
英伟达新研究:上下文长度虚标严重,32K性能合格的都不多

- WBOY原创
- 2024-06-05 16:22:471081浏览
无情戳穿“长上下文”大模型的虚标现象——
英伟达新研究发现,包括GPT-4在内的10个大模型,生成达到128k甚至1M上下文长度的都有。
但一番考验下来,在新指标“有效上下文”上缩水严重,能达到32K的都不多。
新基准名为RULER,包含检索、多跳追踪、聚合、问答四大类共13项任务。RULER定义了“有效上下文长度”,即模型能保持与Llama-7B基线在4K长度下同等性能的最大长度。

这项研究被学者评价为“非常有洞察力”。

不少网友看到这项新研究后,也非常想看到上下文长度王者玩家Claude和Gemini的挑战结果。(论文中并未覆盖)


一起来看英伟达是如何定义“有效上下文”指标的。

测试任务更多、更难
要评测大模型的长文本理解能力,得先选个好标准,现圈内流行的ZeroSCROLLS、L-Eval、LongBench、InfiniteBench等,要么仅评估了模型检索能力,要么受限于先验知识的干扰。
所以英伟达剔除的RULER方法,一句话概括就是“确保评估侧重于模型处理和理解长上下文的能力,而不是从训练数据中回忆信息的能力”。
RULER的评测数据减少了对“参数化知识”的依赖,也就是大模型在训练过程中已经编码到自身参数里的知识。
具体来说,RULER基准扩展了流行的“大海捞针”测试,新增四大类任务。
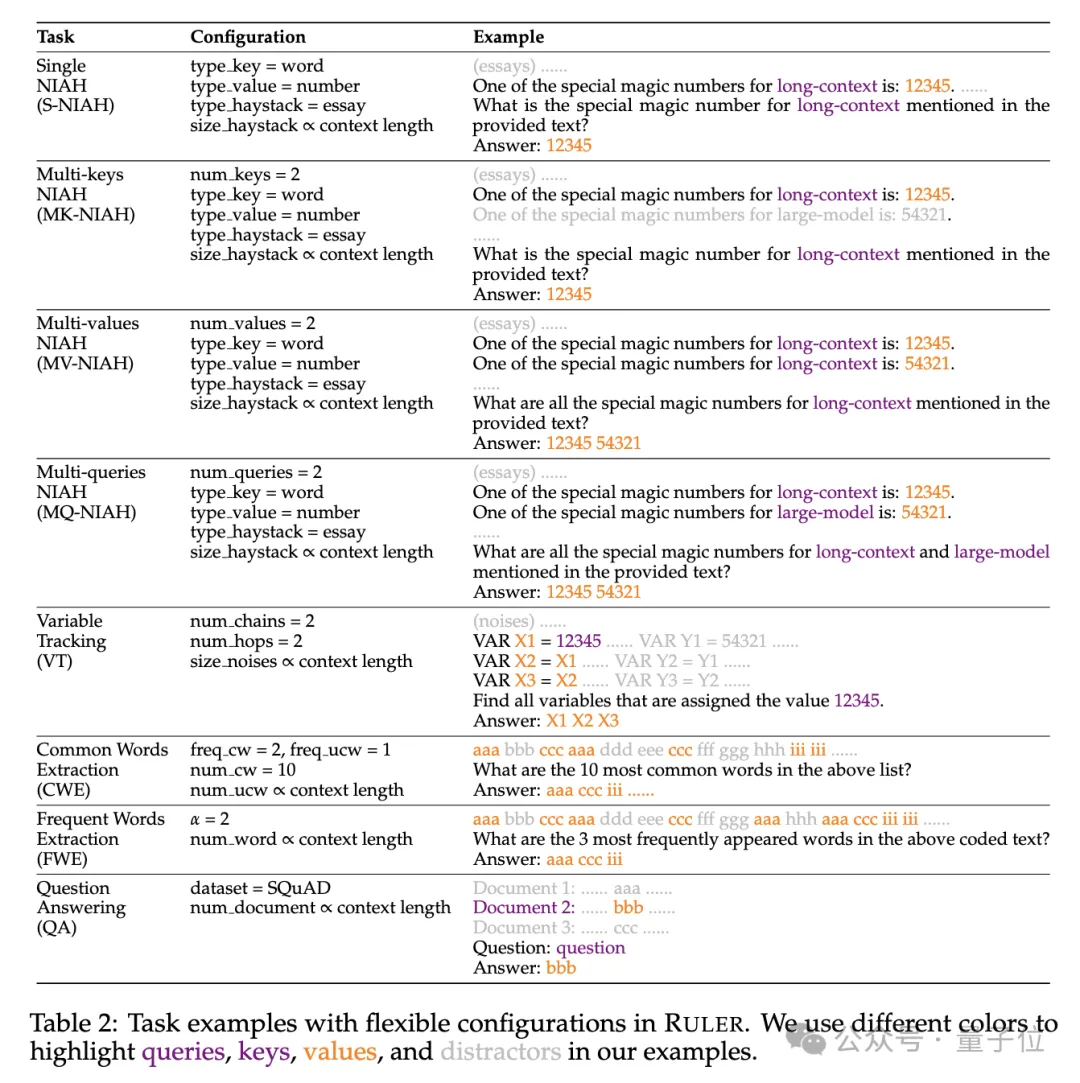
检索方面,从大海捞针标准的单针检索任务出发,又加入了如下新类型:
- 多针检索(Multi-keys NIAH, MK-NIAH):上下文中插入多个干扰针,模型需检索指定的那一个
- 多值检索(Multi-values NIAH, MV-NIAH):一个键(key)对应多个值(values),模型需要检索出与特定键关联的所有值。
- 多查询检索(Multi-queries NIAH, MQ-NIAH):模型需根据多个查询在文本中检索出相应的多个针。
除了升级版检索,RULER还增加了多跳追踪(Multi-hop Tracing)挑战。
具体来说,研究人员提出了变量追踪(VT),模拟了指代消解(coreference resolution)的最小任务,要求模型追踪文本中变量的赋值链,即使这些赋值在文本中是非连续的。
挑战第三关是聚合(Aggregation),包括:
- 常见词汇提取(Common Words Extraction, CWE):模型需要从文本中提取出现次数最多的常见词汇。
- 频繁词汇提取(Frequent Words Extraction, FWE):与CWE类似,但是词汇的出现频率是根据其在词汇表中的排名和Zeta分布参数α来确定的。

The fourth level of the challenge is Question and Answer Task(QA), which inserts a large amount of interference based on the existing reading comprehension data set (such as SQuAD) Paragraph, test long sequence QA ability.
How long is each model context actually?
During the experimental phase, as mentioned at the beginning, the researchers evaluated 10 language models claiming to support long context, including GPT-4, and 9 open source models Command-R, Yi-34B, Mixtral ( 8x7B), Mixtral (7B), ChatGLM, LWM, Together, LongChat, LongAlpaca.
The parameter sizes of these models range from 6B to 8x7B using MoE architecture, and the maximum context length ranges from 32K to 1M.
In the RULER benchmark test, each model was evaluated on 13 different tasks, covering 4 task categories, ranging from simple to complex difficulties. For each task, 500 test samples are generated, with input lengths ranging from 4K to 128K in 6 levels (4K, 8K, 16K, 32K, 64K, 128K) .

To prevent the model from refusing to answer the question, the input is appended with an answer prefix and the presence of the target output is checked for recall-based accuracy.

The researchers also defined the "effective context length" indicator, that is, the model can maintain the same performance level as the baseline Llama-7B at 4K length at this length.
For more detailed model comparison, the weighted average score (Weighted Average, wAvg) is used as a comprehensive indicator to perform a weighted average of the performance under different lengths. Two weighting schemes are adopted:
- wAvg(inc): The weight increases linearly with the length, simulating application scenarios dominated by long sequences
- wAvg(dec): The weight increases with the length Decrease linearly and simulate a scenario dominated by short sequences
to see the results.
No difference can be seen in the ordinary needle-in-a-haystack and password retrieval tests, with almost all models achieving perfect scores within their claimed context length range.
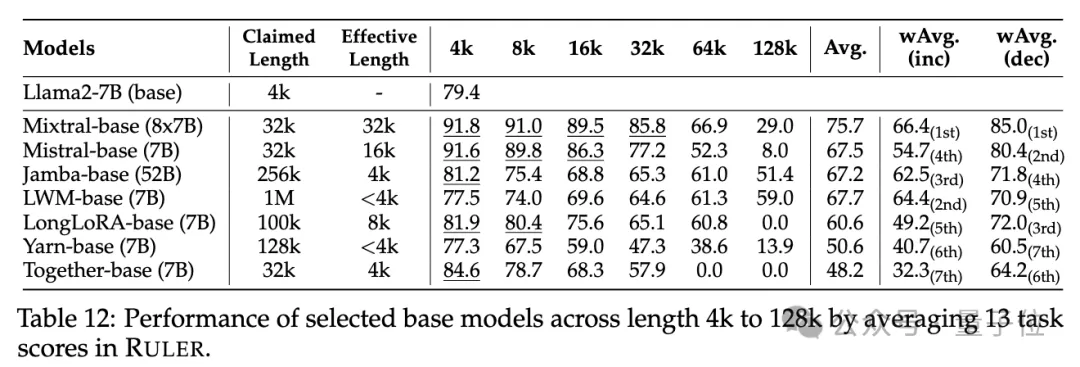
With RULER, although many models claim to be able to handle contexts of 32K tokens or longer, no model except Mixtral maintains performance exceeding the Llama2-7B baseline at its claimed length.

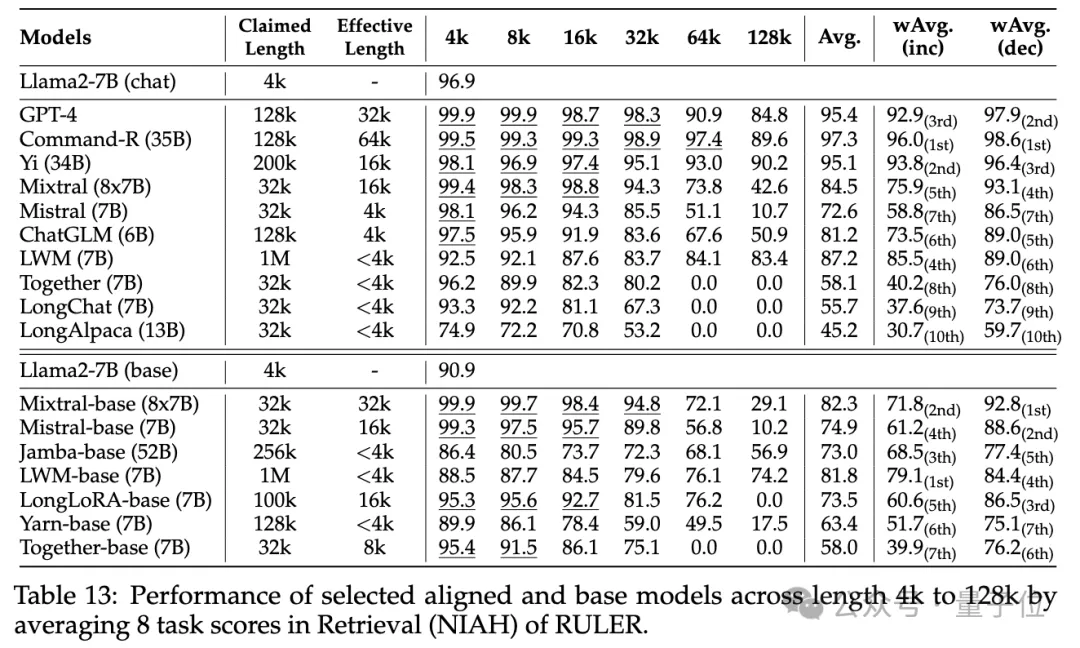
Other results are as follows. Overall, GPT-4 performs best at 4K length and shows minimal performance degradation when the context is extended to 128K(15.4%).
The top three open source models are Command-R, Yi-34B and Mixtral, which all use larger base frequency RoPE and have more parameters than other models.

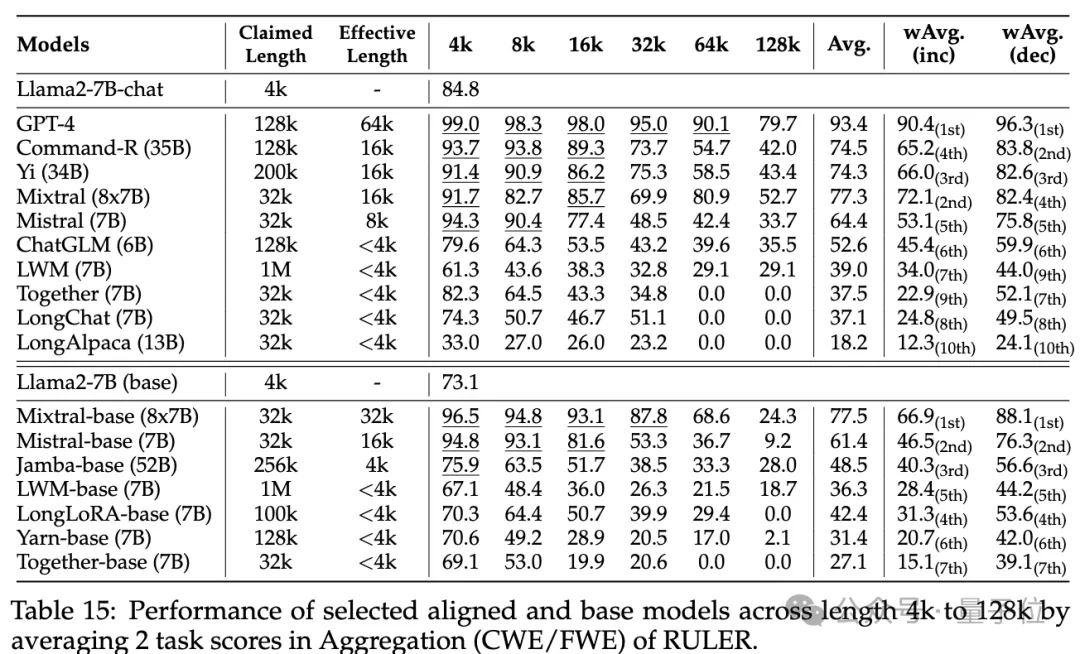

(up to 256K) and more complex tasks was analyzed in depth to understand the impact of task configurations and failure modes on RULER.
They also analyzed the impact of training context length, model size and architecture on model performance and found that training with a largerusually leads to better performance, but for long sequences Rankings may be inconsistent; increased model size has significant benefits for long context modeling; non-Transformer architectures (such as RWKV and Mamba) significantly lag behind Transformer-based Llama2-7B on RULER.
For more details, interested readers can view the original paper.Paper link: https://arxiv.org/abs/2404.06654
以上是英伟达新研究:上下文长度虚标严重,32K性能合格的都不多的详细内容。更多信息请关注PHP中文网其他相关文章!