
利用 NVIDIA Riva 快速部署企业级中文语音 AI 服务并进行优化加速

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB原创
- 2024-06-10 21:57:481158浏览
一、Riva 概览
1. Overview

Riva是NVIDIA推出的一款SDK,用于实时的Speech AI服务。它是一个高度可定制的工具,并且使用GPU进行加速。NGC上提供了很多预训练好的模型,这些模型开箱即用,可以直接使用Riva提供的ASR和TTS解决方案进行部署。
为了满足特定领域的需求或者进行定制化功能的开发,用户也可以使用 NeMo 对这些模型进行重新训练或微调。从而进一步提升模型的性能,使其更加适应用户的需求。
Riva+Skills是一种高度可定制化的工具,它利用GPU加速实时流式的语音识别和语音合成,并且能够同时处理成千上万个并发请求。它支持多种部署平台,包括本地、云端和端侧。
2. Riva ASR

在语音识别方面,Riva使用了准确度很高的 SOTA 模型,比如 Citrinet、Conformer 和 NeMo 自研的 FastConformer 等。目前,Riva 支持超过10种单语言模型,并且还支持多语种的语音识别,包括英语-西班牙语、英语-中文和英语-日语等多语言语音识别。
通通过定制化的功能,可以进一步提升模型的准确率。例如,针对特定行业术语、口音或方言的支持,以及对噪声环境的定制化处理,都可以帮助提高语音识别的性能。
Riva的整体框架能够适用于多种场景,例如客服和会议系统等。除了通用场景外,Riva的服务还可以根据不同行业的需求进行定制化,比如CSP、教育、金融等行业。
3. ASR Pipeline & Customization
在 Riva ASR 的整个流程中,有一些可定制化的模块,这些模块可以按照难度分为三类。

首先,橙色框中是在 inference 过程中,在客户端即可做的定制化。比如支持热词功能,通过在 inference 过程中添加产品名称或专有名词,使语音模型能够更准确地识别这些特定的词汇。这一功能是 Riva 本身就支持的,在不重新训练模型或重新启动 Riva 服务器的情况下即可完成定制化。
紫色框中是部署时可以进行的一些定制化。例如,在 Riva 的流式识别中,提供了延迟优化或吞吐优化两种模式,可以根据业务需求进行选择,以获得更好的性能表现。此外,在部署过程中,还可以进行发音词典的定制化。通过定制化发音词典,可以确保特定术语、名称或行业术语的正确发音,并提高语音识别的准确性。
绿色框中是训练过程中可以进行的定制化,即在服务器端进行的训练和调整。比如在训练开始的文本正则化阶段,可以加入一些对特定文本的处理。另外,可以微调或重新训练声学模型,以解决特定业务场景下的诸如口音、噪声等问题,使模型更加鲁棒。还可以重新训练语言模型、微调标点模型、逆文本正则化等。
以上就是 Riva 可以定制化的部分。
4. Riva TTS

Riva TTS 流程如上图中右侧所示,它包含以下几个模块:
- 第一步是文本正则化。
- 第二步是 G2P,将文本的基本单位转换为发音或口语的基本单位。例如,将单词转换为音素。
- 第三步是频谱合成,将文本转换为声学频谱。
- 第四步是音频合成,也称为 vocoder。在这一步中,将前一步得到的频谱转换为音频。
上图中,以合成"Hello World"这句话为例,首先进入文本正则化模块,对文本进行标准化处理,例如将大小写规范化。接着进入 G2P 模块,将文本转换为音素序列。之后进入频谱合成模块,通过神经网络训练,得到频谱。最后进入 vocoder,将频谱转换为最终的声音。
Riva 提供流式 TTS 支持,使用了目前流行的 FastPitch 和 HiFi-GAN 模型的组合。目前支持多种语言,包括英语、中文普通话、西班牙语、意大利语和德语等。
5. TTS Pipeline & Customization
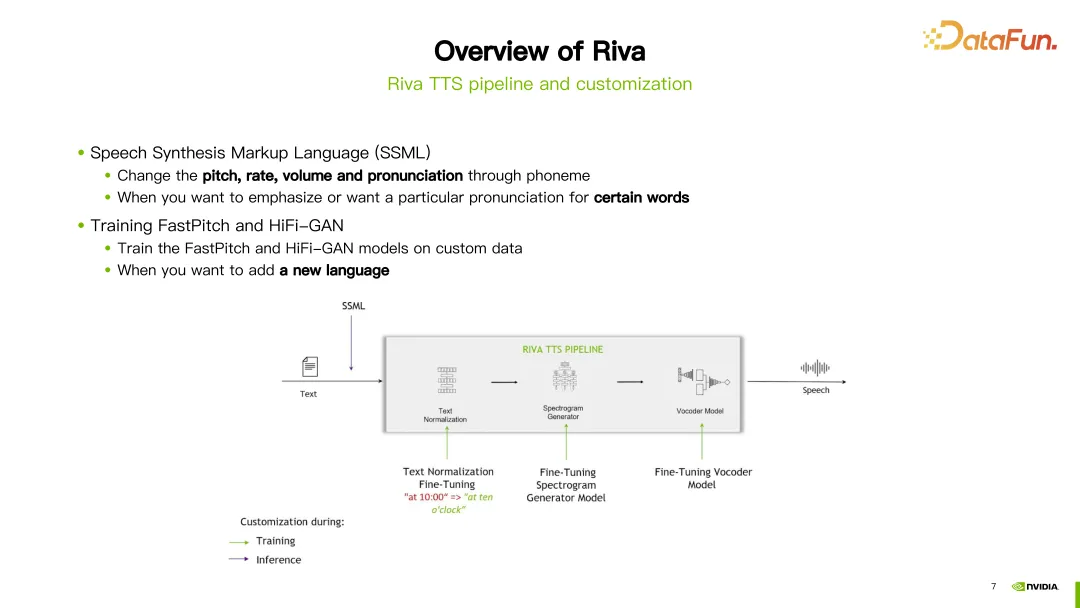
在 Riva 的 TTS 流程中,为定制化提供了两种方式。第一种方式是使用语音合成标记语言(SSML),这是一种比较容易的定制化方式。通过一些配置,可以调整发音的音调、语速、音量等。通常情况下,如果想改变特定词的发音,会选择这种方式。
另一种方式是进行微调或重新训练 FastPitch 或 HiFi-GAN 模型。可以使用自己的特定数据对这两个模型进行微调或重新训练。
二、中文语音识别模型的最新更新
1. Overview

在过去的一年中,Riva 对中文模型进行了一些更新和改进。接下来介绍其中一些重要的更新。
首先,持续优化中文语音识别(ASR)模型。可以在相应的链接中找到最新的 ASR 模型。
其次,引入了统一模型(Unified Model)的支持。这意味着在一次推理中,可以同时做语音识别标点符号预测。
第三,增加了中英文混合模型的支持。这意味着模型可以同时处理中文和英文的语音输入。
此外,还引入了一些新的模块和功能支持。包括基于神经网络的语音活动检测(VAD)和说话人日志(Speaker Diarization)模块。还引入了中文逆文本正则化的功能。这些模型的详细信息都可以在相应的链接中找到。
2. Word Boosting
除此之外,我们还为中文提供了详细的教程。第一部分是关于热词(Word Boosting)的教程。

热词是通过在识别时候对特定的词语的权重做调整,从而使得这个词语识别得更准。在教程中,展示了一个中文模型使用热词的示例,如"望岳",这是一首古诗的名字,我们为这个词赋予了一个分数为 20 的权重。接着,使用 Riva 提供的 add_word_boosting_to_config 方法,将我们希望添加的词汇及其分数配置到客户端中。然后,将配置好的请求发送给 ASR 服务器,就可以获得加入热词后的识别结果。
在配置热词时,需要设置两个参数:boosted_lm_words 和boosted_lm_score。boosted_lm_words 是我们希望提高识别准确度的词汇列表。而 boosted_lm_score 则是为这些词汇设置的分数,通常在 20 到 100 之间。

除了前面的基本配置,Riva 的热词功能还支持一些高级用法。例如,可以同时提升多个词汇的权重。比如,在例子中我们给"五 G"和"四 G"这两个词汇,分别设置了权重 20 和 30。
此外,我们还可以使用 word boosting 来降低某些词汇的准确度,即给它们分配负的权重,从而降低其出现的概率。例如,在例子中,我们给出了一个汉字"她",它的分数设置为 -100。这样,模型就会倾向于不识别出这个汉字。理论上,我们可以设置任意数量的热词,不会对延迟造成影响。另外值得注意的是,boosting 的过程是在客户端实现的,对服务器端没有影响。
3. Finetuning Conformer AM
第二个教程,是关于如何微调 Conformer 声学模型。

微调 ASR 使用的是 NeMo 工具。配置好 NGC 账户后,就可以使用"NGC download"命令直接下载 Riva 所提供的预训练好的中文模型。在这个例子中,下载了第五个版本的中文 ASR 模型。下载完成后,需要加载预训练模型。
首先,需要导入一些包。参数 model path 设置为刚刚下载好的模型的路径。接下来,使用 NeMo 提供的 ASRModel.restore_from 函数获取模型的配置文件,通过 target 这个参数可以获取原始 ASR 模型的类别。接着,使用 import_class_by_path 函数获取实际的模型类别。最后,使用该类别下模型的 restore_from 方法来加载指定路径下的 ASR 模型参数。

加载了模型后,就可以使用 NeMo 提供的训练脚本来进行微调。在这个例子中,我们以训练 CTC 模型为例,使用的脚本是 speech_to_text_ctc.py。需要配置的一些参数包括 train_ds.manifest_filepath,即训练数据的 JSON 文件路径,还有是否使用 GPU、优化器以及最大迭代轮数等。
在训练完模型之后,可以进行评估。评估时需要注意将 use_cer 参数设置为true,因为对于中文,我们使用字符错误率(Character Error Rate)作为指标。完成了模型的训练和评估之后,可以使用 nemo2riva 命令将 NeMo 模型转换为 Riva 模型。然后使用 Riva 的 Quickstart 工具来部署模型。
三、Riva TTS(Text-to-Speech)服务
接下来介绍 Riva TTS 服务。
1. Demo
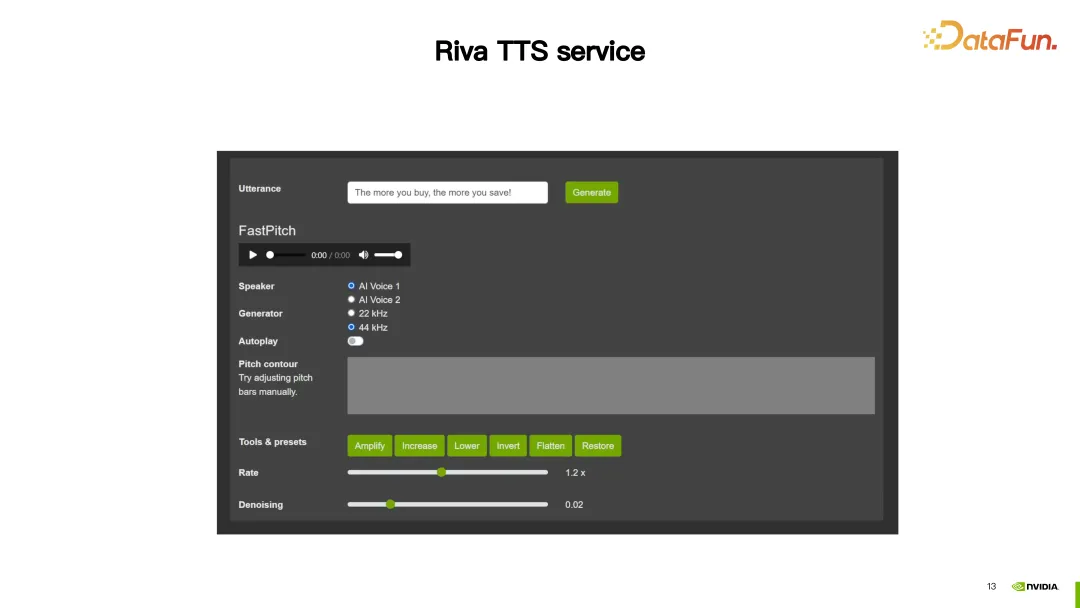
在这一演示中,Riva TTS 提供的自定义功能,使合成出的语音更加自然。
接下来将介绍 Riva TTS 提供的两种定制化方式。
2. SSML

首先是前面提到的 SSML(Speech Synthesis Markup Language),它通过一个脚本来进行配置。通过 SSML,可以调整 TTS 中的韵律,包括音高(pitch)和语速(rate),另外还可以调整音量。
如上图所示,对第一句话“Today is a sunny day“,将其韵律的 pitch 改成了 2.5。对第二句话,做了两个配置,一个是将它的 rate 设成 high,另外一个将音量加 1DB。这样就可以获得一个定制化的结果。
3. TTS Finetuning using NeMo
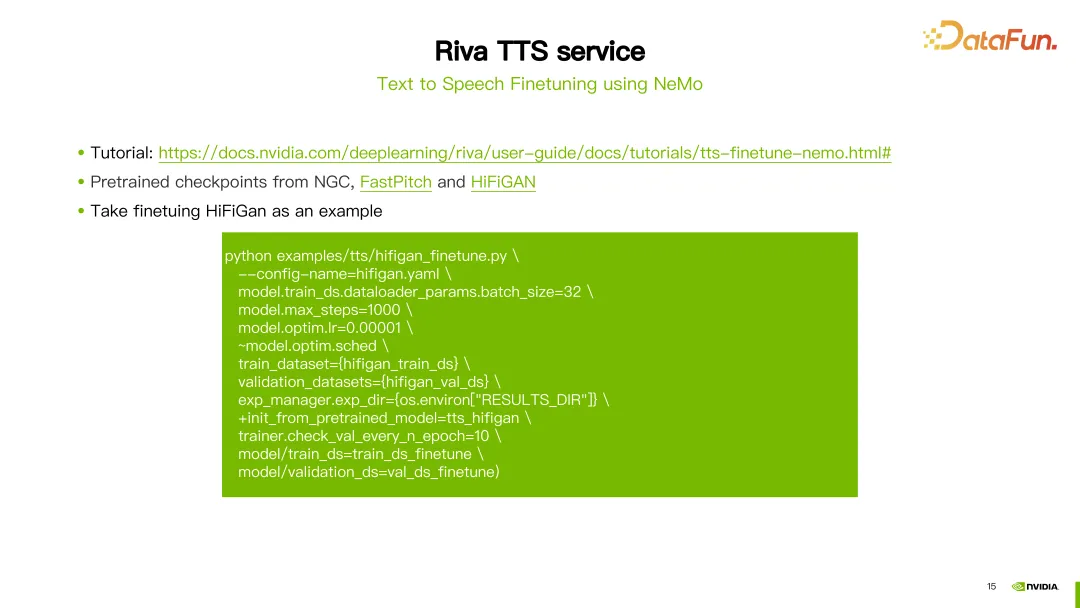
除了 SSML 之外,还可以使用 NeMo 工具微调或重新训练 Riva TTS 的FastPitch 或 HiFi-GAN 模型。
Riva 提供了相关教程,在 NGC 上也提供了一些预训练模型(参见上图中的链接)。
图中举了一个微调 HiFi-GAN 模型的例子。使用 hifigan_finetune.py 命令,并配置模型配置名称、批处理大小、最大迭代步数、学习率等参数。通过设置train_dataset 参数设置微调 HiFi-GAN 所需的数据集路径。如果从 NGC 下载了预训练模型,还可以使用 init_from_pretrained_model 参数来加载预训练模型。这样就可以重新训练 HiFi-GAN 模型。
四、Riva Quickstart 工具
定制化好的模型就可以使用 Quickstart 工具来进行部署。
1. 准备

在开始之前,需要注册一个 NGC 账号,并确保 GPU 支持 Riva,并且已经安装了 Docker 环境。
一旦准备工作完成,即可通过提供的链接下载 Riva Quickstart。如果已经配置好了 NGC CLI,也可以使用 NGC CLI 直接下载 Riva Quickstart。
2. 服务器启停
在下载完成 Riva Quick Start 之后,可以使用其中提供的脚本来进行服务器的初始化、启动和关闭等操作。

以最新版本的 Riva(2.13.1)为例,下载完成后,只需运行 riva_init.sh、riva_start.sh 或 riva_stop.sh 即可完成服务器的初始化、启动和关闭操作。
如果想要使用中文模型,只需将语言代码设置为 zh-CN,工具就会自动下载相应的预训练模型。即可启动服务使用中文的 ASR(自动语音识别)和 TTS(文本转语音)功能。
3. Riva Client

一旦服务器启动成功,即可使用 Riva 提供的脚本 riva_start_client.sh 来调用服务。如果希望进行离线语音识别,只需运行 riva_asr_client 命令并指定要识别的音频文件路径。如果要进行流式语音识别,则可以使用 riva_streaming_asr_client 命令。如果要进行语音合成,可以使用 riva_tts_client 命令,向刚刚启动的服务器发送要处理或合成的音频。
五、参考资源
以下是一些 Riva 相关的文档资源:

Riva 官方文档:这个文档提供了关于 Riva 的详细信息,包括安装、配置和使用指南等。您可以在这里找到 Riva 的官方文档,以便深入了解和学习 Riva 的各个方面。
Riva Quick Start 用户指南:这个指南为用户提供了 Riva Quick Start 的详细说明,包括安装和配置步骤,以及常见问题的解答。如果您在使用 Riva Quick Start 过程中遇到任何问题,您可以在这个用户指南中找到答案。
Riva Release Notes:这个文档提供了关于 Riva 最新模型的更新信息。您可以在这里了解每个版本的更新内容和改进。
以上这些资源将可以为用户更好地理解和使用 Riva 提供帮助。
以上就是本次分享的内容,谢谢大家。
六、问答环节
Q1:Riva 和 Triton 的关系是怎样的?是否有些功能重叠?
A1:对,Riva 使用的是 Nvidia Triton 的inference 框架,是基于 Nvidia Triton 做的一些开发。
Q2:Riva 在 RAG 领域有实际落地吗?或者开源项目?
A2:Riva 目前应该主要还是聚焦在 Speech AI 领域。
Q3:Riva 和 Nemo 有什么关系吗?
A3:Riva 更侧重于部署的解决方案,用 Nemo 训练的模型可以用 Riva 来部署,我们也可以使用 Nemo 来做一些 fine-tuning 和训练的工作,然后 fine-tune 好的模型也可以在 Riva 当中进行部署。
Q4:其他框架训练的模型可以适用吗?
A4:其他框架训练的暂时是不支持的,或者需要一些额外的开发工作。
Q5:Riva 能部署 PyTorch 或 TensorFlow 训练框架的模型吗?
A5:Riva 现在主要支持的是 Nemo 训练出来的模型,Nemo 其实就是基于 PyTorch 做的一些开发。
Q6:如果在 Nemo 里自定义了一个新的模型,需要在 Riva 中写部署代码吗?
A6:对于自研的模型,想在 Riva 里面支持的话,是需要做一些额外的开发的。
Q7:小内存 GPU 能否使用 Riva?
A7:可以参照 Riva 提供的适配平台相关文档,其中有不同型号 GPU 的适配的情况。
Q8:怎么快速地试用 Riva?
A8:可以直接在 NGC 上下载 Riva Quickstart 工具包来试用 Riva。
Q9:如果要支持中文方言,Riva 是不是要做定制化训练?
A9:对的。可以使用自己的一些方言的数据。在 Riva 提供的预训练模型基础上进行微调,再在 Riva 里面部署就可以了。
Q10:Riva 和 Tensor LM 的定位有没有一些重合,或者区别?
A10:Riva 的加速其实也是使用 Tensor RT,Riva 是一个基于 Tensor RT 和 Triton 的产品。
以上是利用 NVIDIA Riva 快速部署企业级中文语音 AI 服务并进行优化加速的详细内容。更多信息请关注PHP中文网其他相关文章!