
北大推出全新机器人多模态大模型!面向通用和机器人场景的高效推理和操作

- 王林原创
- 2024-07-16 03:51:40513浏览

AIxiv专栏是本站发布学术、技术内容的栏目。过去数年,本站AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢迎投稿或者联系报道。投稿邮箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com
为了赋予机器人端到端的推理和操纵能力,本文创新性地将视觉编码器与高效的状态空间语言模型集成,构建了全新的 RoboMamba 多模态大模型,使其具备视觉常识任务和机器人相关任务的推理能力,并都取得了先进的性能表现。同时,本文发现当 RoboMamba 具备强大的推理能力后,我们可以通过极低的训练成本使得 RoboMamba 掌握多种操纵位姿预测能力。

论文:RoboMamba: Multimodal State Space Model for Efficient Robot Reasoning and Manipulation
论文链接:https://arxiv.org/abs/2406.04339
项目主页:https://sites.google.com/view/robomamba-web
Github:https://github.com/lmzpai/roboMamba

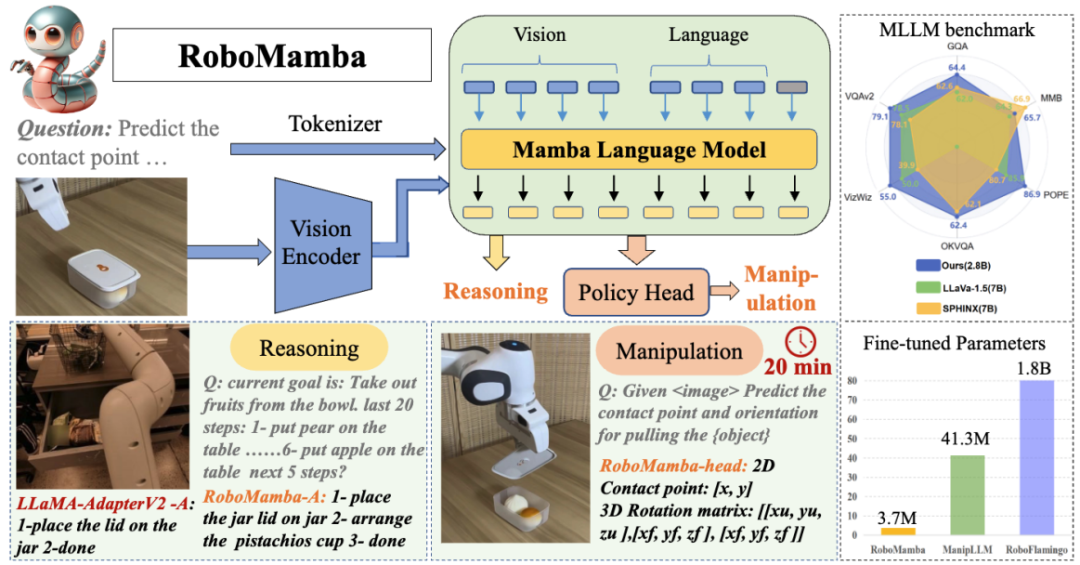
我们创新地将视觉编码器与高效的 Mamba 语言模型集成,构建了全新的端到端机器人多模态大模型,RoboMamba,其具备视觉常识和机器人相关的全面推理能力。 为了使 RoboMamba 具备末端执行器操纵位姿预测能力,我们探索了一种使用简单 Policy Head 的高效微调策略。我们发现,一旦 RoboMamba 达到足够的推理能力,它可以以极低的成本掌握操纵位姿预测技能。 在我们的大量实验中,RoboMamba 在通用和机器人推理评估基准上表现出色,并在模拟器和真实世界实验中展示了令人印象深刻的位姿预测结果。
问题陈述
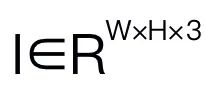 和语言问题
和语言问题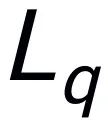 生成语言答案
生成语言答案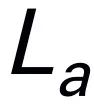 ,表示为
,表示为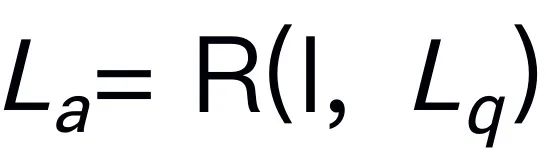 。推理答案通常包含单独的子任务
。推理答案通常包含单独的子任务 对于一个问题
对于一个问题 。例如,当面对一个计划问题,如 “如何收拾桌子?”,反应通常包括 “第一步:捡起物体” 和 “第二步:把物体放入盒子” 等步骤。对于动作预测,我们利用一个高效简单的策略头 π 来预测动作
。例如,当面对一个计划问题,如 “如何收拾桌子?”,反应通常包括 “第一步:捡起物体” 和 “第二步:把物体放入盒子” 等步骤。对于动作预测,我们利用一个高效简单的策略头 π 来预测动作 。根据之前的工作,我们使用 6-DoF 来表达 Franka Emika Panda 机械臂的末端执行器位姿。6 自由度包括末端执行器位置
。根据之前的工作,我们使用 6-DoF 来表达 Franka Emika Panda 机械臂的末端执行器位姿。6 自由度包括末端执行器位置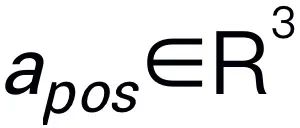 表示三维坐标,方向
表示三维坐标,方向 表示旋转矩阵。如果训练抓取任务,我们将抓夹状态添加到位姿预测中,从而实现 7-DoF 控制。
表示旋转矩阵。如果训练抓取任务,我们将抓夹状态添加到位姿预测中,从而实现 7-DoF 控制。状态空间模型 (SSM)
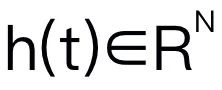 ,将 1D 输入序列
,将 1D 输入序列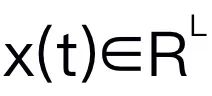 投影到 1D 输出序列
投影到 1D 输出序列 。SSM 由三个关键参数组成:状态矩阵
。SSM 由三个关键参数组成:状态矩阵 ,输入矩阵
,输入矩阵 ,输出矩阵
,输出矩阵 。SSM 可以表示为:
。SSM 可以表示为: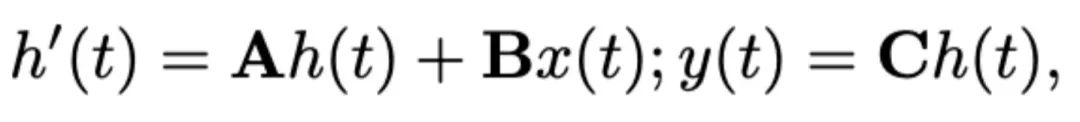
 和
和 。离散化采用零阶保持方法,定义如下:
。离散化采用零阶保持方法,定义如下: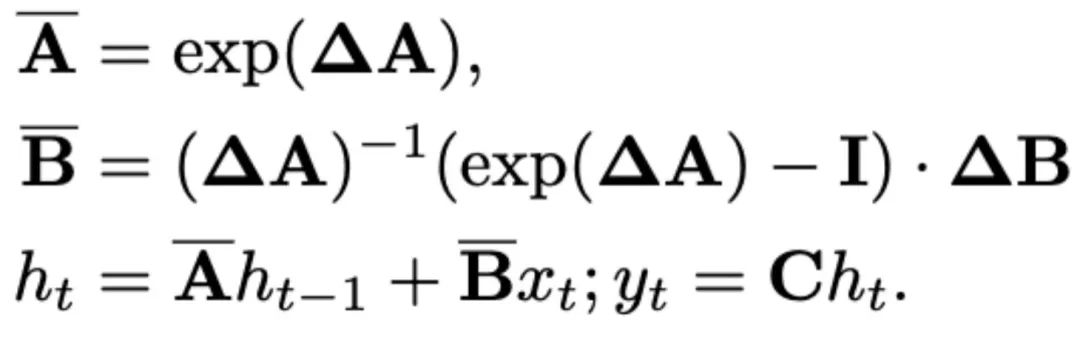
 ,实现更好的内容感知推理。下图 3 中展示了 Mamba block 的详细信息。
,实现更好的内容感知推理。下图 3 中展示了 Mamba block 的详细信息。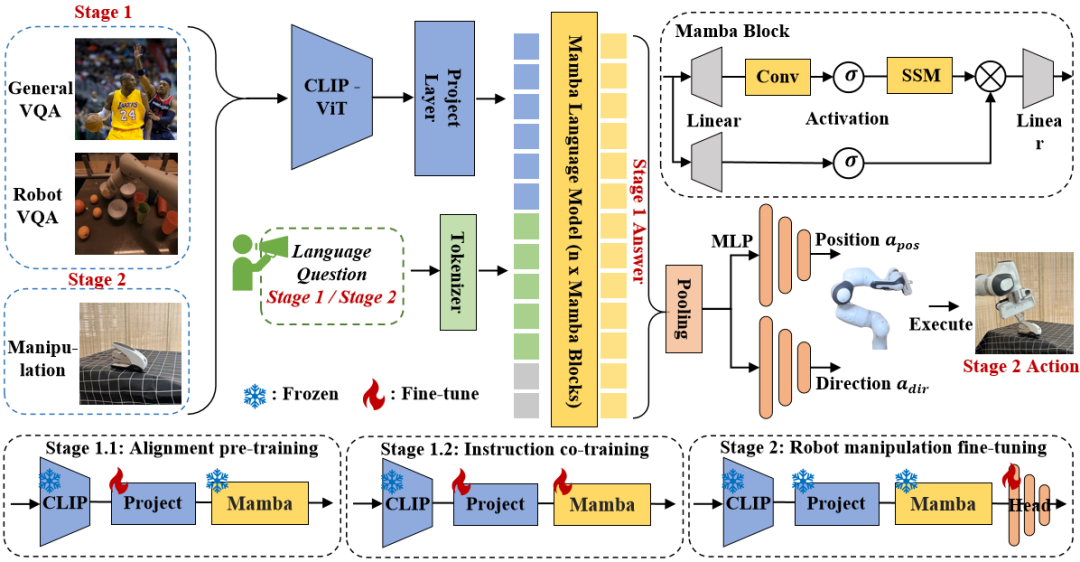
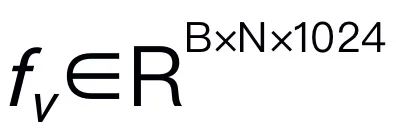 ,其中 B 和 N 分别表示 batch size 和 token 数。与最近的 MLLMs 不同,我们不采用视觉编码器集成技术,这种技术使用了多种骨干网络(即 DINOv2、CLIP-ConvNeXt、CLIP-ViT)进行图像特征提取。集成引入了额外的计算成本,严重影响了机器人 MLLM 在现实世界中的实用性。因此,我们证明了,当高质量数据和适当的训练策略结合时,简单且直接的模型设计也能实现强大的推理能力。为了使 LLM 理解视觉特征,我们使用多层感知器(MLP)将视觉编码器连接到 LLM。通过这个简单的跨模态连接器,RoboMamba 可以将视觉信息转换为语言嵌入空间
,其中 B 和 N 分别表示 batch size 和 token 数。与最近的 MLLMs 不同,我们不采用视觉编码器集成技术,这种技术使用了多种骨干网络(即 DINOv2、CLIP-ConvNeXt、CLIP-ViT)进行图像特征提取。集成引入了额外的计算成本,严重影响了机器人 MLLM 在现实世界中的实用性。因此,我们证明了,当高质量数据和适当的训练策略结合时,简单且直接的模型设计也能实现强大的推理能力。为了使 LLM 理解视觉特征,我们使用多层感知器(MLP)将视觉编码器连接到 LLM。通过这个简单的跨模态连接器,RoboMamba 可以将视觉信息转换为语言嵌入空间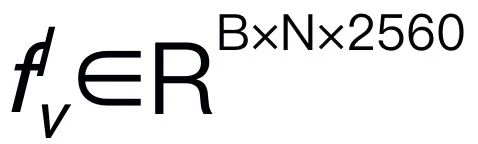 。
。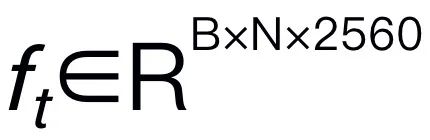 ,然后与视觉 token 连接(cat)并输入 Mamba。我们利用 Mamba 强大的序列建模来理解多模态信息,并使用有效的训练策略来开发视觉推理能力(如下一节所述)。输出 token (
,然后与视觉 token 连接(cat)并输入 Mamba。我们利用 Mamba 强大的序列建模来理解多模态信息,并使用有效的训练策略来开发视觉推理能力(如下一节所述)。输出 token ( ) 然后被解码(det),生成自然语言响应
) 然后被解码(det),生成自然语言响应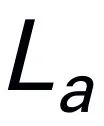 。模型的前向过程可以表示如下:
。模型的前向过程可以表示如下: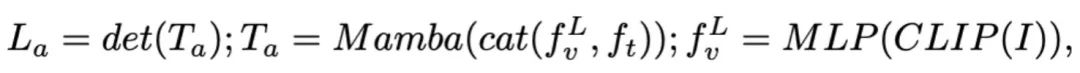
Stage 1.1:对齐预训练。
Stage 1.2:指令共同训练。
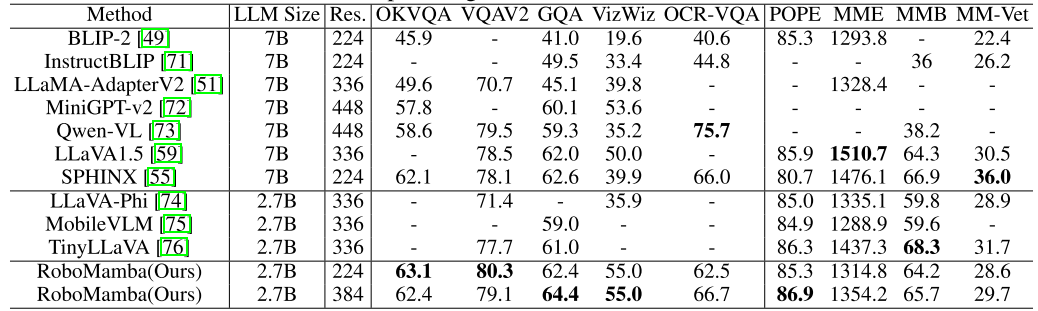






以上是北大推出全新机器人多模态大模型!面向通用和机器人场景的高效推理和操作的详细内容。更多信息请关注PHP中文网其他相关文章!
声明:
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系admin@php.cn