AIxiv专栏是本站发布学术、技术内容的栏目。过去数年,本站AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢迎投稿或者联系报道。投稿邮箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com。
近年来,大型语言模型(LLM)在数学应用题和数学定理证明等任务中取得了长足的进步。数学推理需要严格的、形式化的多步推理过程,因此是 LLMs 推理能力进步的关键里程碑, 但仍然面临着重要的挑战。以往的研究工作,如思维链(CoT),揭示了中间步骤引导的有效性。然而,人工地去标注这样的中间步骤需要花费大量人力和时间成本,而自动合成的数据也容易在正确性和人类易读性上面出现问题。本文中,来自香港城市大学、中山大学、华为诺亚方舟实验室等机构的研究人员提出了一个统一的数学推理数据合成框架 MUSTARD,能够生成大量的、正确的且人类可读可理解的高质量数学推理数据。
- 论文题目:MUSTARD: Mastering Uniform Synthesis of Theorem and Proof Data
- 论文链接:https://openreview.net/forum?id=8xliOUg9EW
- 代码链接:https://github.com/Eleanor-H/MUSTARD
- 数据集链接:https://drive.google.com/file/d/1yIVAVqpkC2Op7LhisG6BJJ_-MavAMr1B/view
- 作者主页:https://eleanor-h.github.io/
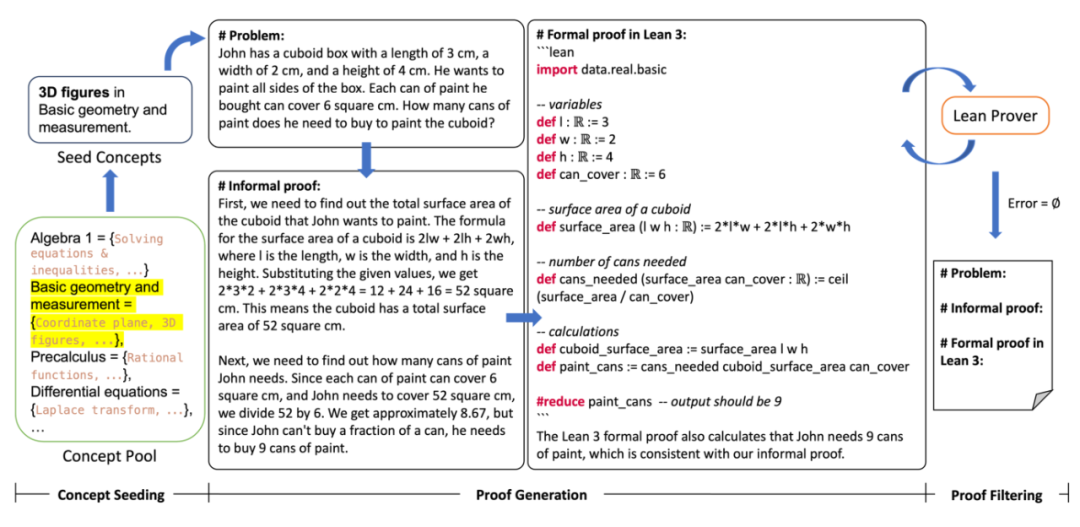
第一阶段,概念采集:首先定义并建立了一个数学概念库,涵盖小学、初中、高中和高等教育四个教育阶段的概念,每个教育阶段有 5 至 9 个数学领域,涵盖代数和几何等不同类型的数学问题。每个领域都包含细分的数学概念,如多项式运算或因式分解。随后从数学概念库当中抽取一个或多个数学概念作为种子,规定所生成的问题类别。第二阶段,数据生成:根据数学概念提示大型语言模型生成数学问题和多步的求解过程。具体来说,MUSTARD 利用大型语言模型生成自然语言和代码的能力,提示大型语言模型完成三项任务:(T1)生成与给定概念相关的数学问题;(T2)用自然语言给出问题的求解;(T3)自动形式化,将自然语言求解转化为 Lean 3 的形式化求解。第三阶段,形式化验证:使用交互式的形式化定理证明器的验证筛选出准确的求解过程。MUSTARD 将 Lean 3 的形式化求解输送给 Lean 形式化验证器后,如果定理证明器没有返回错误信息,则相应的数据会被收集到有效集合中。否则,MUSTARD 会从定理证明器那里收集错误信息,并提示语言模型修改形式化求解。MUSTARD 会进行多轮验证和自我纠正,直到获得有效的形式化求解。 MUSTARD 框架由概念采集、数据生成、形式化验证三阶段组成。为了探究 MUSTARD 生成数据的质量,研究团队请掌握数学和 Lean 3 语言专业人士对数据进行了质量检查。他们从生成的数据中随机抽取 200 条,其中 100 条通过 Lean 定理证明器的验证(有效组),100 条没有通过验证(无效组)。质量检查涵盖每条数据的四个部分(即自然语言问题描述、自然语言求解、形式化问题描述和形式化求解),包括了正确性和一致性的检查。具体来说,高质量的数据应该有正确的自然语言问题描述 (D1) 和正确的问题求解 (D4)。形式化问题描述和求解应该与自然语言的问题描述和求解保持一致(D5、D6)。此外,数据应该符合指定的数学概念 (D2) 和问题类型 (D3)。表 3 展示了这六个检查维度及要求。如果数据符合要求,则在维度中得 1 分,否则得 0 分。表 3 显示了有效组和无效组在每个维度上的准确率和相应的 p 值。(D1)和(D4)的显著差异性说明了 MUSTARD 生成的问题和答案的正确性。(D6)的显著差异性表明了所生成的数据的自然语言描述和形式化描述的高度一致性。为了评估 MUSTARDSAUCE 对提高数学推理能力的影响,研究团队利用这些数据对较小规模的语言模型进行了微调,并在数学应用题(MWP)和自动定理证明(ATP)上对其进行了评估。本文对比了 MUSTARDSAUCE 数据集的以下组合数据的有效性:
- MUSTARDSAUCE-valid:经过了 Lean 形式化证明器验证的 5866 条数据;
- MUSTARDSAUCE-invalid:未能通过 Lean 形式化证明器验证的 5866 条数据;
- MUSTARDSAUCE-random:随机的 5866 条数据;
- MUSTARDSAUCE-tt:MUSTARD 生成的所有 28316 条数据。
研究团队采用 LoRA [1] 在每个组合数据上微调开源 GPT2-large [2]、Llama 2-7B 和 Llama 2-70B [3]。对于数学应用题任务,他们使用 GSM8K [4] 和 MATH [5][6] 数据集进行评估。在评估自动定理证明时,研究团队使用了 Mathlib [8]和 miniF2F [7] 基准。此外,他们也在 MUSTARDSAUCE-test 上进行了评估。总的来说,在 MUSTARDSAUCE 上对模型进行微调提高了模型的数学推理能力。在自动定理证明(下表 5)和数学应用题求解(下表 4),使用 MUSTARDSAUCE-valid 进行微调与使用 MUSTARDSAUCE-random 进行微调相比,平均相对性能提高了 18.15%(下表 5)和 11.01%(下表 4)。对于自动定理证明,经过微调的 Llama 2-7B 平均性能提升 15.41%,经过微调的 GPT 2-large 平均性能提升 20.89%。对于数学应用题求解,经过微调的 Llama 2-7B 平均性能提升 8.18%,经过微调的 GPT 2-large 平均性能提升 15.41%。此外,经过 MUSTARDSAUCE-tt 微调的模型虽在微调数据量上有绝对优势,但其性能不及经过 MUSTARDSAUCE-valid 微调的模型性能。Llama 2-70B 的更多结果。在微调更大的语言模型时,MUSTARDSAUCE 数据仍然有效。本文开源了 MUSTARDSAUCE 数据集。其中每一个数据都包含了自然语言的问题描述和多步求解,以及对偶的形式化语言 Lean 3 的问题描述和多步求解。MUSTARDSAUCE 的数据包括了数学应用题和定理证明题,涵盖了从小学到高等教育阶段的难度分级。题目的推理步数随着题目难度的增长而增长。最难的题目需要 30 步左右的求解步骤,约 20 个 Lean 3 tactics。数据集下载:https://drive.google.com/file/d/1yIVAVqpkC2Op7LhisG6BJJ_-MavAMr1B/view研究团队还基于 MUSTARDSAUCE 数据集的自然语言和 Lean 形式语言的对偶数据,开放了一个自动形式化(autoformalization)和一个自动非形式化(auto-informalization)的挑战赛。此外,研究团队还同步开放了自动定理生成和证明(automated theorem generation and proving)和代码辅助的运筹优化问题自动求解(automated optimization problem-solving with code)等两个挑战赛赛道。比赛时间为 2024 年 4 月 3 日 – 5 月 27 日。优胜队伍将有机会参加 7 月 26 日于奥地利维也纳举办的 ICML 2024 AI for Math 研讨会。
- 赛道 1-1 (自动形式化):https://www.codabench.org/competitions/2436/
- 赛道 1-2 (自动非形式化):https://www.codabench.org/competitions/2484/
- 赛道 2 (自动定理生成和证明):https://www.codabench.org/competitions/2437/
- 赛道 3 (代码辅助的运筹优化问题自动求解):https://www.codabench.org/competitions/2438/
[1] Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. Lora: Low-rank adaptation of large language models. arXiv preprint arXiv:2106.09685, 2021.[2] Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever, et al. Language models are unsupervised multitask learners. OpenAI blog, 1 (8):9, 2019.[3] Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Niko- lay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, Dan Bikel, Lukas Blecher, Cristian Canton-Ferrer, Moya Chen, Guillem Cucurull, David Esiobu, Jude Fernandes, Jeremy Fu, Wenyin Fu, Brian Fuller, Cynthia Gao, Vedanuj Goswami, Naman Goyal, Anthony Hartshorn, Saghar Hosseini, Rui Hou, Hakan Inan, Marcin Kardas, Viktor Kerkez, Madian Khabsa, Isabel Kloumann, Artem Korenev, Punit Singh Koura, Marie-Anne Lachaux, Thibaut Lavril, Jenya Lee, Diana Liskovich, Yinghai Lu, Yuning Mao, Xavier Martinet, Todor Mihaylov, Pushkar Mishra, Igor Molybog, Yixin Nie, Andrew Poulton, Jeremy Reizenstein, Rashi Rungta, Kalyan Saladi, Alan Schelten, Ruan Silva, Eric Michael Smith, Ranjan Subramanian, Xiaoqing Ellen Tan, Binh Tang, Ross Taylor, Adina Williams, Jian Xiang Kuan, Puxin Xu, Zheng Yan, Iliyan Zarov, Yuchen Zhang, Angela Fan, Melanie Kambadur, Sharan Narang, Aure ́lien Rodriguez, Robert Stojnic, Sergey Edunov, and Thomas Scialom. Llama 2: Open foundation and fine- tuned chat models. CoRR, abs/2307.09288, 2023. doi: 10.48550/arXiv.2307.09288. URL https://doi.org/10.48550/arXiv.2307.09288.[4] Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training verifiers to solve math word problems. CoRR, abs/2110.14168, 2021.[5] Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the MATH dataset. In Joaquin Vanschoren and Sai-Kit Yeung (eds.), Proceedings of the Neural Information Processing Systems Track on Datasets and Benchmarks 1, NeurIPS Datasets and Benchmarks 2021, Decem- ber 2021, virtual, 2021.[6] Hunter Lightman, Vineet Kosaraju, Yura Burda, Harri Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. Let’s verify step by step. arXiv preprint arXiv:2305.20050, 2023.[7] Kunhao Zheng, Jesse Michael Han, and Stanislas Polu. minif2f: a cross-system benchmark for formal olympiad-level mathematics. In The Tenth International Conference on Learning Repre- sentations, ICLR 2022, Virtual Event, April 25-29, 2022. OpenReview.net, 2022.[8] https://github.com/leanprover-community/mathlib以上是ICLR 2024 Spotlight | 无惧中间步骤,MUSTARD可生成高质量数学推理数据的详细内容。更多信息请关注PHP中文网其他相关文章!