


当前的多模态和多任务基础模型,如 **4M** 或 **UnifiedIO**,显示出有希望的结果。然而,它们接受不同输入和执行不同任务的开箱即用能力,受到它们接受训练的模态和任务的数量(通常很少)的限制。
,基于此,来自洛桑联邦理工学院(EPFL)和苹果的研究者联合开发了一个**先进的**任意到任意模态单一模型,该模型在数十种**广泛**多样化的模态上进行训练,并对大规模多模态数据集和文本语料库进行协同训练。
训练过程中一个关键步骤是对各种模态执行离散 **tokenization**,无论它们是类似图像的神经网络 **feature map**、向量、实例分割或人体姿态等结构化数据,还是可以表征为文本的数据。

论文地址:https://arxiv.org/pdf/2406.09406
论文主页 https://4m.epfl.ch/
论文标题:4M-21: An Any-to-Any Vision Model for Tens of Tasks and Modalities
该研究展示了训练单一模型,也能完成现有模型至少**三倍**多的任务 / **模态**,并且不会损失性能。此外,该研究还实现了更细粒度和更可控的多**模态**生成能力。
该研究建立在多模态掩码预训练方案的基础上,并通过在数十种高度多样化的模态上进行训练来提升**模型**能力。通过使用特定于模态的离散分词器对其进行编码,该研究实现了在不同模态上训练单个统一**模型**。
简单来说,该研究在几个关键维度上扩展了现有模型的功能:
模态:从现有最佳任意到任意模型的 7 种模态增加到 21 种不同模态,从而实现跨模态检索、可控生成和强大的开箱即用性能。这是第一次单个视觉模型可以以任意到任意的方式解决数十个不同的任务,而不会损害性能,并且没有任何传统的多任务学习。
多样性:添加对更多结构化数据的支持,例如人体姿态、SAM 实例、元数据等等。
tokenization:使用特定于模态的方法研究不同模态的离散 tokenization,例如全局图像嵌入、人体姿态和语义实例。
扩展:将模型大小扩展至 3B 参数,将数据集扩展至 0.5B 样本。
协同训练:同时在视觉和语言上协同训练。
方法介绍
该研究采用 4M 预训练方案(该研究同样来自 EPFL 和苹果,在去年发布),其被证明是一种通用方法,可以有效扩展到多模态。
具体而言,本文保持架构和多模态掩码训练目标不变,通过扩大模型和数据集的规模、增加训练模型所涉及的模态类型和数量,并且在多个数据集上进行联合训练,可以提升模型的性能和适应性。
模态分为以下几大类别:RGB、几何、语义、边缘、特征图、元数据和文本,如下图所示。
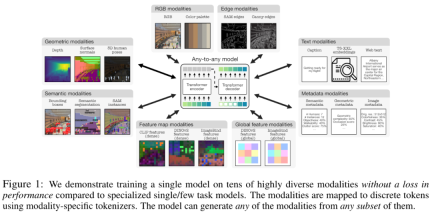
Tokenization
Tokenization 主要包括将不同模态和任务转换为序列或离散 token,从而统一它们的表示空间。研究者使用不同的 tokenization 方法来离散具有不同特征的模态,如图 3 所示。总而言之,本文采用了三种 tokenizer,包括 ViT tokenizer、MLP tokenizer 以及文本 tokenizer。
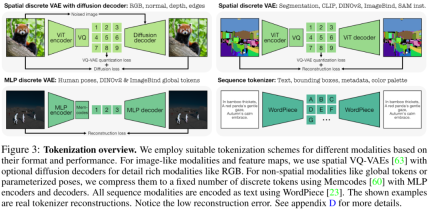
在架构选择上,本文采用基于 Transformer 的 4M 编码器 - 解码器架构,并添加额外的模态嵌入以适应新模态。
实验结果
接下来,论文展示了 4M-21 多模态能力。
多模态生成
基于迭代解码 token ,4M-21 可以用来预测任意训练模态。如图 2 所示,本文可以从给定的输入模态以一致的方式生成所有模态。
此外,由于该研究可以有条件和无条件地从其他模态的任何子集生成任何训练模态,因此它支持几种方法来执行细粒度和多模态生成,如图 4 所示,例如执行多模态编辑。此外,4M-21 表现出改进的文本理解能力,无论是在 T5-XXL 嵌入上还是在常规字幕上,都可以实现几何和语义上合理的生成(图 4,右上)。

多模态检索
如图 5 所示,4M-21 解锁了原始 DINOv2 和 ImageBind 模型无法实现的检索功能,例如通过使用其他模态作为查询来检索 RGB 图像或其他模态。此外,4M-21 还可以组合多种模态来预测全局嵌入,从而更好地控制检索,如右图所示。

开箱即用
4M-21 能够开箱即用地执行一系列常见的视觉任务,如图 6 所示。
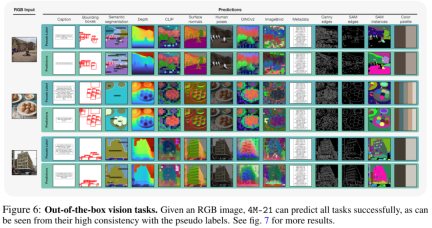
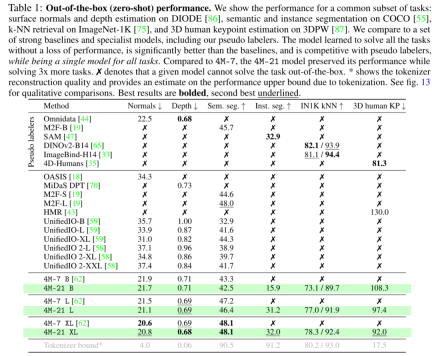
表 1 评估了 DIODE 表面法线和深度估计、COCO 语义和实例分割、3DPW 3D 人体姿态估计等。
迁移实验
此外,本文还训练了三种不同尺寸的模型:B、L 和 XL。然后,将其编码器迁移到下游任务,并在单模态 (RGB) 和多模态 (RGB + 深度) 设置上进行评估。所有迁移实验均丢弃解码器,而是训练特定任务的头部。结果如表 2 所示:
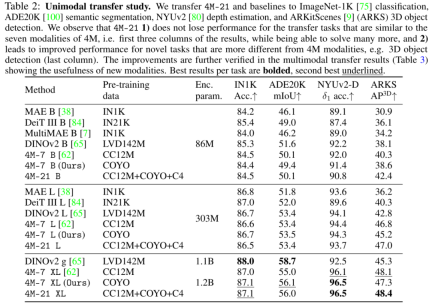
最后,本文在 NYUv2、Hypersim 语义分割和 ARKitScenes 上的 3D 对象检测上执行多模态传输。如表 3 所示,4M-21 充分利用了可选的深度输入,并显著改进了基线。

以上是太全了!苹果上新视觉模型4M-21,搞定21种模态的详细内容。更多信息请关注PHP中文网其他相关文章!

 阅读AI索引2025:AI是您的朋友,敌人还是副驾驶?Apr 11, 2025 pm 12:13 PM
阅读AI索引2025:AI是您的朋友,敌人还是副驾驶?Apr 11, 2025 pm 12:13 PM斯坦福大学以人为本人工智能研究所发布的《2025年人工智能指数报告》对正在进行的人工智能革命进行了很好的概述。让我们用四个简单的概念来解读它:认知(了解正在发生的事情)、欣赏(看到好处)、接纳(面对挑战)和责任(弄清我们的责任)。 认知:人工智能无处不在,并且发展迅速 我们需要敏锐地意识到人工智能发展和传播的速度有多快。人工智能系统正在不断改进,在数学和复杂思维测试中取得了优异的成绩,而就在一年前,它们还在这些测试中惨败。想象一下,人工智能解决复杂的编码问题或研究生水平的科学问题——自2023年
 开始使用Meta Llama 3.2 -Analytics VidhyaApr 11, 2025 pm 12:04 PM
开始使用Meta Llama 3.2 -Analytics VidhyaApr 11, 2025 pm 12:04 PMMeta的Llama 3.2:多模式和移动AI的飞跃 Meta最近公布了Llama 3.2,这是AI的重大进步,具有强大的视觉功能和针对移动设备优化的轻量级文本模型。 以成功为基础
 AV字节:Meta' llama 3.2,Google的双子座1.5等Apr 11, 2025 pm 12:01 PM
AV字节:Meta' llama 3.2,Google的双子座1.5等Apr 11, 2025 pm 12:01 PM本周的AI景观:进步,道德考虑和监管辩论的旋风。 OpenAI,Google,Meta和Microsoft等主要参与者已经释放了一系列更新,从开创性的新车型到LE的关键转变
 与机器交谈的人类成本:聊天机器人真的可以在乎吗?Apr 11, 2025 pm 12:00 PM
与机器交谈的人类成本:聊天机器人真的可以在乎吗?Apr 11, 2025 pm 12:00 PM连接的舒适幻想:我们在与AI的关系中真的在蓬勃发展吗? 这个问题挑战了麻省理工学院媒体实验室“用AI(AHA)”研讨会的乐观语气。事件展示了加油
 了解Python的Scipy图书馆Apr 11, 2025 am 11:57 AM
了解Python的Scipy图书馆Apr 11, 2025 am 11:57 AM介绍 想象一下,您是科学家或工程师解决复杂问题 - 微分方程,优化挑战或傅立叶分析。 Python的易用性和图形功能很有吸引力,但是这些任务需要强大的工具
 3种运行Llama 3.2的方法-Analytics VidhyaApr 11, 2025 am 11:56 AM
3种运行Llama 3.2的方法-Analytics VidhyaApr 11, 2025 am 11:56 AMMeta's Llama 3.2:多式联运AI强力 Meta的最新多模式模型Llama 3.2代表了AI的重大进步,具有增强的语言理解力,提高的准确性和出色的文本生成能力。 它的能力t
 使用dagster自动化数据质量检查Apr 11, 2025 am 11:44 AM
使用dagster自动化数据质量检查Apr 11, 2025 am 11:44 AM数据质量保证:与Dagster自动检查和良好期望 保持高数据质量对于数据驱动的业务至关重要。 随着数据量和源的增加,手动质量控制变得效率低下,容易出现错误。
 大型机在人工智能时代有角色吗?Apr 11, 2025 am 11:42 AM
大型机在人工智能时代有角色吗?Apr 11, 2025 am 11:42 AM大型机:AI革命的无名英雄 虽然服务器在通用应用程序上表现出色并处理多个客户端,但大型机是专为关键任务任务而建立的。 这些功能强大的系统经常在Heavil中找到


热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

EditPlus 中文破解版
体积小,语法高亮,不支持代码提示功能

记事本++7.3.1
好用且免费的代码编辑器

SecLists
SecLists是最终安全测试人员的伙伴。它是一个包含各种类型列表的集合,这些列表在安全评估过程中经常使用,都在一个地方。SecLists通过方便地提供安全测试人员可能需要的所有列表,帮助提高安全测试的效率和生产力。列表类型包括用户名、密码、URL、模糊测试有效载荷、敏感数据模式、Web shell等等。测试人员只需将此存储库拉到新的测试机上,他就可以访问到所需的每种类型的列表。

MinGW - 适用于 Windows 的极简 GNU
这个项目正在迁移到osdn.net/projects/mingw的过程中,你可以继续在那里关注我们。MinGW:GNU编译器集合(GCC)的本地Windows移植版本,可自由分发的导入库和用于构建本地Windows应用程序的头文件;包括对MSVC运行时的扩展,以支持C99功能。MinGW的所有软件都可以在64位Windows平台上运行。

ZendStudio 13.5.1 Mac
功能强大的PHP集成开发环境

