


实例的背景说明
假定一个个人信息系统,需要记录系统中各个人的故乡、居住地、以及到过的城市。数据库设计如下:
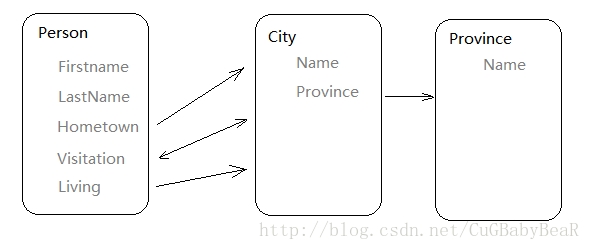
Models.py 内容如下:
from django.db import models class Province(models.Model): name = models.CharField(max_length=10) def __unicode__(self): return self.name class City(models.Model): name = models.CharField(max_length=5) province = models.ForeignKey(Province) def __unicode__(self): return self.name class Person(models.Model): firstname = models.CharField(max_length=10) lastname = models.CharField(max_length=10) visitation = models.ManyToManyField(City, related_name = "visitor") hometown = models.ForeignKey(City, related_name = "birth") living = models.ForeignKey(City, related_name = "citizen") def __unicode__(self): return self.firstname + self.lastname
注1:创建的app名为“QSOptimize”
注2:为了简化起见,`qsoptimize_province` 表中只有2条数据:湖北省和广东省,`qsoptimize_city`表中只有三条数据:武汉市、十堰市和广州市
prefetch_related()
对于多对多字段(ManyToManyField)和一对多字段,可以使用prefetch_related()来进行优化。或许你会说,没有一个叫OneToManyField的东西啊。实际上 ,ForeignKey就是一个多对一的字段,而被ForeignKey关联的字段就是一对多字段了。
作用和方法
prefetch_related()和select_related()的设计目的很相似,都是为了减少SQL查询的数量,但是实现的方式不一样。后者是通过JOIN语句,在SQL查询内解决问题。但是对于多对多关系,使用SQL语句解决就显得有些不太明智,因为JOIN得到的表将会很长,会导致SQL语句运行时间的增加和内存占用的增加。若有n个对象,每个对象的多对多字段对应Mi条,就会生成Σ(n)Mi 行的结果表。
prefetch_related()的解决方法是,分别查询每个表,然后用Python处理他们之间的关系。继续以上边的例子进行说明,如果我们要获得张三所有去过的城市,使用prefetch_related()应该是这么做:
>>> zhangs = Person.objects.prefetch_related('visitation').get(firstname=u"张",lastname=u"三")
>>> for city in zhangs.visitation.all() :
... print city
...
上述代码触发的SQL查询如下:
SELECT `QSOptimize_person`.`id`, `QSOptimize_person`.`firstname`, `QSOptimize_person`.`lastname`, `QSOptimize_person`.`hometown_id`, `QSOptimize_person`.`living_id` FROM `QSOptimize_person` WHERE (`QSOptimize_person`.`lastname` = '三' AND `QSOptimize_person`.`firstname` = '张'); SELECT (`QSOptimize_person_visitation`.`person_id`) AS `_prefetch_related_val`, `QSOptimize_city`.`id`, `QSOptimize_city`.`name`, `QSOptimize_city`.`province_id` FROM `QSOptimize_city` INNER JOIN `QSOptimize_person_visitation` ON (`QSOptimize_city`.`id` = `QSOptimize_person_visitation`.`city_id`) WHERE `QSOptimize_person_visitation`.`person_id` IN (1);
第一条SQL查询仅仅是获取张三的Person对象,第二条比较关键,它选取关系表`QSOptimize_person_visitation`中`person_id`为张三的行,然后和`city`表内联(INNER JOIN 也叫等值连接)得到结果表。
+----+-----------+----------+-------------+-----------+ | id | firstname | lastname | hometown_id | living_id | +----+-----------+----------+-------------+-----------+ | 1 | 张 | 三 | 3 | 1 | +----+-----------+----------+-------------+-----------+ 1 row in set (0.00 sec) +-----------------------+----+-----------+-------------+ | _prefetch_related_val | id | name | province_id | +-----------------------+----+-----------+-------------+ | 1 | 1 | 武汉市 | 1 | | 1 | 2 | 广州市 | 2 | | 1 | 3 | 十堰市 | 1 | +-----------------------+----+-----------+-------------+ 3 rows in set (0.00 sec)
显然张三武汉、广州、十堰都去过。
又或者,我们要获得湖北的所有城市名,可以这样:
>>> hb = Province.objects.prefetch_related('city_set').get(name__iexact=u"湖北省")
>>> for city in hb.city_set.all():
... city.name
...
触发的SQL查询:
SELECT `QSOptimize_province`.`id`, `QSOptimize_province`.`name` FROM `QSOptimize_province` WHERE `QSOptimize_province`.`name` LIKE '湖北省' ; SELECT `QSOptimize_city`.`id`, `QSOptimize_city`.`name`, `QSOptimize_city`.`province_id` FROM `QSOptimize_city` WHERE `QSOptimize_city`.`province_id` IN (1);
得到的表:
+----+-----------+ | id | name | +----+-----------+ | 1 | 湖北省 | +----+-----------+ 1 row in set (0.00 sec) +----+-----------+-------------+ | id | name | province_id | +----+-----------+-------------+ | 1 | 武汉市 | 1 | | 3 | 十堰市 | 1 | +----+-----------+-------------+ 2 rows in set (0.00 sec)
我们可以看见,prefetch使用的是 IN 语句实现的。这样,在QuerySet中的对象数量过多的时候,根据数据库特性的不同有可能造成性能问题。
使用方法
*lookups 参数
prefetch_related()在Django
>>> zhangs = Person.objects.prefetch_related('visitation__province').filter(firstname__iexact=u'张')
>>> for i in zhangs:
... for city in i.visitation.all():
... print city.province
...
触发的SQL:
SELECT `QSOptimize_person`.`id`, `QSOptimize_person`.`firstname`, `QSOptimize_person`.`lastname`, `QSOptimize_person`.`hometown_id`, `QSOptimize_person`.`living_id` FROM `QSOptimize_person` WHERE `QSOptimize_person`.`firstname` LIKE '张' ; SELECT (`QSOptimize_person_visitation`.`person_id`) AS `_prefetch_related_val`, `QSOptimize_city`.`id`, `QSOptimize_city`.`name`, `QSOptimize_city`.`province_id` FROM `QSOptimize_city` INNER JOIN `QSOptimize_person_visitation` ON (`QSOptimize_city`.`id` = `QSOptimize_person_visitation`.`city_id`) WHERE `QSOptimize_person_visitation`.`person_id` IN (1, 4); SELECT `QSOptimize_province`.`id`, `QSOptimize_province`.`name` FROM `QSOptimize_province` WHERE `QSOptimize_province`.`id` IN (1, 2);
获得的结果:
+----+-----------+----------+-------------+-----------+ | id | firstname | lastname | hometown_id | living_id | +----+-----------+----------+-------------+-----------+ | 1 | 张 | 三 | 3 | 1 | | 4 | 张 | 六 | 2 | 2 | +----+-----------+----------+-------------+-----------+ 2 rows in set (0.00 sec) +-----------------------+----+-----------+-------------+ | _prefetch_related_val | id | name | province_id | +-----------------------+----+-----------+-------------+ | 1 | 1 | 武汉市 | 1 | | 1 | 2 | 广州市 | 2 | | 4 | 2 | 广州市 | 2 | | 1 | 3 | 十堰市 | 1 | +-----------------------+----+-----------+-------------+ 4 rows in set (0.00 sec) +----+-----------+ | id | name | +----+-----------+ | 1 | 湖北省 | | 2 | 广东省 | +----+-----------+ 2 rows in set (0.00 sec)
值得一提的是,链式prefetch_related会将这些查询添加起来,就像1.7中的select_related那样。
要注意的是,在使用QuerySet的时候,一旦在链式操作中改变了数据库请求,之前用prefetch_related缓存的数据将会被忽略掉。这会导致Django重新请求数据库来获得相应的数据,从而造成性能问题。这里提到的改变数据库请求指各种filter()、exclude()等等最终会改变SQL代码的操作。而all()并不会改变最终的数据库请求,因此是不会导致重新请求数据库的。
举个例子,要获取所有人访问过的城市中带有“市”字的城市,这样做会导致大量的SQL查询:
plist = Person.objects.prefetch_related('visitation')
[p.visitation.filter(name__icontains=u"市") for p in plist]
因为数据库中有4人,导致了2+4次SQL查询:
SELECT `QSOptimize_person`.`id`, `QSOptimize_person`.`firstname`, `QSOptimize_person`.`lastname`, `QSOptimize_person`.`hometown_id`, `QSOptimize_person`.`living_id` FROM `QSOptimize_person`; SELECT (`QSOptimize_person_visitation`.`person_id`) AS `_prefetch_related_val`, `QSOptimize_city`.`id`, `QSOptimize_city`.`name`, `QSOptimize_city`.`province_id` FROM `QSOptimize_city` INNER JOIN `QSOptimize_person_visitation` ON (`QSOptimize_city`.`id` = `QSOptimize_person_visitation`.`city_id`) WHERE `QSOptimize_person_visitation`.`person_id` IN (1, 2, 3, 4); SELECT `QSOptimize_city`.`id`, `QSOptimize_city`.`name`, `QSOptimize_city`.`province_id` FROM `QSOptimize_city` INNER JOIN `QSOptimize_person_visitation` ON (`QSOptimize_city`.`id` = `QSOptimize_person_visitation`.`city_id`) WHERE(`QSOptimize_person_visitation`.`person_id` = 1 AND `QSOptimize_city`.`name` LIKE '%市%' ); SELECT `QSOptimize_city`.`id`, `QSOptimize_city`.`name`, `QSOptimize_city`.`province_id` FROM `QSOptimize_city` INNER JOIN `QSOptimize_person_visitation` ON (`QSOptimize_city`.`id` = `QSOptimize_person_visitation`.`city_id`) WHERE (`QSOptimize_person_visitation`.`person_id` = 2 AND `QSOptimize_city`.`name` LIKE '%市%' ); SELECT `QSOptimize_city`.`id`, `QSOptimize_city`.`name`, `QSOptimize_city`.`province_id` FROM `QSOptimize_city` INNER JOIN `QSOptimize_person_visitation` ON (`QSOptimize_city`.`id` = `QSOptimize_person_visitation`.`city_id`) WHERE (`QSOptimize_person_visitation`.`person_id` = 3 AND `QSOptimize_city`.`name` LIKE '%市%' ); SELECT `QSOptimize_city`.`id`, `QSOptimize_city`.`name`, `QSOptimize_city`.`province_id` FROM `QSOptimize_city` INNER JOIN `QSOptimize_person_visitation` ON (`QSOptimize_city`.`id` = `QSOptimize_person_visitation`.`city_id`) WHERE (`QSOptimize_person_visitation`.`person_id` = 4 AND `QSOptimize_city`.`name` LIKE '%市%' );
详细分析一下这些请求事件。
众所周知,QuerySet是lazy的,要用的时候才会去访问数据库。运行到第二行Python代码时,for循环将plist看做iterator,这会触发数据库查询。最初的两次SQL查询就是prefetch_related导致的。
虽然已经查询结果中包含所有所需的city的信息,但因为在循环体中对Person.visitation进行了filter操作,这显然改变了数据库请求。因此这些操作会忽略掉之前缓存到的数据,重新进行SQL查询。
但是如果有这样的需求了应该怎么办呢?在Django >= 1.7,可以通过下一节的Prefetch对象来实现,如果你的环境是Django
plist = Person.objects.prefetch_related('visitation')
[[city for city in p.visitation.all() if u"市" in city.name] for p in plist]
Prefetch 对象
在Django >= 1.7,可以用Prefetch对象来控制prefetch_related函数的行为。
注:由于我没有安装1.7版本的Django环境,本节内容是参考Django文档写的,没有进行实际的测试。
Prefetch对象的特征:
- 一个Prefetch对象只能指定一项prefetch操作。
- Prefetch对象对字段指定的方式和prefetch_related中的参数相同,都是通过双下划线连接的字段名完成的。
- 可以通过 queryset 参数手动指定prefetch使用的QuerySet。
- 可以通过 to_attr 参数指定prefetch到的属性名。
- Prefetch对象和字符串形式指定的lookups参数可以混用。
继续上面的例子,获取所有人访问过的城市中带有“武”字和“州”的城市:
wus = City.objects.filter(name__icontains = u"武")
zhous = City.objects.filter(name__icontains = u"州")
plist = Person.objects.prefetch_related(
Prefetch('visitation', queryset = wus, to_attr = "wu_city"),
Prefetch('visitation', queryset = zhous, to_attr = "zhou_city"),)
[p.wu_city for p in plist]
[p.zhou_city for p in plist]
注:这段代码没有在实际环境中测试过,若有不正确的地方请指正。
顺带一提,Prefetch对象和字符串参数可以混用。
None
可以通过传入一个None来清空之前的prefetch_related。就像这样:
>>> prefetch_cleared_qset = qset.prefetch_related(None)
小结
- prefetch_related主要针一对多和多对多关系进行优化。
- prefetch_related通过分别获取各个表的内容,然后用Python处理他们之间的关系来进行优化。
- 可以通过可变长参数指定需要select_related的字段名。指定方式和特征与select_related是相同的。
- 在Django >= 1.7可以通过Prefetch对象来实现复杂查询,但低版本的Django好像只能自己实现。
- 作为prefetch_related的参数,Prefetch对象和字符串可以混用。
- prefetch_related的链式调用会将对应的prefetch添加进去,而非替换,似乎没有基于不同版本上区别。
- 可以通过传入None来清空之前的prefetch_related。

 如何使用numpy创建多维数组?Apr 29, 2025 am 12:27 AM
如何使用numpy创建多维数组?Apr 29, 2025 am 12:27 AM使用NumPy创建多维数组可以通过以下步骤实现:1)使用numpy.array()函数创建数组,例如np.array([[1,2,3],[4,5,6]])创建2D数组;2)使用np.zeros(),np.ones(),np.random.random()等函数创建特定值填充的数组;3)理解数组的shape和size属性,确保子数组长度一致,避免错误;4)使用np.reshape()函数改变数组形状;5)注意内存使用,确保代码清晰高效。
 说明Numpy阵列中'广播”的概念。Apr 29, 2025 am 12:23 AM
说明Numpy阵列中'广播”的概念。Apr 29, 2025 am 12:23 AM播放innumpyisamethodtoperformoperationsonArraySofDifferentsHapesbyAutapityallate AligningThem.itSimplifififiesCode,增强可读性,和Boostsperformance.Shere'shore'showitworks:1)较小的ArraySaraySaraysAraySaraySaraySaraySarePaddedDedWiteWithOnestOmatchDimentions.2)
 说明如何在列表,Array.Array和用于数据存储的Numpy数组之间进行选择。Apr 29, 2025 am 12:20 AM
说明如何在列表,Array.Array和用于数据存储的Numpy数组之间进行选择。Apr 29, 2025 am 12:20 AMforpythondataTastorage,choselistsforflexibilityWithMixedDatatypes,array.ArrayFormeMory-effficityHomogeneousnumericalData,andnumpyArraysForAdvancedNumericalComputing.listsareversareversareversareversArversatilebutlessEbutlesseftlesseftlesseftlessforefforefforefforefforefforefforefforefforefforlargenumerdataSets; arrayoffray.array.array.array.array.array.ersersamiddreddregro
 举一个场景的示例,其中使用Python列表比使用数组更合适。Apr 29, 2025 am 12:17 AM
举一个场景的示例,其中使用Python列表比使用数组更合适。Apr 29, 2025 am 12:17 AMPythonlistsarebetterthanarraysformanagingdiversedatatypes.1)Listscanholdelementsofdifferenttypes,2)theyaredynamic,allowingeasyadditionsandremovals,3)theyofferintuitiveoperationslikeslicing,but4)theyarelessmemory-efficientandslowerforlargedatasets.
 您如何在Python数组中访问元素?Apr 29, 2025 am 12:11 AM
您如何在Python数组中访问元素?Apr 29, 2025 am 12:11 AMtoAccesselementsInapyThonArray,useIndIndexing:my_array [2] accessEsthethEthErlement,returning.3.pythonosezero opitedEndexing.1)usepositiveandnegativeIndexing:my_list [0] fortefirstElment,fortefirstelement,my_list,my_list [-1] fornelast.2] forselast.2)
 Python中有可能理解吗?如果是,为什么以及如果不是为什么?Apr 28, 2025 pm 04:34 PM
Python中有可能理解吗?如果是,为什么以及如果不是为什么?Apr 28, 2025 pm 04:34 PM文章讨论了由于语法歧义而导致的Python中元组理解的不可能。建议使用tuple()与发电机表达式使用tuple()有效地创建元组。(159个字符)
 Python中的模块和包装是什么?Apr 28, 2025 pm 04:33 PM
Python中的模块和包装是什么?Apr 28, 2025 pm 04:33 PM本文解释了Python中的模块和包装,它们的差异和用法。模块是单个文件,而软件包是带有__init__.py文件的目录,在层次上组织相关模块。
 Python中的Docstring是什么?Apr 28, 2025 pm 04:30 PM
Python中的Docstring是什么?Apr 28, 2025 pm 04:30 PM文章讨论了Python中的Docstrings,其用法和收益。主要问题:Docstrings对于代码文档和可访问性的重要性。


热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

Video Face Swap
使用我们完全免费的人工智能换脸工具轻松在任何视频中换脸!

热门文章
热工具

VSCode Windows 64位 下载
微软推出的免费、功能强大的一款IDE编辑器

SublimeText3 英文版
推荐:为Win版本,支持代码提示!

DVWA
Damn Vulnerable Web App (DVWA) 是一个PHP/MySQL的Web应用程序,非常容易受到攻击。它的主要目标是成为安全专业人员在合法环境中测试自己的技能和工具的辅助工具,帮助Web开发人员更好地理解保护Web应用程序的过程,并帮助教师/学生在课堂环境中教授/学习Web应用程序安全。DVWA的目标是通过简单直接的界面练习一些最常见的Web漏洞,难度各不相同。请注意,该软件中

SublimeText3汉化版
中文版,非常好用

SecLists
SecLists是最终安全测试人员的伙伴。它是一个包含各种类型列表的集合,这些列表在安全评估过程中经常使用,都在一个地方。SecLists通过方便地提供安全测试人员可能需要的所有列表,帮助提高安全测试的效率和生产力。列表类型包括用户名、密码、URL、模糊测试有效载荷、敏感数据模式、Web shell等等。测试人员只需将此存储库拉到新的测试机上,他就可以访问到所需的每种类型的列表。

