
如何在本地下载并安装 Llama 2

- WBOY原创
- 2024-06-14 20:33:401013浏览
考虑到这一点,我们创建了一个分步指南,介绍如何使用 Text-Generation-WebUI 在计算机上本地加载量化的 Llama 2 LLM。
为什么在本地安装 Llama 2
人们选择直接运行 Llama 2 的原因有很多。有些是出于隐私考虑,有些是为了定制,还有一些是为了离线功能。如果您正在为您的项目研究、微调或集成 Llama 2,那么通过 API 访问 Llama 2 可能不适合您。在PC上本地运行LLM的目的是减少对第三方AI工具的依赖,并随时随地使用AI,而不必担心将潜在的敏感数据泄露给公司和其他组织。
话虽如此,让我们从本地安装 Llama 2 的分步指南开始。
步骤 1:安装 Visual Studio 2019 构建工具
为了简化操作,我们将使用 Text-Generation-WebUI 的一键安装程序(用于通过 GUI 加载 Llama 2 的程序) 。但是,要使此安装程序正常工作,您需要下载 Visual Studio 2019 构建工具并安装必要的资源。
下载:Visual Studio 2019(免费)
继续下载该软件的社区版。 现在安装 Visual Studio 2019,然后打开该软件。打开后,勾选“使用 C++ 进行桌面开发”复选框并点击安装。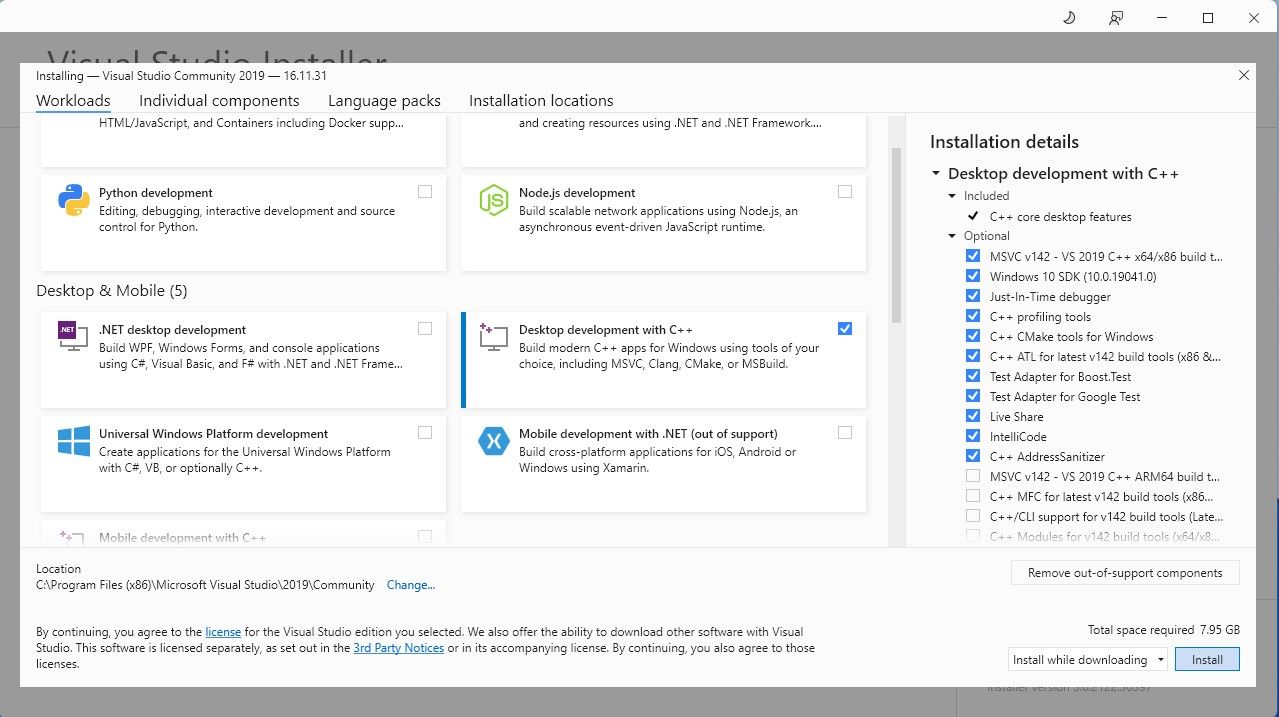
现在您已经安装了使用 C++ 进行的桌面开发,是时候下载 Text-Generation-WebUI 一键安装程序了。
步骤 2:安装 Text-Generation-WebUI
Text-Generation-WebUI 一键安装程序是一个脚本,它会自动创建所需的文件夹并设置 Conda 环境和所有必要的要求运行人工智能模型。
要安装脚本,请单击“代码”>“下载一键安装程序”下载 ZIP。
下载:Text-Generation-WebUI 安装程序(免费)
下载后,将 ZIP 文件解压到您的首选位置,然后打开解压的文件夹。 在该文件夹中,向下滚动并查找适合您的操作系统的启动程序。通过双击相应的脚本来运行程序。如果您使用的是 Windows,则对于 MacOS 选择 start_windows 批处理文件,对于 Linux 选择 start_macos shell script,对于 Linux 选择 start_linux shell script。
您的防病毒软件可能会发出警报;这可以。该提示只是运行批处理文件或脚本的防病毒误报。仍然单击“运行”。 终端将打开并开始设置。早些时候,安装程序将暂停并询问您正在使用什么 GPU。选择计算机上安装的适当类型的 GPU,然后按 Enter 键。对于没有专用显卡的,选择无(我想在CPU模式下运行模型)。请记住,与使用专用 GPU 运行模型相比,在 CPU 模式下运行要慢得多。
 设置完成后,您现在可以在本地启动 Text-Generation-WebUI。您可以通过打开您喜欢的 Web 浏览器并在 URL 上输入提供的 IP 地址来完成此操作。
设置完成后,您现在可以在本地启动 Text-Generation-WebUI。您可以通过打开您喜欢的 Web 浏览器并在 URL 上输入提供的 IP 地址来完成此操作。 WebUI 现已可供使用。
WebUI 现已可供使用。
但是,该程序只是一个模型加载器。让我们下载 Llama 2 以启动模型加载器。
步骤 3:下载 Llama 2 模型
在决定您需要哪一个 Llama 2 版本时,需要考虑很多事情。其中包括参数、量化、硬件优化、大小和用法。所有这些信息都可以在模型名称中找到。
参数:用于训练模型的参数数量。更大的参数可以产生更强大的模型,但会牺牲性能。用法:可以是标准的,也可以是聊天的。聊天模型经过优化可用作 ChatGPT 等聊天机器人,而标准模型是默认模型。硬件优化:指什么硬件最能运行模型。 GPTQ 意味着模型针对在专用 GPU 上运行进行了优化,而 GGML 则针对在 CPU 上运行进行了优化。量化:表示模型中权重和激活的精度。对于推理,q4 的精度是最佳的。尺寸:指具体型号的尺寸。请注意,某些模型的排列方式可能不同,甚至可能不显示相同类型的信息。然而,这种类型的命名约定在 HuggingFace 模型库中相当常见,因此仍然值得理解。

在此示例中,模型可以被识别为中型 Llama 2 模型,该模型使用专用 CPU 针对聊天推理进行了优化,并使用 130 亿个参数进行训练。
对于在专用 GPU 上运行的,选择 GPTQ 模型,而对于使用 CPU 的,选择 GGML。如果您想像使用 ChatGPT 一样与模型聊天,请选择聊天,但如果您想试验模型的全部功能,请使用标准模型。至于参数,要知道使用更大的模型会以牺牲性能为代价提供更好的结果。我个人建议您从 7B 型号开始。至于量化,请使用 q4,因为它仅用于推理。
下载:GGML(免费)
下载:GPTQ(免费)
既然您知道您需要哪一版本的 Llama 2,请继续下载您想要的模型。
就我而言,由于我在超级本上运行此程序,因此我将使用针对聊天进行微调的 GGML 模型 llama-2-7b-chat-ggmlv3.q4_K_S.bin。
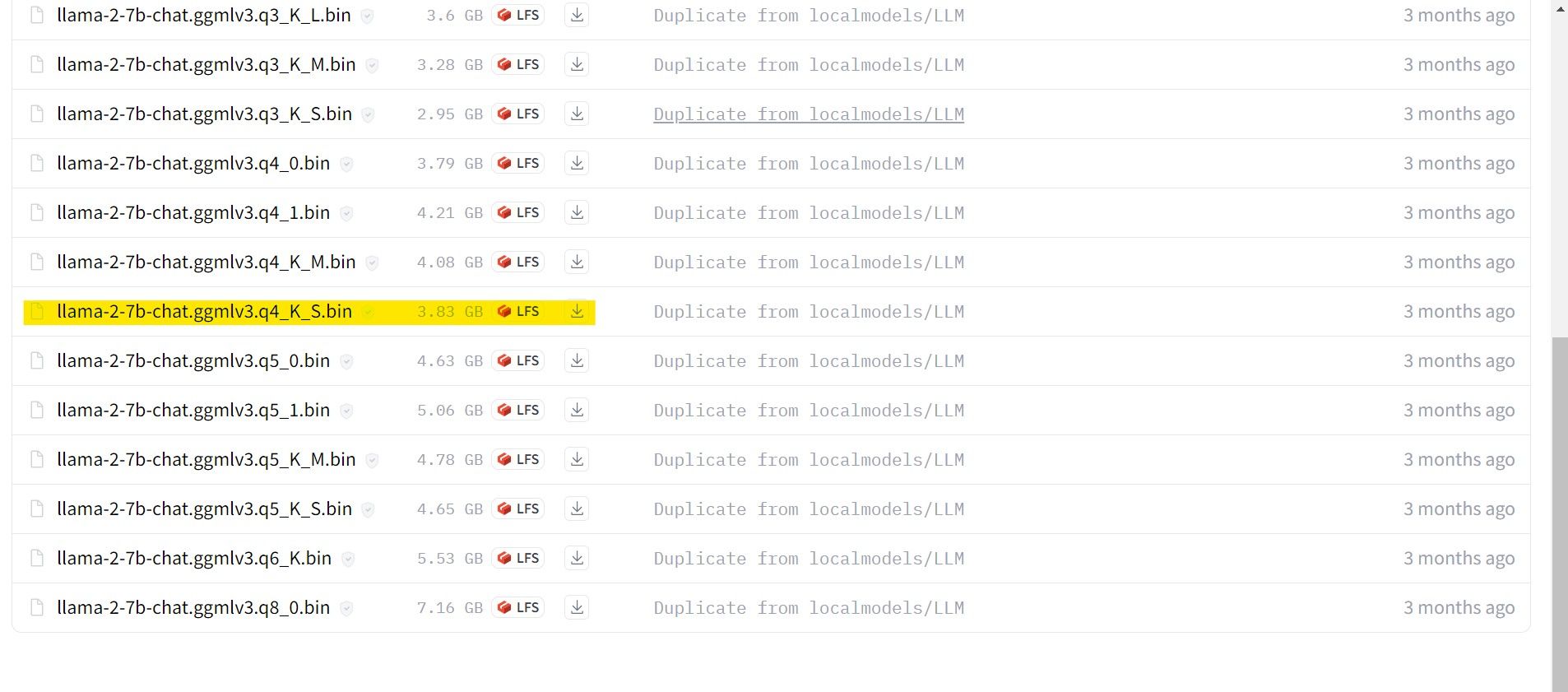
下载完成后,将模型放入text- Generation-webui-main >楷模。

现在您已下载模型并将其放置在模型文件夹中,是时候配置模型加载器了。
步骤 4:配置 Text-Generation-WebUI
现在,让我们开始配置阶段。
再次通过运行 start_(您的操作系统)文件打开 Text-Generation-WebUI(请参阅上面的步骤)。 在 GUI 上方的选项卡上,单击模型。单击模型下拉菜单中的刷新按钮并选择您的模型。 现在单击模型加载器的下拉菜单,并为使用 GTPQ 模型的用户选择 AutoGPTQ,为使用 GGML 模型的用户选择 ctransformers。最后,单击“加载”以加载您的模型。 要使用该模型,请打开“聊天”选项卡并开始测试该模型。
要使用该模型,请打开“聊天”选项卡并开始测试该模型。
恭喜您,您已在本地计算机上成功加载 Llama2!
尝试其他 LLM
既然您已经知道如何使用 Text-Generation-WebUI 直接在计算机上运行 Llama 2,那么除了 Llama 之外,您还应该能够运行其他 Llama。只需记住模型的命名约定,并且只有模型的量化版本(通常是 q4 精度)才能加载到常规 PC 上。 HuggingFace 上提供了许多量化的法学硕士。如果您想探索其他模型,请在 HuggingFace 的模型库中搜索 TheBloke,您应该会找到许多可用的模型。
以上是如何在本地下载并安装 Llama 2的详细内容。更多信息请关注PHP中文网其他相关文章!