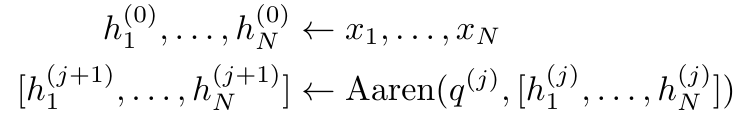序列建模的进展具有极大的影响力,因为它们在广泛的应用中发挥着重要作用,包括强化学习(例如,机器人和自动驾驶)、时间序列分类(例如,金融欺诈检测和医学诊断)等。在过去的几年里,Transformer 的出现标志着序列建模中的一个重大突破,这主要得益于 Transformer 提供了一种能够利用 GPU 并行处理的高性能架构。然而,Transformer 在推理时计算开销很大,主要在于内存和计算需求呈二次扩展,从而限制了其在低资源环境中的应用(例如,移动和嵌入式设备)。尽管可以采用 KV 缓存等技术提高推理效率,但 Transformer 对于低资源领域来说仍然非常昂贵,原因在于:(1)随 token 数量线性增加的内存,以及(2)缓存所有先前的 token 到模型中。在具有长上下文(即大量 token)的环境中,这一问题对 Transformer 推理的影响更大。 为了解决这个问题,加拿大皇家银行 AI 研究所 Borealis AI、蒙特利尔大学的研究者在论文《Attention as an RNN 》中给出了解决方案。值得一提的是,我们发现图灵奖得主 Yoshua Bengio 出现在作者一栏里。
- 论文地址:https://arxiv.org/pdf/2405.13956
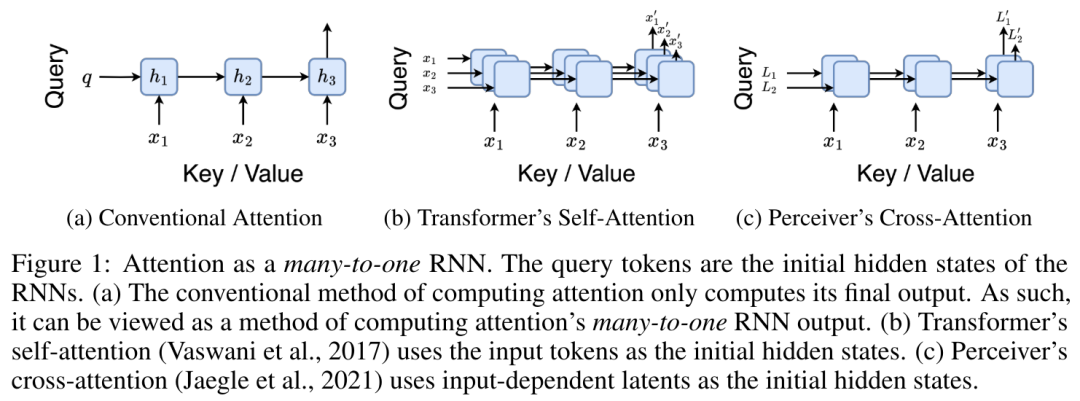
具体而言,研究者首先检查了 Transformer 中的注意力机制,这是导致 Transformer 计算复杂度呈二次增长的组件。该研究表明注意力机制可以被视为一种特殊的循环神经网络(RNN),具有高效计算的多对一(many-to-one)RNN 输出的能力。利用注意力的 RNN 公式,该研究展示了流行的基于注意力的模型(例如 Transformer 和 Perceiver)可以被视为 RNN 变体。然而,与 LSTM、GRU 等传统 RNN 不同,Transformer 和 Perceiver 等流行的注意力模型虽然可以被视为 RNN 变体。但遗憾的是,它们无法高效地使用新 token 进行更新。为了解决这个问题,该研究引入了一种基于并行前缀扫描(prefix scan)算法的新的注意力公式,该公式能够高效地计算注意力的多对多(many-to-many)RNN 输出,从而实现高效的更新。在此新注意力公式的基础上,该研究提出了 Aaren([A] ttention [a] s a [re] current neural [n] etwork),这是一种计算效率很高的模块,不仅可以像 Transformer 一样并行训练,还可以像 RNN 一样高效更新。实验结果表明,Aaren 在 38 个数据集上的表现与 Transformer 相当,这些数据集涵盖了四种常见的序列数据设置:强化学习、事件预测、时间序列分类和时间序列预测任务,同时在时间和内存方面更加高效。 为了解决上述问题,作者提出了一种基于注意力的高效模块,它能够利用 GPU 并行性,同时又能高效更新。首先,作者在第 3.1 节中表明,注意力可被视为一种 RNN,具有高效计算多对一 RNN(图 1a)输出的特殊能力。利用注意力的 RNN 形式,作者进一步说明,基于注意力的流行模型,如 Transformer(图 1b)和 Perceiver(图 1c),可以被视为 RNN。然而,与传统的 RNN 不同的是,这些模型无法根据新 token 有效地更新自身,从而限制了它们在数据以流的形式到达的序列问题中的潜力。为了解决这个问题,作者在第 3.2 节中介绍了一种基于并行前缀扫描算法的多对多 RNN 计算注意力的高效方法。在此基础上,作者在第 3.3 节中介绍了 Aaren—— 一个计算效率高的模块,它不仅可以并行训练(就像 Transformer),还可以在推理时用新 token 高效更新,推理只需要恒定的内存(就像传统 RNN)。查询向量 q 的注意力可被视为一个函数,它通过 N 个上下文 token x_1:N 的键和值 将其映射到单一输出 o_N = Attention (q, k_1:N , v_1:N ) 。给定 s_i = dot (q,k_i),输出 o_N 可表述为: 其中分子为 ,分母为。将注意力视为 RNN,可以在 k = 1,...,...... 时,以滚动求和的方式迭代计算和。然而,在实践中,这种实现方式并不稳定,会因有限的精度表示和可能非常小或非常大的指数(即 exp (s))而遇到数值问题。为了缓解这一问题,作者用累积最大值项 来重写递推公式,计算和。值得注意的是,最终结果是相同的,m_k 的循环计算如下:
将其映射到单一输出 o_N = Attention (q, k_1:N , v_1:N ) 。给定 s_i = dot (q,k_i),输出 o_N 可表述为: 其中分子为 ,分母为。将注意力视为 RNN,可以在 k = 1,...,...... 时,以滚动求和的方式迭代计算和。然而,在实践中,这种实现方式并不稳定,会因有限的精度表示和可能非常小或非常大的指数(即 exp (s))而遇到数值问题。为了缓解这一问题,作者用累积最大值项 来重写递推公式,计算和。值得注意的是,最终结果是相同的,m_k 的循环计算如下:
By encapsulating the loop calculations of a_k, c_k and m_k from a_(k-1), c_(k-1) and m_(k-1), the author introduces an RNN unit that can iteratively calculate attention output (see Figure 2). The attention RNN unit takes (a_(k-1), c_(k-1), m_(k-1), q) as input and computes (a_k, c_k, m_k, q). Note that the query vector q is passed in the RNN unit. The initial hidden state of the attention RNN is (a_0, c_0, m_0, q) = (0, 0, 0, q). Methods to calculate attention: By considering attention as an RNN, you can see different ways to calculate attention: loop calculation token by token in O (1) memory (i.e. sequential calculation) ;or computed in the traditional way (i.e. parallel computing), which requires linear O (N) memory. Since attention can be regarded as an RNN, the traditional method of calculating attention can also be regarded as an efficient method of calculating the output of the attention many-to-one RNN, that is, the output of the RNN takes multiple context tokens as input, but in At the end of the RNN, only one token is output (see Figure 1a). Finally, attention can also be computed as an RNN that processes tokens chunk by chunk, rather than fully sequentially or fully in parallel, which requires O(b) memory, where b is the size of the chunk. Consider existing attention models as RNNs. By treating attention as an RNN, existing attention-based models can also be viewed as variants of RNN. For example, the Transformer's self-attention is an RNN (Figure 1b), and the context token is its initial hidden state. Perceiver’s cross-attention is an RNN (Figure 1c) whose initial hidden state is a context-dependent latent variable. By leveraging RNN forms of their attention mechanism, these existing models can efficiently compute their output stores. However, when considering existing attention-based models (such as Transformers) as RNNs, these models lack the features commonly seen in traditional RNNs (such as LSTM and GRU). important attributes. It is worth noting that LSTM and GRU can effectively update themselves with new tokens in only O(1) constant memory and computation, in contrast to Transformer's The RNN view (see Figure 1b) handles new tokens by adding a new RNN with the new token as the initial state. This new RNN processes all previous tokens, requiring O(N) linear computation. In Perceiver, due to its architecture, latent variables (L_i in Figure 1c) are input-dependent, which means that their values are dependent on receiving new tokens. will change from time to time. As the initial hidden state (i.e. latent variables) of its RNN changes, Perceiver therefore needs to recompute its RNN from scratch, requiring a linear amount of computation of O (NL), where N is the number of tokens and L is the number of latent variables. Consider attention as a many-to-many RNNTo target these limitations , the authors propose to develop an attention-based model that leverages the power of the RNN formulation to perform efficient updates. To this end, the author first introduced an efficient parallelization method, using attention as a many-to-many RNN calculation, that is, a method of parallel calculation. To this end, the authors utilize the parallel prefix scan algorithm (see Algorithm 1), a parallel computing method that computes N prefixes from N consecutive data points via the correlation operator ⊕.This algorithm can efficiently calculate ##Review
, where , is for efficiency To calculate , you can calculate and through a parallel scan algorithm, and then combine a_k and c_k to calculate . To this end, the author proposes the following correlation operator ⊕, which acts on the form (m_A, u_A, w_A) A triplet, where A is a set of indices,
, , . The input to the parallel scan algorithm is . The algorithm recursively applies the operator ⊕ and works as follows: , where , . After completing the recursive application of the operator, the algorithm outputs . Also known as . Combining the last two values of the output tuple, is retrieved resulting in an efficient parallel method of computing attention as a many-to-many RNN (Figure 3). ##Aaren:[A] attention [a] s a [re] current neural [n] etworkAaren's interface is the same as Transformer, that is, N inputs are mapped to N outputs, and the i-th output is the 1st to Aggregation of i inputs. In addition, Aaren is naturally stackable and can calculate separate loss terms for each sequence token. However, unlike Transformers that use causal self-attention, Aaren uses the above method of computing attention as a many-to-many RNN, making it more efficient. The form of Aaren is as follows:
##Different from Transformer, the query in Transformer is input to attention One of the tokens, and in Aaren, the query token q is learned through backpropagation during the training process.
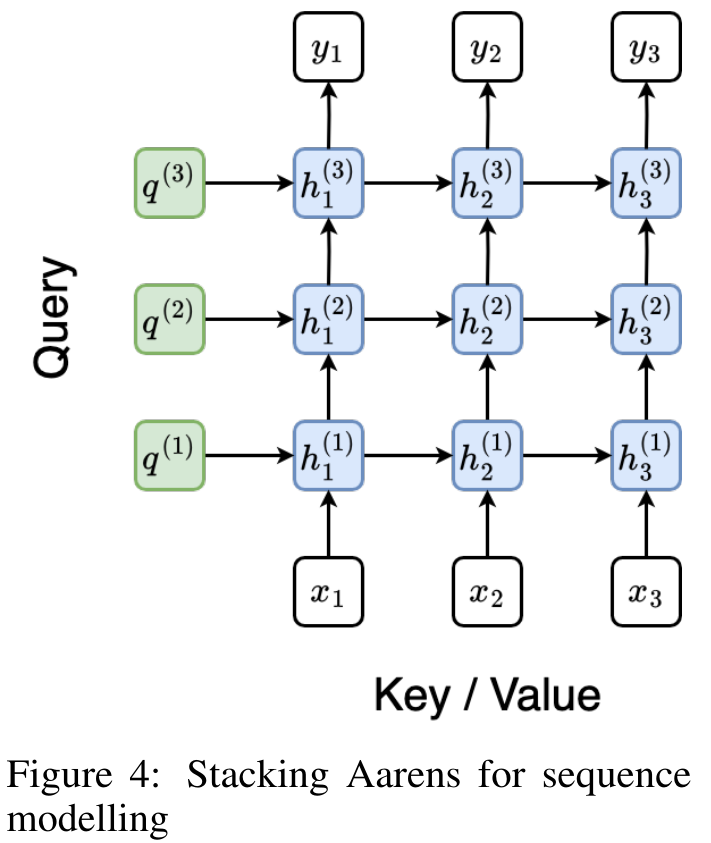
The following figure shows an example of a stacked Aaren model. The input context token of the model is x_1:3 and the output is y_1:3. It is worth noting that since Aaren utilizes the attention mechanism in the form of RNN, stacking Aarens is also equivalent to stacking RNN. Therefore, Aarens is also able to efficiently update with new tokens, i.e. the iterative computation of y_k only requires constant computation since it only depends on h_k-1 and x_k.
Transformer-based models require linear memory (when using KV cache) and need to store all Previous tokens, including those in the intermediate Transformer layer, but Aarens-based models only require constant memory and do not need to store all previous tokens, which makes Aarens significantly better than Transformer in computational efficiency. Experiment
The goal of the experimental part is to compare the performance and performance of Aaren and Transformer Performance in terms of resources (time and memory) required. For a comprehensive comparison, the authors performed evaluations on four problems: reinforcement learning, event prediction, time series prediction, and time series classification. Reinforcement Learning
The author first compared Aaren and Transformer in reinforcement learning Performance. Reinforcement learning is popular in interactive environments such as robotics, recommendation engines, and traffic control.
The results in Table 1 show that Aaren performs comparably with Transformer across all 12 datasets and 4 environments. However, unlike Transformer, Aaren is also an RNN and therefore can efficiently handle new environmental interactions in continuous computation, making it more suitable for reinforcement learning. Event prediction
Next, The authors compare the performance of Aaren and Transformer in event prediction. Event prediction is popular in many real-world settings, such as finance (e.g., transactions), healthcare (e.g., patient observation), and e-commerce (e.g., purchases).
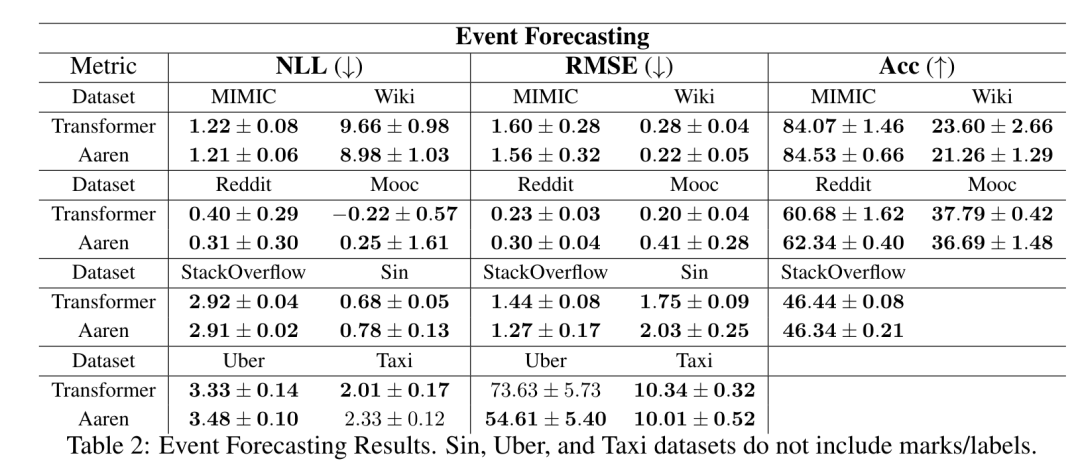
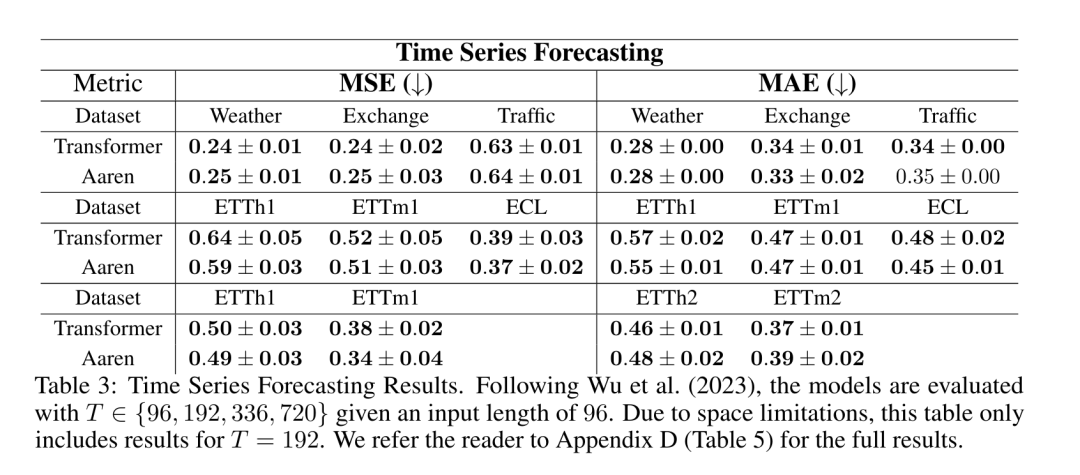
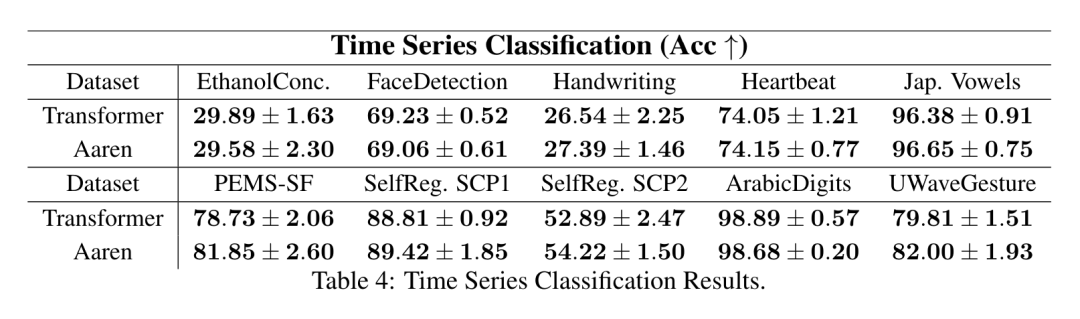
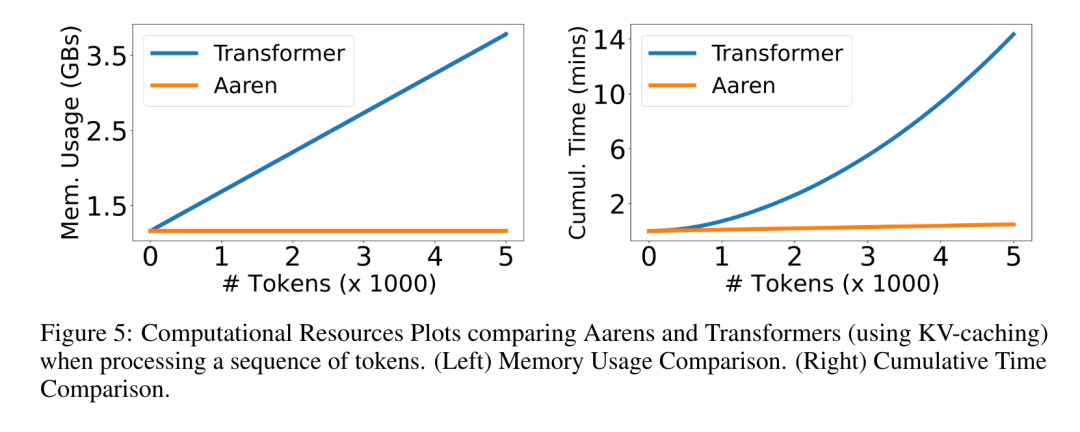
#The results in Table 2 show that Aaren performs comparably to Transformer on all datasets.Aaren's ability to efficiently process new inputs is particularly useful in event prediction environments, where events occur in irregular streams. Then, the author compared Aaren and Transformer in time series Performance in Forecasting. Time series forecasting models are commonly used in areas related to climate (such as weather), energy (such as supply and demand), and economics (such as stock prices). #The results in Table 3 show that Aaren performs comparably to Transformer on all datasets. However, unlike Transformer, Aaren can efficiently process time series data, making it more suitable for time series-related fields. Time series classificationNext, the author compared Aaren and Transformer in time Performance in sequence classification. Time series classification is common in many important applications, such as pattern recognition (e.g. electrocardiogram), anomaly detection (e.g. bank fraud) or fault prediction (e.g. power grid fluctuations). As can be seen from Table 4, the performance of Aaren and Transformer is comparable on all data sets. Finally, the author compares the resources required by Aaren and Transformer. Memory Complexity: In Figure 5 (left), the authors compare the memory usage of Aaren and Transformer (using KV cache) at inference time. It can be seen that with the use of KV cache technology, the memory usage of Transformer increases linearly. In contrast, Aaren only uses a constant amount of memory regardless of how the number of tokens grows, so it is much more efficient. Time complexity: In Figure 5 (right picture), the author compares the cumulative time required by Aaren and Transformer (using KV cache) to process a string of tokens in sequence. . For Transformer, the cumulative calculation amount is the square of the number of tokens, that is, O (1 + 2 + ... + N) = O (N^2). In contrast, Aaren's cumulative computational effort is linear. In the figure, you can see that the cumulative time required by the model has similar results. Specifically, the cumulative time required by Transformer increases quadratically, while the cumulative time required by Aaren increases linearly. Number of parameters: Due to the need to learn the initial hidden state q, the Aaren module requires slightly more parameters than the Transformer module. However, since q is just a vector, the difference is not significant. Through empirical measurements on similar models, the authors found that Transformer used 3, 152, 384 parameters. By comparison, the equivalent Aaren uses 3,152,896 parameters, a parameter increase of only 0.016%—a negligible price to pay for the significant difference in memory and time complexity.
以上是Bengio等人新作:注意力可被视为RNN,新模型媲美Transformer,但超级省内存的详细内容。更多信息请关注PHP中文网其他相关文章!



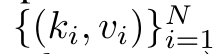 将其映射到单一输出 o_N = Attention (q, k_1:N , v_1:N ) 。给定 s_i = dot (q,k_i),输出 o_N 可表述为:
将其映射到单一输出 o_N = Attention (q, k_1:N , v_1:N ) 。给定 s_i = dot (q,k_i),输出 o_N 可表述为: 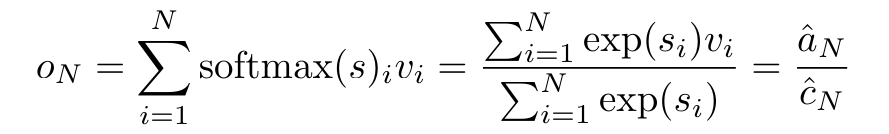
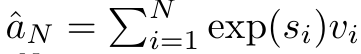 ,分母为
,分母为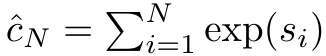 。将注意力视为 RNN,可以在 k = 1,...,...... 时,以滚动求和的方式迭代计算
。将注意力视为 RNN,可以在 k = 1,...,...... 时,以滚动求和的方式迭代计算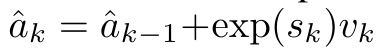 和
和 。然而,在实践中,这种实现方式并不稳定,会因有限的精度表示和可能非常小或非常大的指数(即 exp (s))而遇到数值问题。为了缓解这一问题,作者用累积最大值项
。然而,在实践中,这种实现方式并不稳定,会因有限的精度表示和可能非常小或非常大的指数(即 exp (s))而遇到数值问题。为了缓解这一问题,作者用累积最大值项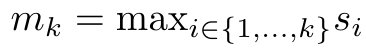 来重写递推公式,计算
来重写递推公式,计算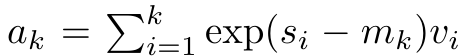 和
和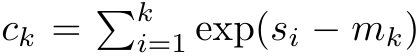 。值得注意的是,最终结果是相同的
。值得注意的是,最终结果是相同的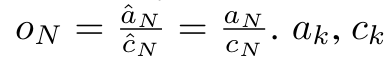 ,m_k 的循环计算如下:
,m_k 的循环计算如下:

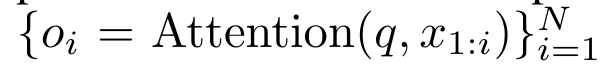 . To this end, the authors utilize the parallel prefix scan algorithm (see Algorithm 1), a parallel computing method that computes N prefixes from N consecutive data points via the correlation operator ⊕.This algorithm can efficiently calculate
. To this end, the authors utilize the parallel prefix scan algorithm (see Algorithm 1), a parallel computing method that computes N prefixes from N consecutive data points via the correlation operator ⊕.This algorithm can efficiently calculate 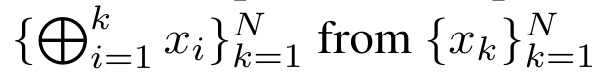

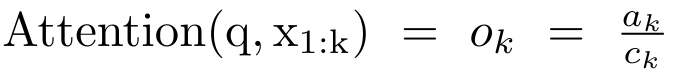
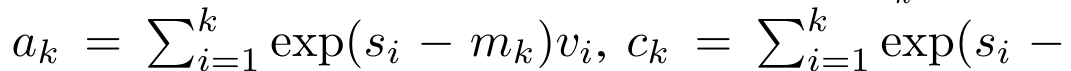 ,
, 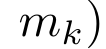 is for efficiency To calculate
is for efficiency To calculate 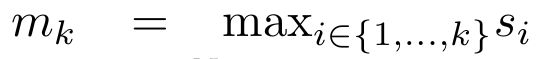 , you can calculate
, you can calculate 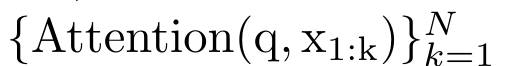 and
and 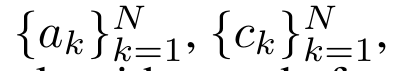 through a parallel scan algorithm, and then combine a_k and c_k to calculate
through a parallel scan algorithm, and then combine a_k and c_k to calculate  .
. 
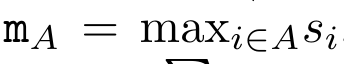
 ,
, 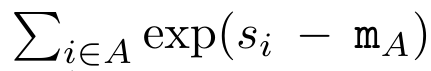
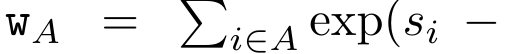 . The input to the parallel scan algorithm is
. The input to the parallel scan algorithm is 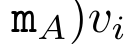 . The algorithm recursively applies the operator ⊕ and works as follows:
. The algorithm recursively applies the operator ⊕ and works as follows: 

 ,
, 
 .
. 
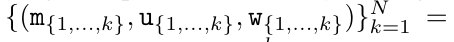
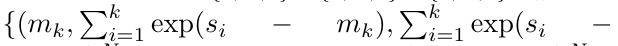
 . Also known as
. Also known as 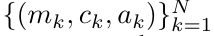 . Combining the last two values of the output tuple,
. Combining the last two values of the output tuple, 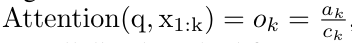 is retrieved resulting in an efficient parallel method of computing attention as a many-to-many RNN (Figure 3).
is retrieved resulting in an efficient parallel method of computing attention as a many-to-many RNN (Figure 3).