
谷歌「诚意之作」,开源9B、27B版Gemma2,主打高效、经济!

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB原创
- 2024-06-29 00:59:211135浏览
性能翻倍的Gemma 2, 让同量级的Llama3怎么玩?


性能卓越:Gemma 2 27B模型在其同体积类别中提供了最佳性能,甚至可以与体积超过其两倍的模型竞争。 9B Gemma 2模型也在其同等体积类别中表现出色,并超越了Llama 3 8B和其他同类开放模型。 高效率、低成本:27B Gemma 2模型设计用于在单个Google Cloud TPU主机、NVIDIA A100 80GB Tensor Core GPU或NVIDIA H100 Tensor Core GPU上以全精度高效运行推理,在保持高性能的同时大幅降低成本。这使得AI部署更加便捷和经济实惠。 超高速推理:Gemma 2经过优化,能够在各种硬件上以惊人的速度运行,无论是强大的游戏笔记本、高端台式机,还是基于云的设置。使用者可以在Google AI Studio上尝试全精度运行Gemma 2,也可以在CPU上使用Gemma.cpp的量化版本解锁本地性能,或者通过Hugging Face Transformers在家用电脑上使用NVIDIA RTX或GeForce RTX进行尝试。

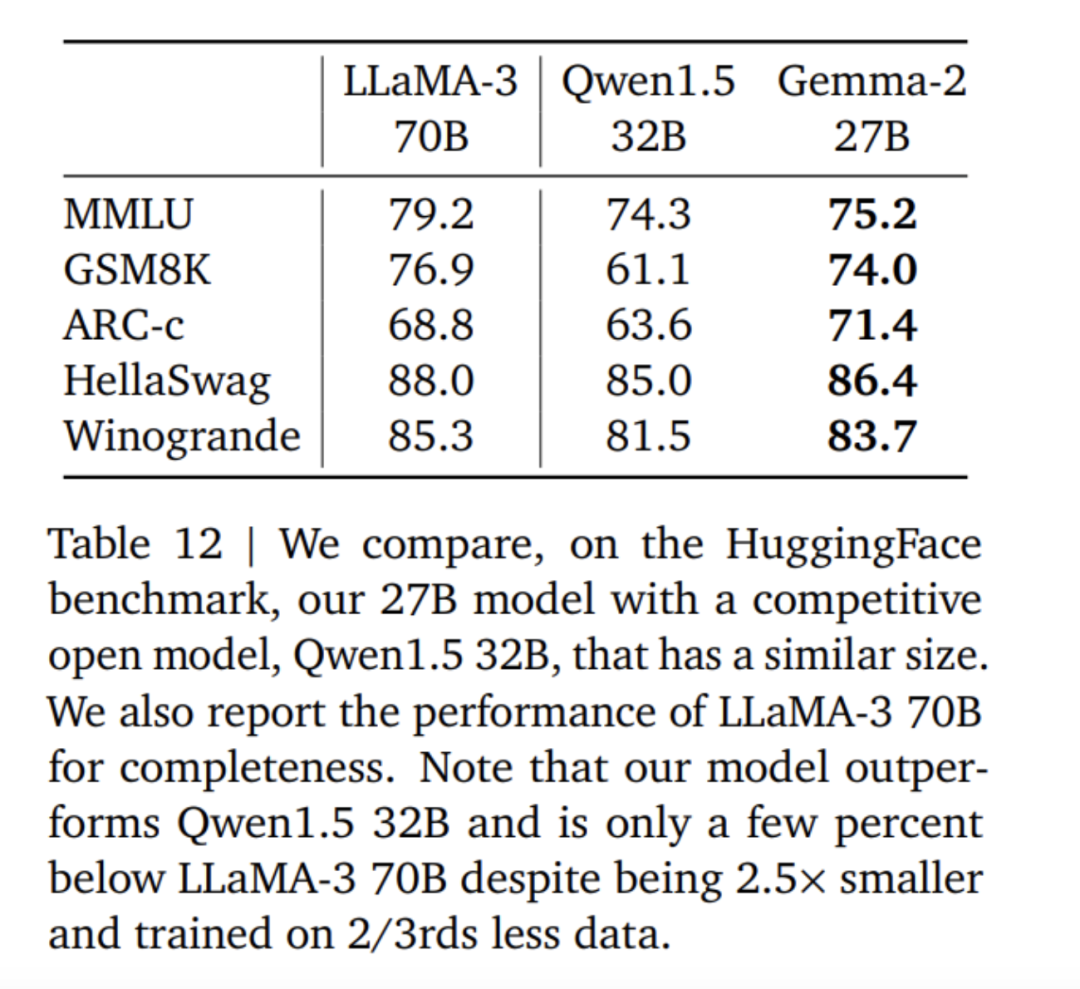
以上是 Gemma2 与 Llama3、Grok-1 的得分数据对比。
其实从各项得分数据来看,此次开源的 9B 大模型优势不是特别明显。近1个月前智谱AI 开源的国产大模型 GLM-4-9B 更具有优势。

开放且易于访问:与原始Gemma模型一样,Gemma 2允许开发者和研究人员共享和商业化创新成果。 广泛的框架兼容性:Gemma 2兼容主要的AI框架,如Hugging Face Transformers,以及通过Keras 3.0、vLLM、Gemma.cpp、Llama.cpp和Ollama原生支持的JAX、PyTorch和TensorFlow,使其能够轻松与用户偏好的工具和工作流程结合。此外,Gemma已通过NVIDIA TensorRT-LLM优化,可以在NVIDIA加速的基础设施上运行,或作为NVIDIA NIM推理微服务运行,未来还将优化NVIDIA的NeMo,并且可以使用Keras和Hugging Face进行微调。除此之外,谷歌正在积极升级微调能力。 轻松部署:从下个月开始,Google Cloud客户将能够在Vertex AI上轻松部署和管理Gemma 2。
在最新的博客中,谷歌宣布向所有开发者开放了Gemini 1.5 Pro的200万token上下文窗口访问权限。但是,随着上下文窗口的增加,输入成本也可能增加。为了帮助开发者减少使用相同token的多prompt任务成本,谷歌贴心地在Gemini API中为Gemini 1.5 Pro和1.5 Flash推出了上下文缓存功能。 为解决大型语言模型在处理数学或数据推理时需要生成和执行代码来提高准确性,谷歌在Gemini 1.5 Pro和1.5 Flash中启用了代码执行功能。开启后,模型可以动态生成并运行Python代码,并从结果中迭代学习,直到达到所需的最终输出。执行沙盒不连接互联网,并标配一些数值库,开发者只需根据模型的输出token进行计费。这是谷歌在模型功能中首次引入代码执行的步骤,今天即可通过Gemini API和Google AI Studio中的「高级设置」使用。 谷歌希望让所有开发者都能接触到AI,无论是通过API密钥集成Gemini模型,还是使用开放模型Gemma 2。为了帮助开发者动手操作Gemma 2模型,谷歌团队将在Google AI Studio中提供其用于实验。

论文地址:https://storage.googleapis.com/deepmind-media/gemma/gemma-2-report.pdf 博客地址:https://blog.google/technology/developers/google-gemma-2/

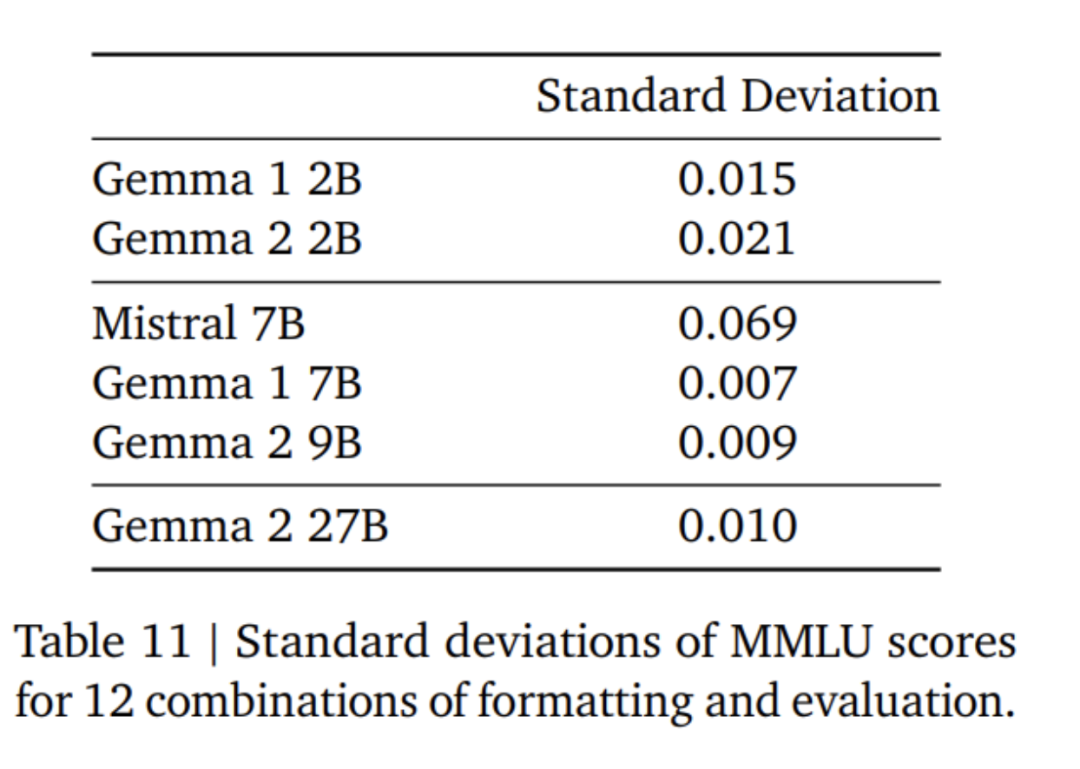
局部滑动窗口和全局注意力。研究团队在每隔一层中交替使用局部滑动窗口注意力和全局注意力。局部注意力层的滑动窗口大小设置为4096个token,而全局注意力层的跨度设置为8192个token。 Logit软封顶。根据Gemini 1.5的方法,研究团队在每个注意力层和最终层限制logit,使得logit的值保持在−soft_cap和+soft_cap之间。 对于9B和27B模型,研究团队将注意力对数封顶设置为50.0,最终对数封顶设置为30.0。截至本文发表时,注意力logit软封顶与常见的FlashAttention实现不兼容,因此他们已从使用FlashAttention的库中移除了此功能。研究团队对模型生成进行了有无注意力logit软封顶的消融实验,发现大多数预训练和后期评估中,生成质量几乎不受影响。本文中的所有评估均使用包含注意力logit软封顶的完整模型架构。然而,某些下游性能可能仍会受到此移除的轻微影响。 使用RMSNorm进行post-norm 和pre-norm。为了稳定训练,研究团队使用RMSNorm对每个变换子层、注意力层和前馈层的输入和输出进行归一化。 分组查询注意力。27B和9B模型均使用GQA,num_groups = 2,基于消融实验表明在保持下游性能的同时提高了推理速度。

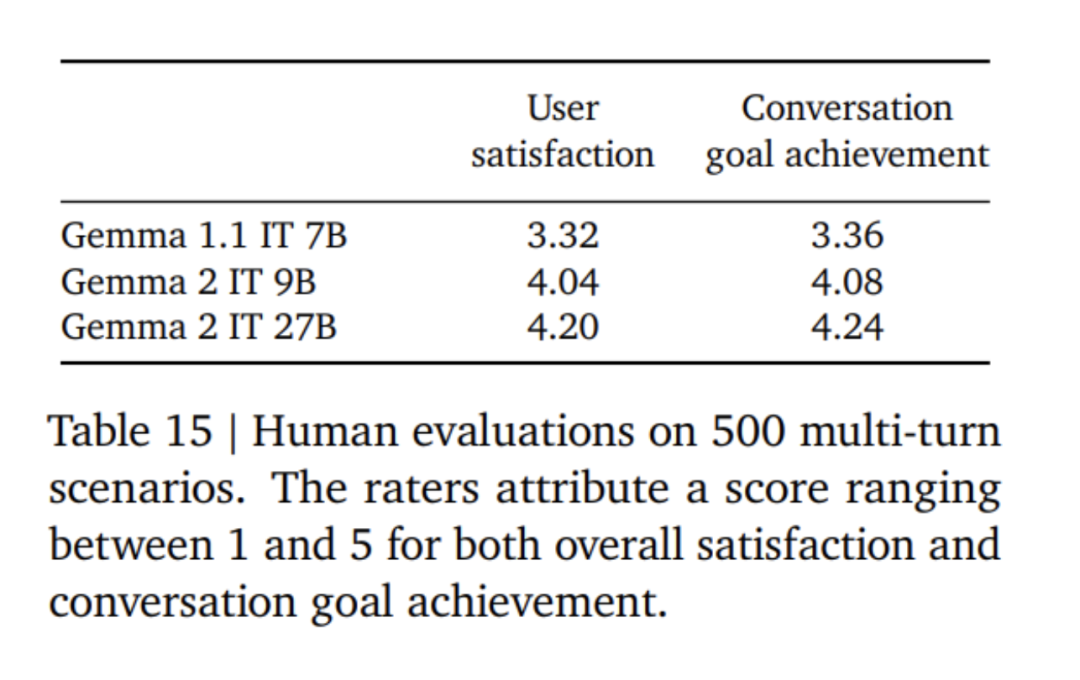
首先,在混合的纯文本、纯英文合成和人工生成的prompt-响应对上应用监督微调(SFT)。 然后,在这些模型上应用基于奖励模型(RLHF)的强化学习,奖励模型训练基于token的纯英文偏好数据,策略则与SFT阶段使用相同的prompt。 最后,通过平均每个阶段获得的模型以提高整体性能。最终的数据混合和训练后方法,包括调优的超参数,都是基于在提高模型有用性的同时最小化与安全性和幻觉相关的模型危害来选择的。





以上是谷歌「诚意之作」,开源9B、27B版Gemma2,主打高效、经济!的详细内容。更多信息请关注PHP中文网其他相关文章!
声明:
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系admin@php.cn