



一、web框架本质
1.基于socket,自己处理请求
#!/usr/bin/env python3
#coding:utf8
import socket
def handle_request(client):
#接收请求
buf = client.recv(1024)
print(buf)
#返回信息
client.send(bytes('<h1 id="welcome-liuyao-webserver">welcome liuyao webserver</h1>','utf8'))
def main():
#创建sock对象
sock = socket.socket()
#监听80端口
sock.bind(('localhost',8000))
#最大连接数
sock.listen(5)
print('welcome nginx')
#循环
while True:
#等待用户的连接,默认accept阻塞当有请求的时候往下执行
connection,address = sock.accept()
#把连接交给handle_request函数
handle_request(connection)
#关闭连接
connection.close()
if __name__ == '__main__':
main()
2.基于wsgi
WSGI,全称 Web Server Gateway Interface,或者 Python Web Server Gateway Interface ,是为 Python 语言定义的 Web 服务器和 Web 应用程序或框架之间的一种简单而通用的接口。自从 WSGI 被开发出来以后,许多其它语言中也出现了类似接口。
WSGI 的官方定义是,the Python Web Server Gateway Interface。从名字就可以看出来,这东西是一个Gateway,也就是网关。网关的作用就是在协议之间进行转换。
WSGI 是作为 Web 服务器与 Web 应用程序或应用框架之间的一种低级别的接口,以提升可移植 Web 应用开发的共同点。WSGI 是基于现存的 CGI 标准而设计的。
很多框架都自带了 WSGI server ,比如 Flask,webpy,Django、CherryPy等等。当然性能都不好,自带的 web server 更多的是测试用途,发布时则使用生产环境的 WSGI server或者是联合 nginx 做 uwsgi 。
python标准库提供的独立WSGI服务器称为wsgiref。
#!/usr/bin/env python
#coding:utf-8
#导入wsgi模块
from wsgiref.simple_server import make_server
def RunServer(environ, start_response):
start_response('200 OK', [('Content-Type', 'text/html')])
return [bytes("welcome webserver".encode('utf8'))]
if __name__ == '__main__':
httpd = make_server('', 8000, RunServer)
print ("Serving HTTP on port 8000...")
httpd.serve_forever()
#接收请求
#预处理请求(封装了很多http请求的东西)
请求过来后就执行RunServer这个函数。
原理图:
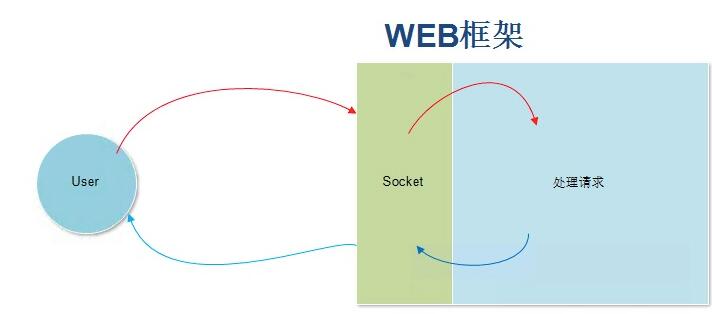
当用户发送请求,socket将请求交给函数处理,之后再返回给用户。
二、自定义web框架
python标准库提供的wsgiref模块开发一个自己的Web框架
之前的使用wsgiref只能访问一个url
下面这个可以根据你访问的不同url请求进行处理并且返回给用户
#!/usr/bin/env python
#coding:utf-8
from wsgiref.simple_server import make_server
def RunServer(environ, start_response):
start_response('200 OK', [('Content-Type','text/html')])
#根据url的不同,返回不同的字符串
#1 获取URL[URL从哪里获取?当请求过来之后执行RunServer,
#wsgi给咱们封装了这些请求,这些请求都封装到了,environ & start_response]
request_url = environ['PATH_INFO']
print (request_url)
#2 根据URL做不同的相应
#print environ #这里可以通过断点来查看它都封装了什么数据
if request_url == '/login':
return [bytes("welcome login",'utf8')]
elif request_url == '/reg':
return [bytes("welcome reg",'utf8')]
else:
return [bytes('<h1 id="no-found">404! no found</h1>','utf8')]
if __name__ == '__main__':
httpd = make_server('', 8000, RunServer)
print ("Serving HTTP on port 8000...")
httpd.serve_forever()
当然 以上虽然根据不同url来进行处理,但是如果大量url的话,那么代码写起来就很繁琐。
所以使用下面方法进行处理
#!/usr/bin/env python
#coding:utf-8
from wsgiref.simple_server import make_server
def index():
return [bytes('<h1 id="index">index</h1>','utf8')]
def login():
return [bytes('<h1 id="login">login</h1>','utf8')]
def reg():
return [bytes('<h1 id="reg">reg</h1>','utf8')]
def layout():
return [bytes('<h1 id="layout">layout</h1>','utf8')]
#定义一个列表 把url和上面的函数做一个对应
urllist = [
('/index',index),
('/login',login),
('/reg',reg),
('/layout',layout),
]
def RunServer(environ, start_response):
start_response('200 OK', [('Content-Type','text/html')])
#根据url的不同,返回不同的字符串
#1 获取URL[URL从哪里获取?当请求过来之后执行RunServer,wsgi给咱们封装了这些请求,这些请求都封装到了,environ & start_response]
request_url = environ['PATH_INFO']
print (request_url)
#2 根据URL做不同的相应
#print environ #这里可以通过断点来查看它都封装了什么数据
#循环这个列表 找到你打开的url 返回url对应的函数
for url in urllist:
if request_url == url[0]:
return url[1]()
else:
#url_list列表里都没有返回404
return [bytes('<h1 id="not-found">404 not found</h1>','utf8')]
if __name__ == '__main__':
httpd = make_server('', 8000, RunServer)
print ("Serving HTTP on port 8000...")
httpd.serve_forever()
三、模板引擎
对应上面的操作 都是根据用户访问的url返回给用户一个字符串的 比如return xxx
案例:
首先写一个index.html页面
内容:
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>index</title> </head> <body> <h1 id="welcome-index">welcome index</h1> </body> </html>
login.html页面
内容:
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>login</title> </head> <body> <h1 id="welcome-login">welcome login</h1> <form> user:<input type="text"/> pass:<input type="password"/> <button type="button">login in</button> </form> </body> </html>
python代码:
#!/usr/bin/env python
#coding:utf-8
from wsgiref.simple_server import make_server
def index():
#把index页面读进来返回给用户
indexfile = open('index.html','r+').read()
return [bytes(indexfile,'utf8')]
def login():
loginfile = open('login.html','r+').read()
return [bytes(loginfile,'utf8')]
urllist = [
('/login',login),
('/index',index),
]
def RunServer(environ, start_response):
start_response('200 OK', [('Content-Type','text/html')])
#根据url的不同,返回不同的字符串
#1 获取URL[URL从哪里获取?当请求过来之后执行RunServer,wsgi给咱们封装了这些请求,这些请求都封装到了,environ & start_response]
request_url = environ['PATH_INFO']
print (request_url)
#2 根据URL做不同的相应
#print environ #这里可以通过断点来查看它都封装了什么数据
for url in urllist:
#如果用户请求的url和咱们定义的rul匹配
if request_url == url[0]:
#执行
return url[1]()
else:
#url_list列表里都没有返回404
return [bytes('<h1 id="not-found">404 not found</h1>','utf8')]
if __name__ == '__main__':
httpd = make_server('', 8000, RunServer)
print ("Serving HTTP on port 8000...")
httpd.serve_forever()
但是以上内容只能返回给静态内容,不能返回动态内容
那么如何返回动态内容呢
自定义一套特殊的语法,进行替换
使用开源工具jinja2,遵循其指定语法
index.html 遵循jinja语法进行替换、循环、判断
先展示大概效果,具体jinja2会在下章django笔记来进行详细说明
index.html页面
内容:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
<!--general replace-->
<h1 id="name">{{ name }}</h1>
<h1 id="age">{{ age }}</h1>
<h1 id="time">{{ time }}</h1>
<!--for circular replace-->
<ul>
{% for item in user_list %}
<li>{{ item }}</li>
{% endfor %}
</ul>
<!--if else judge-->
{% if num == 1 %}
<h1 id="num">num == 1</h1>
{% else %}
<h1 id="num">num == 2</h1>
{% endif %}
</body>
</html>
python代码:
#!/usr/bin/env python
#-*- coding:utf-8 -*-
import time
#导入wsgi模块
from wsgiref.simple_server import make_server
#导入jinja模块
from jinja2 import Template
def index():
#打开index.html
data = open('index.html').read()
#使用jinja2渲染
template = Template(data)
result = template.render(
name = 'yaoyao',
age = '18',
time = str(time.time()),
user_list = ['linux','python','bootstarp'],
num = 1
)
#同样是替换为什么用jinja,因为他不仅仅是文本的他还支持if判断 & for循环 操作
#这里需要注意因为默认是的unicode的编码所以设置为utf-8
return [bytes(result,'utf8')]
urllist = [
('/index',index),
]
def RunServer(environ, start_response):
start_response('200 OK', [('Content-Type', 'text/html')])
#根据url的不同,返回不同的字符串
#1 获取URL[URL从哪里获取?当请求过来之后执行RunServer,
# wsgi给咱们封装了这些请求,这些请求都封装到了,environ & start_response]
request_url = environ['PATH_INFO']
print(request_url)
#2 根据URL做不同的相应
#循环这个列表
for url in urllist:
#如果用户请求的url和咱们定义的rul匹配
if request_url == url[0]:
print (url)
return url[1]()
else:
#urllist列表里都没有返回404
return [bytes('<h1 id="not-found">404 not found</h1>','utf8')]
if __name__ == '__main__':
httpd = make_server('', 8000, RunServer)
print ("Serving HTTP on port 8000...")
httpd.serve_forever()
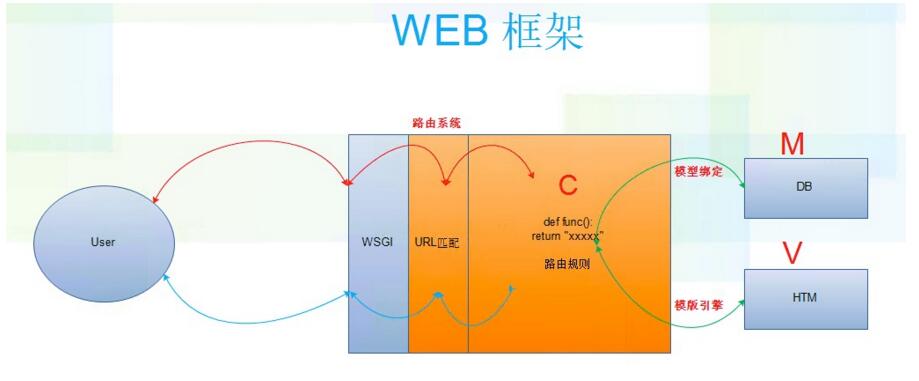
四、MVC和MTV
1.MVC
全名是Model View Controller,是模型(model)-视图(view)-控制器(controller)的缩写,一种软件设计典范,用一种业务逻辑、数据、界面显示分离的方法组织代码,将业务逻辑聚集到一个部件里面,在改进和个性化定制界面及用户交互的同时,不需要重新编写业务逻辑。MVC被独特的发展起来用于映射传统的输入、处理和输出功能在一个逻辑的图形化用户界面的结构中。
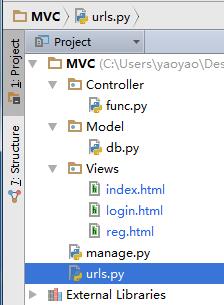
将路由规则放入urls.py
操作urls的放入controller里的func函数
将数据库操作党风model里的db.py里
将html页面等放入views里
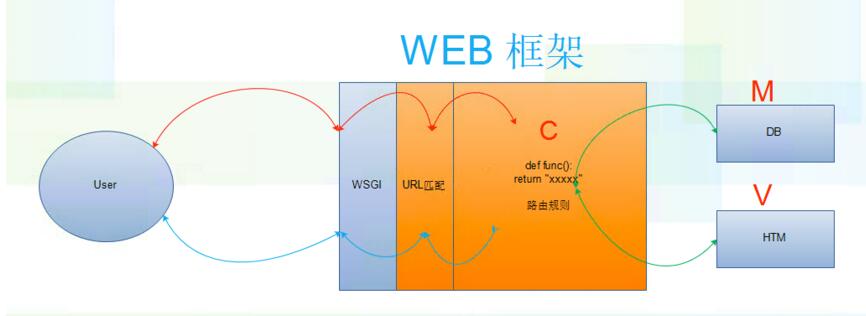
原理图:
2.MTV
Models 处理DB操作
Templates html模板
Views 处理函数请求
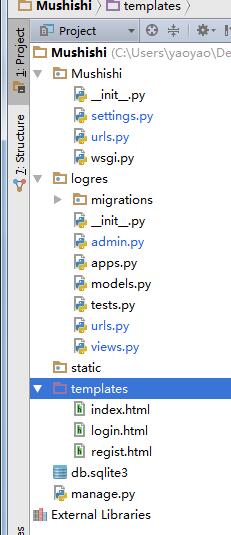
原理图:
以上就是本文的全部内容,希望对大家的学习有所帮助。

 Python vs. C:了解关键差异Apr 21, 2025 am 12:18 AM
Python vs. C:了解关键差异Apr 21, 2025 am 12:18 AMPython和C 各有优势,选择应基于项目需求。1)Python适合快速开发和数据处理,因其简洁语法和动态类型。2)C 适用于高性能和系统编程,因其静态类型和手动内存管理。
 Python vs.C:您的项目选择哪种语言?Apr 21, 2025 am 12:17 AM
Python vs.C:您的项目选择哪种语言?Apr 21, 2025 am 12:17 AM选择Python还是C 取决于项目需求:1)如果需要快速开发、数据处理和原型设计,选择Python;2)如果需要高性能、低延迟和接近硬件的控制,选择C 。
 达到python目标:每天2小时的力量Apr 20, 2025 am 12:21 AM
达到python目标:每天2小时的力量Apr 20, 2025 am 12:21 AM通过每天投入2小时的Python学习,可以有效提升编程技能。1.学习新知识:阅读文档或观看教程。2.实践:编写代码和完成练习。3.复习:巩固所学内容。4.项目实践:应用所学于实际项目中。这样的结构化学习计划能帮助你系统掌握Python并实现职业目标。
 最大化2小时:有效的Python学习策略Apr 20, 2025 am 12:20 AM
最大化2小时:有效的Python学习策略Apr 20, 2025 am 12:20 AM在两小时内高效学习Python的方法包括:1.回顾基础知识,确保熟悉Python的安装和基本语法;2.理解Python的核心概念,如变量、列表、函数等;3.通过使用示例掌握基本和高级用法;4.学习常见错误与调试技巧;5.应用性能优化与最佳实践,如使用列表推导式和遵循PEP8风格指南。
 在Python和C之间进行选择:适合您的语言Apr 20, 2025 am 12:20 AM
在Python和C之间进行选择:适合您的语言Apr 20, 2025 am 12:20 AMPython适合初学者和数据科学,C 适用于系统编程和游戏开发。1.Python简洁易用,适用于数据科学和Web开发。2.C 提供高性能和控制力,适用于游戏开发和系统编程。选择应基于项目需求和个人兴趣。
 Python与C:编程语言的比较分析Apr 20, 2025 am 12:14 AM
Python与C:编程语言的比较分析Apr 20, 2025 am 12:14 AMPython更适合数据科学和快速开发,C 更适合高性能和系统编程。1.Python语法简洁,易于学习,适用于数据处理和科学计算。2.C 语法复杂,但性能优越,常用于游戏开发和系统编程。
 每天2小时:Python学习的潜力Apr 20, 2025 am 12:14 AM
每天2小时:Python学习的潜力Apr 20, 2025 am 12:14 AM每天投入两小时学习Python是可行的。1.学习新知识:用一小时学习新概念,如列表和字典。2.实践和练习:用一小时进行编程练习,如编写小程序。通过合理规划和坚持不懈,你可以在短时间内掌握Python的核心概念。
 Python与C:学习曲线和易用性Apr 19, 2025 am 12:20 AM
Python与C:学习曲线和易用性Apr 19, 2025 am 12:20 AMPython更易学且易用,C 则更强大但复杂。1.Python语法简洁,适合初学者,动态类型和自动内存管理使其易用,但可能导致运行时错误。2.C 提供低级控制和高级特性,适合高性能应用,但学习门槛高,需手动管理内存和类型安全。


热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

Video Face Swap
使用我们完全免费的人工智能换脸工具轻松在任何视频中换脸!

热门文章
热工具

SublimeText3汉化版
中文版,非常好用

SublimeText3 英文版
推荐:为Win版本,支持代码提示!

SublimeText3 Linux新版
SublimeText3 Linux最新版

WebStorm Mac版
好用的JavaScript开发工具

mPDF
mPDF是一个PHP库,可以从UTF-8编码的HTML生成PDF文件。原作者Ian Back编写mPDF以从他的网站上“即时”输出PDF文件,并处理不同的语言。与原始脚本如HTML2FPDF相比,它的速度较慢,并且在使用Unicode字体时生成的文件较大,但支持CSS样式等,并进行了大量增强。支持几乎所有语言,包括RTL(阿拉伯语和希伯来语)和CJK(中日韩)。支持嵌套的块级元素(如P、DIV),

