


Application Resilience Engineering and Operations at Netflix By Ben Christensen Netflix的应用容错设计与运维 1. 随着系统规模的增大, 以及大规模SOA化的部署, 服务本身的可靠性与时延成为系统的关键问题. 2. 由于上层的服务会依赖大量的下层服务, 上层
Application Resilience Engineering and Operations at Netflix
By Ben Christensen
Netflix的应用容错设计与运维
1. 随着系统规模的增大, 以及大规模SOA化的部署, 服务本身的可靠性与时延成为系统的关键问题.
2. 由于上层的服务会依赖大量的下层服务, 上层服务的可用率与可靠性受到严重调整,假设下层服务的可用率为99.99,如果上层业务同时依赖30个下层服务,则上层的可用率为1- 30*(1-99.99%)=99.7%
3. 详细介绍了Netflix的故障容错技术, 如何通过Bulkheads/Failfast/Fail Silent等方式隔离下层的故障对上层业务的影响,如何做到优雅降级.
4. 详细介绍Netflix的监控大盘,每个组件的作用,具体的指标的处理,各种故障容错开关的状态.
Bring the Noise: Making Effective Use of a Quarter Million Metrics
By Abe Stanway
重点介绍Etsy的监控系统,
1.收集大量的metrics,
2.如何保存这么大量的metrics,
3.如何通过算法快速的找到系统中的异常(anomaly detection),skyline系统
4. 如何通过系统的算法快速有效的分析有类似异常波动的系统,oculus系统
Stop the Guessing: Performance Methodologies for Production Systems
By Brenden Gregg
Linux系统优化的方法论, 重点介绍Gregg自己发明的USE(Utilization/Saturation/Errors)
Guessing Methodologies
- 1. Traffic Light Anti-Method
- 2. Average Anti-Method
- 3. Concentration Game Anti-Method
Not Guessing Methodologies
- 4. Workload Characterization Method, 从治本的角度看,我喜欢使用这种方法,根据应用特征分析负载的来源.
- 5. USE Method, 从应急故障检测与分析来看,从处理效率角度看,这种方法很好,不过需要对Linux的系统工具有相当深入的了解/理解.
- 6. Thread State Analysis Method
Quantifying Abnormal Behavior
By Baron Schwartz
施瓦茨从Percona离开后,自己创建了一家专门做MySQL监控与故障检测的公司, 这里介绍的内容与他们的产品有一定的关联.
1. 怎样判断系统有故障? 系统挂了? 指标超出阈值?
2. 阈值带来的困惑: 误报? 该报没报? 如何决策
3. 系统发生故障的场景: 宕机/死机是叫少见的(1% Annual error Rate?), 局部故障, 以及局部故障时间积累导致的故障蔓延.
4. 故障检测技术: Shewhart Control Chart/滑动窗口/Holt-Winters预测/
5. 排队论基础的简要介绍(little’s Law,Gunter’s USL),
6. EWMA, 基于权重的指数移动平均(Load Average的计算方法),
7. 一种可能/可行的正常性指标(anomaly,是否异常?): 基于EWMA与EWMASoS打分.
A Systematic Approach to Capacity Planning in the Real World
By Bryce Yan
Twitter的性能分析与容量规划实践.
1. 容量瓶颈的可能原因,从资源角度理解,主要为: CPU/RAM/Storage(Disk IOPS/Disk Capacity)/Network(Interrupt/Bandwidth)
2. 容量的应用维度来源, 业务请求的Query Per Second/Transaction Per Second/DML Per Second/活跃用户数
3. 找出容量阈值的方法: 人为制造压力/重放线上流量/实时线上流量引流
4. 容量规划的方法论:
收集系统指标: 平均数/标准差/95%th/99%th
具体技术: 移动平均/指数移动平均(Load Average的计算公式)/相关性分析/ARIMA预测分析
Reflecting a Year After Migrating to Apache Traffic Server
By Nick Berry
LinkedIn 使用Apache Traffic Server作为CDN的使用经验.
简要介绍了LinkedIn为什么选择使用ATS.
迁移到ATS的详细过程与迁移方法
在迁移过程中遇到的哪些问题,都是如何解决的.
traffic_logstat的的内容/实现以及对于他们运维带来的好处
No related posts.

原文地址:Velocity 2013 上几个不错的主题推荐, 感谢原作者分享。

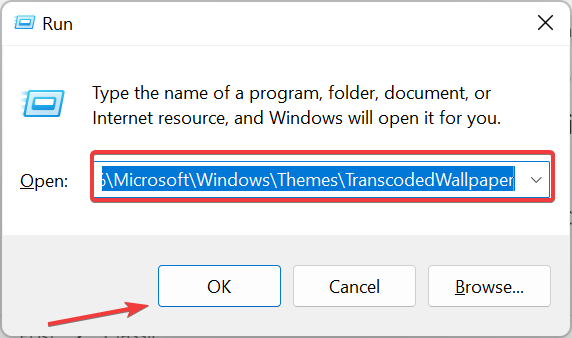 主题背景位于 Windows 11 中的什么位置?Aug 01, 2023 am 09:29 AM
主题背景位于 Windows 11 中的什么位置?Aug 01, 2023 am 09:29 AMWindows11具有如此多的自定义选项,包括一系列主题和壁纸。虽然这些主题以自己的方式是美学,但一些用户仍然想知道他们在Windows11上的后台位置。本指南将展示访问Windows11主题背景位置的不同方法。什么是Windows11默认主题背景?Windows11默认主题背景是一朵盛开的抽象宝蓝色花朵,背景为天蓝色。这种背景是最受欢迎的背景之一,这要归功于操作系统发布之前的预期。但是,操作系统还附带了一系列其他背景。因此,您可以随时更改Windows11桌面主题背景。主题背景存储在Windo
 如何详细介绍win10主题文件夹的位置Dec 27, 2023 pm 09:37 PM
如何详细介绍win10主题文件夹的位置Dec 27, 2023 pm 09:37 PM最近很多小伙伴觉得win10的主题不符合自己的审美,想更换主题,在网上下载以后,发现找不到文件夹了,那么接下来小编就带你们去如何寻找win10主题在哪里文件夹吧。win10主题在哪个文件夹:一、Win10系统壁纸默认存放路径位置:1、微软将这些图片保存在C:\Windows\Web\Wallpaper这个路径中,其下有是三个不同主题的图片的默认保存位置,2、鲜花和线条和颜色的主题图片也保存在同名文件夹下!命名原则就是imgXXX,我们只要按照这个原则更改我们希望设定的相关图片的名称,将图片粘贴到
 如何在 Windows 11 中取消应用主题(更改或删除)Sep 30, 2023 pm 03:53 PM
如何在 Windows 11 中取消应用主题(更改或删除)Sep 30, 2023 pm 03:53 PM主题对于希望修改Windows体验的用户起着不可或缺的作用。它可能会更改桌面背景、动画、锁定屏幕、鼠标光标、声音和图标等。但是,如果您想在Windows11中删除主题怎么办?这同样简单,并且有一些选项可用,无论是当前用户配置文件还是整个系统,即所有用户。此外,您甚至可以删除Windows11中的自定义主题,如果它们不再用于该目的。如何找到我当前的主题?按+打开“设置”应用>从导航窗格中转到“个性化”>单击“主题”>当前主题将列在右侧。WindowsI如何
 win10主题背景图片位置Jan 05, 2024 pm 11:32 PM
win10主题背景图片位置Jan 05, 2024 pm 11:32 PM有的朋友想要找到自己系统主题图片,但是不知道win10主题图片存放在哪里,其实我们只需要进入c盘的Windows文件夹,就可以找到主题图片位置了。win10主题图片存放位置答:win10主题图片存放在c盘的“themes”文件夹。1、首先我们进入“此电脑”2、接着打开“c盘”(系统盘)3、然后进入其中的“Windows”文件夹。4、在其中找到并打开“resources”文件夹。5、进入后,打开“themes”文件夹。6、在文件夹里就能看到win10主题图片了。Windows主题图片是特殊的格式,
 PHP爬虫类库推荐:如何选择最适合的工具?Aug 07, 2023 am 10:42 AM
PHP爬虫类库推荐:如何选择最适合的工具?Aug 07, 2023 am 10:42 AMPHP爬虫类库推荐:如何选择最适合的工具?在互联网时代,信息爆炸性增长使得获取数据变得非常重要。而爬虫就是一种非常重要的工具,它可以自动化地从互联网上获取数据并进行处理。在PHP开发中,选择一个适合的爬虫类库是非常关键的。本文将介绍几个常用的PHP爬虫类库,并提供相应的代码示例,帮助读者选择最适合的工具。GoutteGoutte是一个使用PHP进行网页抓取的
 如何调整WordPress主题避免错位显示Mar 05, 2024 pm 02:03 PM
如何调整WordPress主题避免错位显示Mar 05, 2024 pm 02:03 PM如何调整WordPress主题避免错位显示,需要具体代码示例WordPress作为一个功能强大的CMS系统,受到了许多网站开发者和站长的喜爱。然而,在使用WordPress创建网站时,经常会遇到主题错位显示的问题,这对于用户体验和页面美观都会造成影响。因此,合理调整WordPress主题以避免错位显示是非常重要的。本文将介绍如何通过具体的代码示例来进行主题调
 微信变成黑色主题怎么调回来Feb 05, 2024 pm 02:12 PM
微信变成黑色主题怎么调回来Feb 05, 2024 pm 02:12 PM微信软件中我们可以使用黑色主题模式也可以使用默认主题模式,那么有的用户微信变成黑色主题了,想要调回来要怎么操作呢?现在就来看一下-微信变成黑色主题调回来方法吧。1、首先打开微信进入到首页之后点击右下角的【我的】;2、然后在我的页面点击【设置】;3、接着来到设置的页面中点击【通用】;4、进入到通用的页面中点击【深色模式】;5、最后在深色模式的页面中点击【普通模式】即可;
 找win10主题的文件夹位置Jun 30, 2023 pm 12:57 PM
找win10主题的文件夹位置Jun 30, 2023 pm 12:57 PMwin10主题在哪个文件夹怎么找?最近很多小伙伴都觉得win10的主题不符合他们自己的审美,想要改变主题,在网上下载后,发现找不到文件夹,然后小边会带你去找如何找到win文件夹的主题在哪里?win10主题在哪个文件夹详细介绍一、Win10系统壁纸默认存放路径位置:1、微软将这些图片保存在C:WindowsWebWallpaper这个路径中,其下有是三个不同主题的图片的默认保存位置,2、鲜花和线条和颜色的主题图片也保存在同名文件夹下!命名原则就是imgXXX,我们只要按照这个原则更改我们希望设定的


热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

mPDF
mPDF是一个PHP库,可以从UTF-8编码的HTML生成PDF文件。原作者Ian Back编写mPDF以从他的网站上“即时”输出PDF文件,并处理不同的语言。与原始脚本如HTML2FPDF相比,它的速度较慢,并且在使用Unicode字体时生成的文件较大,但支持CSS样式等,并进行了大量增强。支持几乎所有语言,包括RTL(阿拉伯语和希伯来语)和CJK(中日韩)。支持嵌套的块级元素(如P、DIV),

SublimeText3 英文版
推荐:为Win版本,支持代码提示!

Dreamweaver Mac版
视觉化网页开发工具

Atom编辑器mac版下载
最流行的的开源编辑器

禅工作室 13.0.1
功能强大的PHP集成开发环境

