Dask 等任务调度框架生成的 DAG 具有更高的粒度。理论上,这个计划可以编译成 Dask 的 DAG。
While pandas is embedded and is just a pip install away, it still has much documented limitations with plenty of performance improvements left on the table. This is where the recent embedded databases like DuckDB fill the gap of packing the full punch of a SQL engine, with all of its optimizations and benefiting from years of research that is as easy to import as is pandas. In this world, at minimum we can delegate all relational and SQL parts of our pipeline in pandas to DuckDB and only get the processed data ready for complex user defined Python.
Now, we are ready to take our Ibisified code and compile our expression above to execute on arbitrary engines, to truly realize the write-once-run-anywhere paradigm: We have successfully decoupled our compute engine with the expression system describing our computation.
Multi-Engine Data Stack w/ Ibis
DuckDB + pandas + Snowflake
Let's break our expression above into smaller parts and have them run across DuckDB, pandas and Snowflake. Note that we are not doing anything once the data lands in Snowflake and just show that we can select the data. Instead, we are leaving that up to the user's imagination what is possible with Snowflake native features.
Notice our expression above is bound to the pandas backend. First, lets create an UnboundTable expression to not have to depend on a backend when writing our expressions.

schema = {
"user_id": "int64",
"dt": "timestamp",
"order_id": "string",
"quantity": "int64",
"purchase_price": "float64",
"sku": "string",
"row_number": "int64",
}
first_expr_for = (
ibis.table(schema, name="orders")
.mutate(
row_number=ibis.row_number().over(group_by=[_.order_id], order_by=[_.dt])
)
.filter(_.row_number == 0)
)
first_expr_for
Next, we replace the UnboundTable expression with the DuckDB backend and execute it with to_parquet method4. This step is covered by the checkpoint_parquet operator that we added to pandas backend above. Here is an excellent blog that discusses inserting data into Snowflake from any Ibis backend with to_pyarrow functionality.
data = pd.read_parquet("landing/orders.parquet")
duck_backend = ibis.duckdb.connect()
duck_backend.con.execute("CREATE TABLE orders as SELECT * from data")
bind_to_duckdb = replace_unbound(first_expr_for, duck_backend)
bind_to_duckdb.to_parquet(p_staging)
to_sql = ibis.to_sql(bind_to_duckdb)
print(to_sql)
Once the above step creates the de-duplicated table, we can then send data to Snowflake using the pandas backend. This functionality is covered by create_table_snowflake operator that we added to pandas backend above.
second_expr_for = ibis.table(schema, name="T_ORDERS") # nothing special just a reading the data from orders table
snow_backend.create_table("T_ORDERS", schema=second_expr_for.schema(), temp=True)
pandas_backend = ibis.pandas.connect({"T_ORDERS": pd.read_parquet(p_staging)})
snow_backend.insert("T_ORDERS", pandas_backend.to_pyarrow(second_expr_for))
Finally, we can select the data from the Snowflake table to verify that the data has been loaded successfully.
third_expr_for = ibis.table(schema, name="T_ORDERS") # add you Snowflake ML functions here third_expr_for
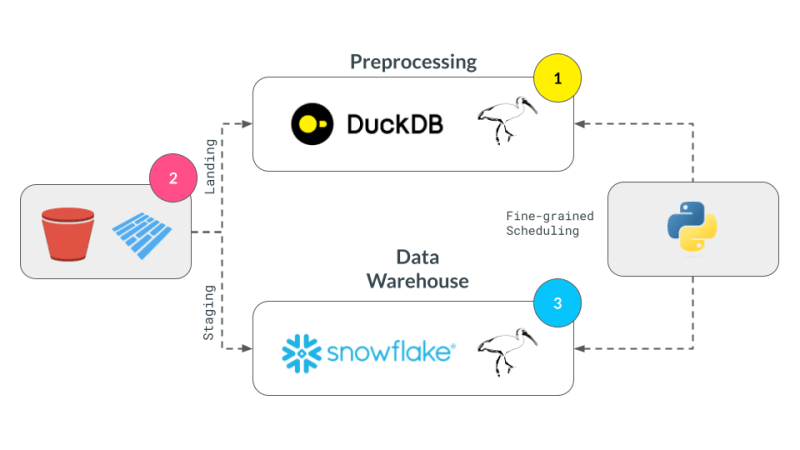
We successfully broke up our computation in pieces, albeit manually, and executed them across DuckDB, pandas, and Snowflake. This demonstrates the flexibility and power of a multi-engine data stack, allowing users to leverage the strengths of different engines to optimize their data processing pipelines.
Acknowledgments
I'd like to thank Neal Richardson, Dan Lovell and Daniel Mesejo for providing the initial feedback on the post. I highly appreciate the early review and encouragement by Wes McKinney.
Resources
- The Road to Composable Data Systems
- The Composable Codex
- Apache Arrow
- Multi-Engine Data Stack Newsleter v0 v1
- Ibis, the portable dataframe library
- dbt Docs
- Dagster Docs
- LanceDB
- KuzuDB
- DuckDB
-
In this post, we have primarily focused on v0 of the multi-engine data stack. In the latest version, Apache Iceberg is included as a storage and data format layer. NYC Taxi data is used instead of the random Orders data treated in this and v0 of the posts. ↩
-
Orchestration Vs fine-grained scheduling: ↩
- The orchestration is left to the reader. The orchestration can be done using a tool like Dagster, Prefect, or Apache Airflow.
- The fine-grained scheduling can be done using a tool like Dask, Ray, or Spark.
-
Some of the examples of in-process databases is described in this post extending DuckDB example above to newer purpose built databases like LanceDB and KuzuDB. ↩
-
The Ibis docs use backend.to_pandas(expr) commands to bind and run the expression in the same go. Instead, we use replace_unbound method to show a generic way to just compile the expression and not execute it to said backend. This is just for illustration purposes. All the code below, uses the backend.to_pyarrow methods from here on. ↩
以上是Ibis 声明式多引擎数据堆栈的详细内容。更多信息请关注PHP中文网其他相关文章!