


大数据处理在 C 中使用数据结构进行优化,包括:数组: 用于存储相同类型元素,动态数组可随需求调整大小。哈希表: 用于快速查找和插入键值对,即使数据集很大。二叉树: 用于快速查找、插入和删除元素,如二叉搜索树。图数据结构: 用于表示连接关系,如无向图可以存储节点和边的关系。优化考虑因素: 包括并行处理、数据分区和缓存以提高性能。

C 技术中的大数据处理:设计优化的数据结构
简介
大数据处理在 C 中是一项常见的挑战,需要使用精心设计的算法和数据结构来有效管理和操作庞大的数据集。本文将介绍一些优化的大数据数据结构以及在实际中的使用案例。
数组
数组是存储相同数据类型元素的简单且高效的数据结构。在处理大数据时,可以使用动态数组(如 std::vector)来动态地增加或减少其大小,以满足不断变化的需求。
示例:
std::vector<int> numbers;
// 添加元素
numbers.push_back(10);
numbers.push_back(20);
// 访问元素
for (const auto& num : numbers) {
std::cout << num << " ";
}哈希表
哈希表是一种用于快速查找和插入元素的键值对数据结构。在处理大数据时,哈希表(如 std::unordered_map)可以根据键值高效地查找数据,即使数据集非常大。
示例:
std::unordered_map<std::string, int> word_counts;
// 插入元素
word_counts["hello"]++;
// 查找元素
auto count = word_counts.find("hello");二叉树
二叉树是一种树形数据结构,其中每个节点最多有两个子节点。二叉搜索树(如 std::set)允许快速查找、插入和删除元素,即使数据集很大。
示例:
std::set<int> numbers; // 插入元素 numbers.insert(10); numbers.insert(20); // 查找元素 auto found = numbers.find(10);
图数据结构
图数据结构是一种非线性数据结构,其中元素以节点和边的形式表示。在处理大数据时,图数据结构(如 std::unordered_map<int std::vector>></int>)可用于表示复杂的连接关系。
示例:
std::unordered_map<int, std::vector<int>> graph;
// 添加边
graph[1].push_back(2);
graph[1].push_back(3);
// 遍历图
for (const auto& [node, neighbors] : graph) {
std::cout << node << ": ";
for (const auto& neighbor : neighbors) {
std::cout << neighbor << " ";
}
std::cout << std::endl;
}其他优化考虑因素
除了选择正确的数据结构之外,还可以通过以下方式进一步优化大数据处理:
- 并行处理:使用多线程或多处理器并行处理数据。
- 数据分区:将大数据集划分为较小的块,以便同时处理多个块。
- 缓存:将频繁访问的数据存储在快速访问内存中,以减少读/写操作的延迟。
以上是C++技术中的大数据处理:如何设计优化的数据结构以处理大数据集?的详细内容。更多信息请关注PHP中文网其他相关文章!

 在 Microsoft Excel 中如何创建数据透视表Apr 22, 2023 pm 12:10 PM
在 Microsoft Excel 中如何创建数据透视表Apr 22, 2023 pm 12:10 PM当您拥有大量数据时,分析数据通常会变得越来越困难。但真的必须如此吗?MicrosoftExcel提供了一个令人惊叹的内置功能,称为数据透视表,可用于轻松分析庞大的数据块。它们可用于通过创建您自己的自定义报告来有效地汇总您的数据。它们可用于自动计算列的总和,可以对其应用过滤器,可以对其中的数据进行排序等。可以对数据透视表执行的操作以及如何使用数据透视表为了缓解您的日常excel障碍是无止境的。继续阅读,了解如何轻松创建数据透视表并了解如何有效组织它。希望你喜欢阅读这篇文章。第1节:什么是数据透视
 如何阻止 Apple 在 iPhone 上收集诊断和使用数据Apr 16, 2023 pm 09:25 PM
如何阻止 Apple 在 iPhone 上收集诊断和使用数据Apr 16, 2023 pm 09:25 PM苹果以其对用户隐私的承诺而闻名。当您购买iPhone或Mac时,您知道您正在投资一家承诺保护您的数据的公司的产品。这在我们这个时代非常重要——因为我们越来越多地将更多的个人信息存储在这些设备上。我们使用的大多数设备都会收集使用数据以改进相应的产品和服务。例如,当应用程序在您的手机上崩溃时,可以通知开发人员以帮助他们查明此错误的原因。虽然这些数据通常是匿名的,但一些用户不喜欢让公司收集他们的日志。此外,通过共享这些诊断信息,您的设备会将它们上传到公司的服务器。这可能会耗尽您的(有限)数据计划和部分
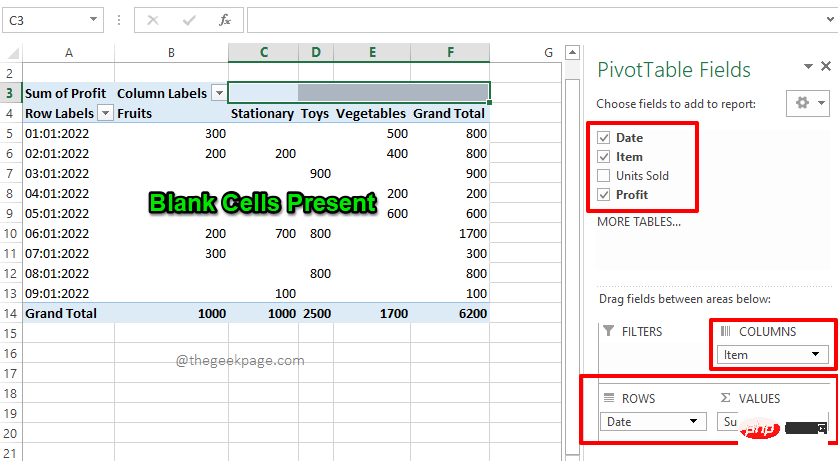 如何用零替换 Excel 数据透视表中的空白单元格Apr 15, 2023 am 11:52 AM
如何用零替换 Excel 数据透视表中的空白单元格Apr 15, 2023 am 11:52 AM了COLUMNS部分下的字段Item、ROWS部分下的字段Date和VALUES部分下的Profit字段。注意:如果您需要有关数据透视表如何工作以及如何有效地创建数据透视表的更多信息,请参阅我们的文章如何在MicrosoftExcel中创建数据透视表。因此,根据我的选择,我的数据透视表生成如下面的屏幕截图所示,使其成为我想要的完美摘要报告。但是,如果您查看数据透视表,您会发现我的数据透视表中有一些空白单元格。现在,让我们在接下来的步骤中将它们替换为零。第6步:要用零替换空白单元格,首先右键单击数
 如何在 Microsoft Excel 图表中添加和自定义数据标签?May 07, 2023 pm 04:22 PM
如何在 Microsoft Excel 图表中添加和自定义数据标签?May 07, 2023 pm 04:22 PMMicrosoft Excel有许多至今令人们惊叹的功能。人们每天都会学到一些新东西。今天,我们将了解如何在Excel图表中添加和自定义数据标签。Excel图表包含大量数据,一眼看懂图表可能具有挑战性。使用数据标签是指出重要信息的好方法。数据标签可以用作柱形图或条形图的一部分。当您创建饼图时,它甚至可以用作标注。添加数据标签为了展示如何添加数据标签,我们将以饼图为例。虽然大多数人使用图例来显示饼图中的内容,但数据标签的效率要高得多。要添加数据标签,请创建饼图。打开它,然后单击显示图表设计
 AI 算法在大数据治理中的应用Apr 12, 2023 pm 01:37 PM
AI 算法在大数据治理中的应用Apr 12, 2023 pm 01:37 PM本文主要分享 Datacake 在大数据治理中,AI 算法的应用经验。本次分享分为五大部分:第一部分阐明大数据与 AI 的关系,大数据不仅可以服务于 AI,也可以使用 AI 来优化自身服务,两者是互相支撑、依赖的关系;第二部分介绍利用 AI 模型综合评估大数据任务健康度的应用实践,为后续开展数据治理提供量化依据;第三部分介绍利用 AI 模型智能推荐 Spark 任务运行参数配置的应用实践,实现了提高云资源利用率的目标;第四部分介绍在 SQL 查询场景中,由模型智能推荐任务执行引擎的实践;第五部分

 腾讯广告模型基于"太极"的训练成本优化实践Apr 14, 2023 pm 06:46 PM
腾讯广告模型基于"太极"的训练成本优化实践Apr 14, 2023 pm 06:46 PM近年来,大数据加大模型成为了AI领域建模的标准范式。在广告场景,大模型由于使用了更多的模型参数,利用更多的训练数据,模型具备了更强的记忆能力和泛化能力,为广告效果向上提升打开了更大的空间。但是大模型在训练过程中所需要的资源也是成倍的增长,存储以及计算上的压力对机器学习平台都是巨大的挑战。腾讯太极机器学习平台持续探索降本增效方案,在广告离线训练场景利用混合部署资源大大降低了资源成本,每天为腾讯广告提供50W核心廉价混合部署资源,帮助腾讯广告离线模型训练资源成本降低30%,同时通过一系列优化手段使得
 如何使用 Go 语言进行大数据分析?Jun 11, 2023 am 11:11 AM
如何使用 Go 语言进行大数据分析?Jun 11, 2023 am 11:11 AM随着数据规模逐渐增大,大数据分析变得越来越重要。而Go语言作为一门快速、轻量级的编程语言,也成为了越来越多数据科学家和工程师的选择。本文将介绍如何使用Go语言进行大数据分析。数据采集在开始大数据分析之前,我们需要先采集数据。Go语言有很多包可以用于数据采集,例如“net/http”、“io/ioutil”等。通过这些包,我们可以从网站、API、日志


热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

SublimeText3汉化版
中文版,非常好用

PhpStorm Mac 版本
最新(2018.2.1 )专业的PHP集成开发工具

EditPlus 中文破解版
体积小,语法高亮,不支持代码提示功能

螳螂BT
Mantis是一个易于部署的基于Web的缺陷跟踪工具,用于帮助产品缺陷跟踪。它需要PHP、MySQL和一个Web服务器。请查看我们的演示和托管服务。

适用于 Eclipse 的 SAP NetWeaver 服务器适配器
将Eclipse与SAP NetWeaver应用服务器集成。

