



绝了,为了训练AI模型,一位纽约州立大学的教授,竟然把类似GoPro的相机绑在了自己女儿头上!
虽然听起来不可思议,但这位教授的行为,其实是有据可循的。

要训练出LLM背后的复杂神经网络,需要海量数据。
目前我们训练LLM的过程,一定是最简洁、最高效的方式吗?
肯定不是!科学家们发现,蹒跚学步的人类儿童,大脑就像海绵吸水一样,能迅速形成一个连贯的世界观。

虽然LLM时有惊人的表现,但随着时间的推移,人类儿童会比模型更聪明、更有创造力!
儿童掌握语言的秘密
如何用更好的方法训练LLM?
科学家们苦思不得其解之时,人类幼崽让他们眼前一亮——
他们学习语言的方式,堪称是语言习得的大师。

咱们都知道这样的故事:把一个幼年的孩子扔进一个语言文化完全不同的国家,不出几个月,ta对于当地语言的掌握可能就接近了母语水平。
而大语言模型,就显得相形见绌了。
首先,它们太费数据了!
如今训模型的各大公司,快把全世界的数据给薅空了。因为LLM的学习,需要的是从网络和各个地方挖掘的天文数字级的文本。
要让它们掌握一门语言,需要喂给它们数万亿个单词。

Brenden Lake和参与这项研究的NYU学者
其次,兴师动众地砸了这么多数据进去,LLM也未必学得准确。
许多LLM的输出,是以一定准确度预测下一个单词。而这种准确度,越来越令人不安。
形成鲜明对比的是,要学会流利使用一门语言,儿童可不需要这么多经验。
纽约州立大学研究人类和AI的心理学家Brenden Lake,就盯上了这一点。
他决定,拿自己1岁9个月的女儿Luna做实验。

过去的11个月里,Lake每周都会让女儿戴一个小时的相机,以她的角度记录玩耍时的视频。
通过Luna相机拍摄的视频,Lake希望通过使用孩子接触到的相同数据,来训练模型。

把GoPro绑在蹒跚学步的女儿身上
虽然目前语言学家和儿童专家对于儿童究竟如何习得语言,并未达成一致,但Lake十分确信:使LLM更有效率的秘诀,就藏在儿童的学习模式里!
因此,Lake开展了这样一项研究项目:研究儿童在学习第一句话时所经历的刺激,以此提高训练LLM的效率。
为此,Lake的团队需要收集来自美国各地的25名儿童的视频和音频数据。
这就有了文章开头的一幕——他们把类似GoPro的相机绑在了这些孩子的头上,包括Lake的女儿Luna。

Lake解释道,他们的模型试图从孩子的角度,将视频片段和孩子的照顾者所说的话联系起来,方式类似于OpenAI的Clip模型将标注和图像联系起来。
Clip可以将图像作为输入,并根据图像-标注对的训练数据,输出一个描述性标注作为建议。

论文地址:https://openai.com/index/clip/
另外,Lake团队的模型还可以根据GoPro镜头的训练数据和照顾者的音频,将场景的图像作为输入,然后输出语言来描述这个场景。
而且,模型还可以将描述转换为以前在训练中看到的帧。
乍一听,是不是还挺简单的?就是让模型像人类儿童一样,学会将口语和在视频帧中所观察到的物体相匹配。
但具体执行起来,还会面临很多复杂的状况。
比如,孩子们并不一定总是看着被描述的物体或动作。
甚至还有更抽象的情况,比如我们给孩子牛奶,但牛奶是装在不透明的杯子里,这就会导致关联非常松散。
因而,Lake解释说:这个实验并不是想证明,我们是否可以训练模型将图像中的对象与相应的单词相匹配(OpenAI已经证明了这一点)。
相反,团队想要做的是,希望知道模型是否可以只用儿童可用的稀疏数据级(稀疏到难以置信的程度),就能真的学习识别物体。
可以看到,这和OpenAI、谷歌、Meta等大公司构建模型的思路完全相反。
要知道,Meta训练Llama 3,用了15万亿个token。
如果Lake团队的实验成功,或许全世界共同面临的LLM数据荒,就有解了——因为那时,训练LLM根本就不需要那么多的数据!
也就是说,新的思路是,让AI模型从有限的输入中学习,然后从我们看到的数据中推广出来。
我认为我们的关注点,不该局限在从越来越多的数据中训练越来越大的LLM。是的,你可以通过这种方式让LLM具有惊人的性能,但它已经离我们所知道的人类智能奇妙之处越来越远……
早期实验已经取得成功
早期的实验结果,已经证明了Lake团队的思路可能是对的。
今年2月,他们曾经用了61小时的视频片段训出一个神经网络,纪录一个幼儿的经历。
研究发现,模型能够将被试说出的各种单词和短语,与视频帧中捕获的体验联系起来——只要呈现要给单词或短语,模型就能回忆起相关图像。这篇论文已经发表于Science。

论文地址:https://www.science.org/doi/10.1126/science.adi1374
Lake表示,最令人惊喜的是,模型竟然能够概括出未训练的图像中的对象名称!
当然,准确性未必很好。但模型本来也只是为了验证一个概念而已。
项目尚未完成,因为模型还没有学到一个儿童会知道的一切。

毕竟,它只有60小时左右的带标注的演讲,这仅仅是一个儿童在两年内所习得经验的百分之一。而团队还需要更多的数据,才能搞清什么是可学习的。
而且Lake也承认,第一个模型使用的方法还是有局限性——
仅分析与照顾者话语相关的视频片段,仅仅是镜头以每秒5帧的速度转化为图像,只凭这些,AI并没有真正学会什么是动词,什么是抽象词,它获得的仅仅是关于世界样子的静态切片。
因为它对之前发生了什么、之后发生了什么、谈话背景都一无所知,所以很难学习什么是「走」「跑」「跳」。
但以后,随着建模视频背后的技术越来越成熟,Lake相信团队会构建更有效的模型。
如果我们能够建立一个真正开始习得语言的模型,它就会为理解人类的学习和发展开辟重要的应用程序,或许能帮我们理解发育障碍,或儿童学习语言的情况。
最终,这样的模型还可以用来测试数百万种不同的语言治疗法。
话说回来,孩子究竟是如何通过自己的眼睛和耳朵,扎实地掌握一门语言的呢?

让我们仔细看看Lake团队发在Science上的这篇文章。
将单词和实物、视觉图像联系起来
人类儿童如何褪去对这个世界的懵懂无知,习得知识?这个「黑箱」的奥秘,不仅吸引着教育学家们的不断求索,也是困于我们每个人心底关于个体智慧来处的追问。
韩国科幻作家金草叶在《共生假说》中写下这样的设想:人类儿童在幼年时期所展示出的智慧其实承载着一个失落的外星文明,他们选择用这样的方式和人类共生,可是时间只有短短的五年,在人类长大拥有真正牢固的记忆之后,便把幼年时期这段瑰丽的记忆抹去了。
也时常有网友会在网上分享出,那些「忘记喝孟婆汤」的人类幼崽故事。
关于谜一样的幼年时期,那是我们很难说清也难以回返的神秘之地,是一种「乡愁」。就像金草叶写下的」不要离开。不要带走那个美丽的世界。在我长大之后,也请留在我身边。

幼儿究竟是如何将新单词和特定的物体,或视觉概念联系起来的?
比如,听到「球」这个词时,儿童是如何想到有弹性的圆形物体的?

为此,Lake的团队给一个儿童戴上了头戴式摄像机,追踪了ta从6到25个月期间的成长过程,记录了一个61小时的视觉语言数据流。
在这个儿童1.5年的剪辑数据集(包括60万个视频帧和37500条转录话语配对)上,研究者训练出了一个模型,即儿童视角对比学习模型CVCL。
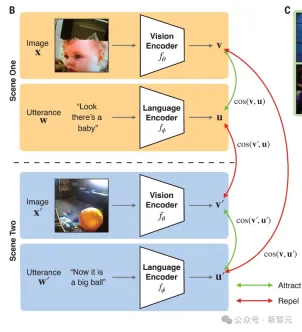
这个模型实例化了跨情景的联想学习形式,确定了单词和可能的视觉指示物之间的映射。
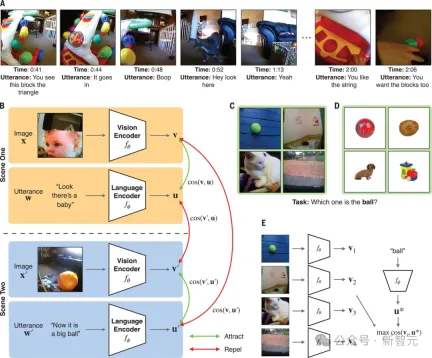
这个模型协调了两个神经网络、视觉编码器和语言编码器的对比目标,以自监督的方式进行训练(即仅使用儿童视角的录音,不使用外部标签),对比目标将视频帧的嵌入(向量)和时间上同时出现的语言话语结合在一起(处理同时出现的视频帧和语言话语的嵌入)
当然,这个名为SAYCam-S的数据集是有限的,因为它只捕获了孩子大约1%的清醒时间,错过了很多他们的经历。
但是尽管如此,CVCL依然可以从一个儿童的有限经历中,学习到强大的多模态表征!
团队成功地证明了,模型获取了儿童日常经历中存在许多的指涉映射,因而能够零样本地概括新的视觉指涉,并且调整其中的视觉和语言概念系统。
评估习得的词义映射
具体来说,在训练完成后,团队评估了CVCL和各种替代模型所学习的单词指涉映射的质量。
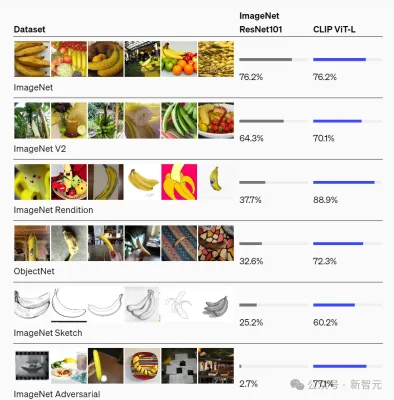
结果显示,CVCL的分类准确率为61.6%。
而且图2D显示,对于其中22个概念中的11个概念,CVCL的性能和CLIP的误差在5%以内,但CLIP的训练数据,却要多出几个数量级(4亿个来自网络的图像-文本对)。
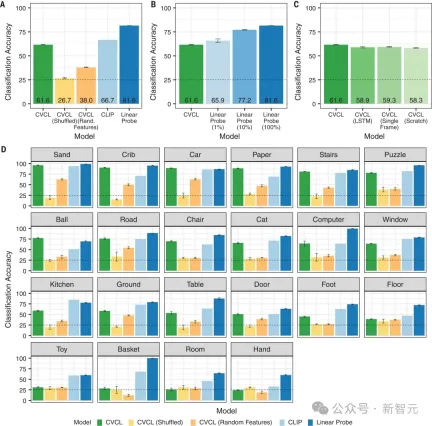
研究结果显示,许多最早的单词所指映射,可以从至少10到100个自然出现的单词-所指对中获得。
泛化新的视觉范例
另外,研究者还评估了CVCL学到的单词,是否可以推广到分布外的视觉刺激上。
图3A显示,CVCL也同时表现出了对这些视觉概念的一些了解,总体准确率在34.7%。
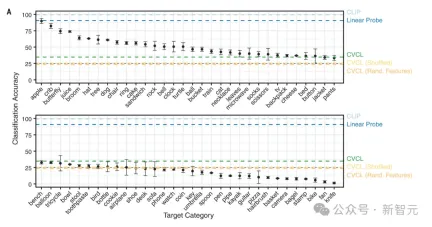
显然,这个任务需要更大的概念集,以及额外难度的分布外泛化。

左边是两个随机选择的训练案例,右边是四个测试案例,下面的百分比代表模型识别此张图像的准确度和性能,选取案例从左到右分别是两个最高值、中值和最低值。可以看出,当测试案例和训练案例在色彩、形状方面相似度更高时,模型识别的准确度也更高
多模态一致性很好
最后,研究者测试了CVCL的视觉和语言概念系统的一致性。
例如,如果相比于「球」, 「汽车」的视觉嵌入和词嵌入都与「路」更相似,这就表明多模态对齐的效果很好。
下图显示出,CVCL视觉和语言系统的高度对齐。
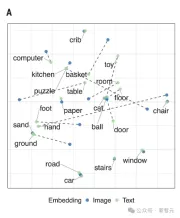
图像和文本之间的关系,虚线表示每个概念对应的视觉质心与单词嵌入之间的距离
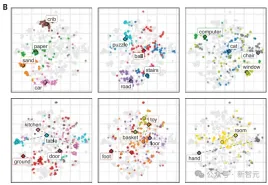
不同的视觉概念在其例子的紧密聚集程度上有所不同。因为婴儿的视线会在距离很近的物体之间游移,就导致模型在区分「手」和「玩具」时没有形成清晰的参照映射,「汽车」和「婴儿床」就有比较好的表现
在每幅图中,研究者直观展示了CVCL预测与使用t-SNE的标签示例的比较。

左边的蓝色点对应属于一个特定类别的100个帧,右边的绿色点对应于100个最高的激活帧(基于与CVCL中每个概念嵌入的单词的余弦相似性)。在每个图下面,是每个概念中属于一个或多个子簇的多个示例帧,捕捉了单词嵌入如何与联合嵌入空间中的图像嵌入交互。例如,对于「楼梯」这个词,我们看到一个簇代表室内木制楼梯的图像,而另一个主要簇代表室外蓝色楼梯组的图像。这些图中所有的t-SNE图都来自于同一组联合图像和文本嵌入。
下图显示,模型可以在不同视图中,定位目标所指。

在归一化注意力图中,黄色表示注意力最高的区域。在前两个类别(球和车)中,我们可以看到模型可以在不同视图中定位目标所指。但是,在下面两个类别(猫和纸)中,注意力图有时会与所指物错位,这表明定位所指物的能力并不是在所有类别中都一致的。
当然,儿童的学习和机器学习模型还是有许多不同的。
但Lake团队的研究,无疑对我们有很大的启发。
以上是美国教授用2岁女儿训AI模型登Science!人类幼崽头戴相机训练全新AI的详细内容。更多信息请关注PHP中文网其他相关文章!

 阅读AI索引2025:AI是您的朋友,敌人还是副驾驶?Apr 11, 2025 pm 12:13 PM
阅读AI索引2025:AI是您的朋友,敌人还是副驾驶?Apr 11, 2025 pm 12:13 PM斯坦福大学以人为本人工智能研究所发布的《2025年人工智能指数报告》对正在进行的人工智能革命进行了很好的概述。让我们用四个简单的概念来解读它:认知(了解正在发生的事情)、欣赏(看到好处)、接纳(面对挑战)和责任(弄清我们的责任)。 认知:人工智能无处不在,并且发展迅速 我们需要敏锐地意识到人工智能发展和传播的速度有多快。人工智能系统正在不断改进,在数学和复杂思维测试中取得了优异的成绩,而就在一年前,它们还在这些测试中惨败。想象一下,人工智能解决复杂的编码问题或研究生水平的科学问题——自2023年
 开始使用Meta Llama 3.2 -Analytics VidhyaApr 11, 2025 pm 12:04 PM
开始使用Meta Llama 3.2 -Analytics VidhyaApr 11, 2025 pm 12:04 PMMeta的Llama 3.2:多模式和移动AI的飞跃 Meta最近公布了Llama 3.2,这是AI的重大进步,具有强大的视觉功能和针对移动设备优化的轻量级文本模型。 以成功为基础
 AV字节:Meta' llama 3.2,Google的双子座1.5等Apr 11, 2025 pm 12:01 PM
AV字节:Meta' llama 3.2,Google的双子座1.5等Apr 11, 2025 pm 12:01 PM本周的AI景观:进步,道德考虑和监管辩论的旋风。 OpenAI,Google,Meta和Microsoft等主要参与者已经释放了一系列更新,从开创性的新车型到LE的关键转变
 与机器交谈的人类成本:聊天机器人真的可以在乎吗?Apr 11, 2025 pm 12:00 PM
与机器交谈的人类成本:聊天机器人真的可以在乎吗?Apr 11, 2025 pm 12:00 PM连接的舒适幻想:我们在与AI的关系中真的在蓬勃发展吗? 这个问题挑战了麻省理工学院媒体实验室“用AI(AHA)”研讨会的乐观语气。事件展示了加油
 了解Python的Scipy图书馆Apr 11, 2025 am 11:57 AM
了解Python的Scipy图书馆Apr 11, 2025 am 11:57 AM介绍 想象一下,您是科学家或工程师解决复杂问题 - 微分方程,优化挑战或傅立叶分析。 Python的易用性和图形功能很有吸引力,但是这些任务需要强大的工具
 3种运行Llama 3.2的方法-Analytics VidhyaApr 11, 2025 am 11:56 AM
3种运行Llama 3.2的方法-Analytics VidhyaApr 11, 2025 am 11:56 AMMeta's Llama 3.2:多式联运AI强力 Meta的最新多模式模型Llama 3.2代表了AI的重大进步,具有增强的语言理解力,提高的准确性和出色的文本生成能力。 它的能力t
 使用dagster自动化数据质量检查Apr 11, 2025 am 11:44 AM
使用dagster自动化数据质量检查Apr 11, 2025 am 11:44 AM数据质量保证:与Dagster自动检查和良好期望 保持高数据质量对于数据驱动的业务至关重要。 随着数据量和源的增加,手动质量控制变得效率低下,容易出现错误。
 大型机在人工智能时代有角色吗?Apr 11, 2025 am 11:42 AM
大型机在人工智能时代有角色吗?Apr 11, 2025 am 11:42 AM大型机:AI革命的无名英雄 虽然服务器在通用应用程序上表现出色并处理多个客户端,但大型机是专为关键任务任务而建立的。 这些功能强大的系统经常在Heavil中找到


热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

EditPlus 中文破解版
体积小,语法高亮,不支持代码提示功能

SublimeText3 Linux新版
SublimeText3 Linux最新版

WebStorm Mac版
好用的JavaScript开发工具

禅工作室 13.0.1
功能强大的PHP集成开发环境

Atom编辑器mac版下载
最流行的的开源编辑器

