


一、题外篇 今天很悲催啊,给用户数据做datapatch的时候,每个月的数据多导入了一份,瞬间惊出一身冷汗... 这可是产品环境,要是被老板知道了可就死定了,赶紧去掉重复的记录,同时写下下面的文章以备后用。 二、准备篇 1. 先创建一张学生表student: create
一、题外篇
今天很悲催啊,给用户数据做datapatch的时候,每个月的数据多导入了一份,瞬间惊出一身冷汗... 这可是产品环境,要是被老板知道了可就死定了,赶紧去掉重复的记录,同时写下下面的文章以备后用。
二、准备篇
1. 先创建一张学生表student:
create table student(
id varchar(10) not null,
name varchar(10) not null,
age number not null
);
2. 插入几条数据到表student:
insert into student values('1', 'zhangs', 20); insert into student values('1', 'zhangs', 20); insert into student values('2', 'zhangs', 20); insert into student values('3', 'lisi', 20); insert into student values('4', 'lisi', 30); insert into student values('5', 'wangwu', 30);

三、处理篇
1. 使用rowid
① 查询:
select *
from student s1
where rowid != (select max(rowid)
from student s2
where s1.id = s2.id
and s1.name = s2.name
and s1.age = s2.age)
注: rowid是唯一标志记录物理位置的一个id, 括号中是查询出重复数据中rowid最大的一条.
② 删除:
delete from student s1
where rowid != (select max(rowid)
from student s2
where s1.id = s2.id
and s1.name = s2.name
and s1.age = s2.age)
2. 使用 group by 和 having
① 查询:
select id, name, age, count(*) from student group by id, name, age having count(*) > 1;
3. 使用distinct
create table stud_temp as select distinct * from student; -- 创建临时表 stud_temp truncate table student; -- 清空student表 insert into student select * from stud_temp; -- 将临时表数据导入student表 drop table stud_temp; -- 删除临时表
注: distinct只适用于对小表处理, 如果是千万级别数据的表, 请使用rowid, 因为它具有唯一性, 效率更高.

![从 Windows 10/11 中删除用户帐户的 5大方法 [2023]](https://img.php.cn/upload/article/000/465/014/168782606547724.png) 从 Windows 10/11 中删除用户帐户的 5大方法 [2023]Jun 27, 2023 am 08:34 AM
从 Windows 10/11 中删除用户帐户的 5大方法 [2023]Jun 27, 2023 am 08:34 AM您的WindowsPC上有多个过时的帐户?或者,由于某些错误,您是否在从系统中删除这些帐户时陷入困境?无论出于何种原因,您都应该尽快从计算机中删除那些未使用的用户帐户。这样,您将节省大量空间并修复系统中可能的漏洞点。在本文中,我们通过详细步骤详细阐述了多种用户帐户删除方法。方法1–使用设置这是从系统中删除任何帐户的标准方法。步骤1–按Win+I键应打开“设置”窗口。步骤2–转到“帐户”。第3步–找到“其他用户”将其打开。第4步–您将在屏幕右侧找到所有帐户。步骤5–只需在那里扩展帐户即可。在帐户和
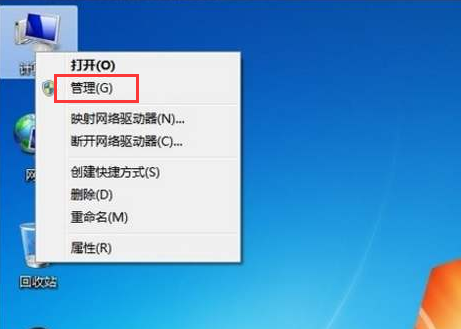 windows7系统如何删除administrator账户的详细教程Jul 11, 2023 pm 10:09 PM
windows7系统如何删除administrator账户的详细教程Jul 11, 2023 pm 10:09 PMwindows7系统如何删除administrator账户呢?很多用户的电脑当中都有多个administrator账户,不过有些账户是使用不到的,所以我们可以删除那些没有必要的管理员账户,那么win7系统如何删除administrator账户呢?今天为大家分享win7系统删除administrator账户的方法。感兴趣的小伙伴们快来看看吧!1、首先,右键点击桌面上的“计算机”图标,菜单栏选择“管理”。2、在计算机管理界面中,依次展开“系统工具——>本地用户——>用户”选项。3、然后在
 怎么彻底删除快应用May 31, 2023 am 09:48 AM
怎么彻底删除快应用May 31, 2023 am 09:48 AM彻底删除快应用的方法:1、打开手机设置界面,点击打开“应用设置”;2、在应用设置界面,选择“应用管理”点击打开;3、进入应用管理界面,界面选择“快应用服务框架”点击打开;4、进入快应用服务框架界面,选择“卸载更新”选项并打开;5、界面显示窗口点击“确定”即可彻底删除快应用。
 Win7系统删除多余的本地连接2Jul 19, 2023 pm 06:21 PM
Win7系统删除多余的本地连接2Jul 19, 2023 pm 06:21 PM在查看Win7系统的计算机网络连接时,有时会发现除了本地连接外,还有一个本地连接2。了解后,我们知道这是一个多余的网卡本地连接地址。由于本地连接2的存在,有时本地连接无法连接,因此无法上网。我们如何删除多余的本地连接2?Win7系统删除多余的本地连接2。1.点击开始菜单,搜索运行按下回车键或直接按Windows键(窗口)+R键,打开运行对话框;2.在运行对话框中输入regedit,并按确定键;3.在注册表编辑器中,展开到HKEY_LOCAL_MCHINE\SYSTEM\Curentcontrol
 如何通过PHP ZipArchive实现对压缩包中文件的删除操作?Jul 21, 2023 pm 07:29 PM
如何通过PHP ZipArchive实现对压缩包中文件的删除操作?Jul 21, 2023 pm 07:29 PM如何通过PHPZipArchive实现对压缩包中文件的删除操作?概述:ZipArchive是PHP中用于创建和读取ZIP压缩文件的类。除了创建和读取,ZipArchive还提供了其他一些操作,例如删除、重命名、复制和解压缩等。本文将重点介绍如何使用ZipArchive类来删除压缩包中的文件。步骤:在进行删除操作之前,我们需要先打开压缩包并检查是否存在目标文
 文件不会在 Windows 11 上删除?强制擦除它们的4种方法Jul 07, 2023 pm 12:21 PM
文件不会在 Windows 11 上删除?强制擦除它们的4种方法Jul 07, 2023 pm 12:21 PM许多Windows11用户抱怨由于某种原因无法从他们的PC中删除。这可能很烦人,因为它会阻止用户释放内存或删除不需要的文件。但是,我们将讨论为什么文件不会在Windows11上删除以及如何修复它。另外,您可能对我们的文章感兴趣,如果文件资源管理器删除的文件仍显示在您的计算机上,该怎么办。为什么我的电脑不允许我删除文件?如果您不是文件所有者或您的用户帐户没有适当的访问权限,则可能会发生这种情况。该文件可能正被另一个程序或进程使用,从而阻止其被删除。操作系统或第三方程序可能会锁定文件或文件夹。如果计
 哈医大临床药学就业是否有前途(哈医大临床药学就业前景怎么样)Jan 02, 2024 pm 08:54 PM
哈医大临床药学就业是否有前途(哈医大临床药学就业前景怎么样)Jan 02, 2024 pm 08:54 PM哈医大临床药学就业前景如何尽管全国就业形势不容乐观,但药科类毕业生仍然有着良好的就业前景。总体来看,药科类毕业生的供给量少于需求量,各医药公司和制药厂是吸纳这类毕业生的主要渠道,制药行业对人才的需求也在稳步增长。据介绍,近几年药物制剂、天然药物化学等专业的研究生供需比甚至达到1∶10。临床药学专业就业方向:临床医学专业学生毕业后可在医疗卫生单位、医学科研等部门从事医疗及预防、医学科研等方面的工作。就业岗位:医药代表、医药销售代表、销售代表、销售经理、区域销售经理、招商经理、产品经理、产品专员、护
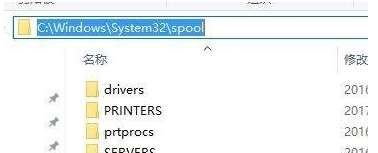 Win7打印机无法删除如何解决Jul 15, 2023 pm 10:33 PM
Win7打印机无法删除如何解决Jul 15, 2023 pm 10:33 PM如果您希望删除所安装的打印机,我们使用Win7系统通常将其删除设备和打印机中的打印机图标,但有些用户反馈,用户在把打印机取下来后,一刷打印机一刷又会重来,觉得不能删除,碰到这种问题时该如何解决,现在小编就跟大家一起来看看。Win7打印机无法删除如何解决。1.进入桌面后,按Win+R的组合键打开运行窗口,在运行时输入"spool",然后点击确定;2.在此之后,您将进入路径为"C:\Windows\System32\spool"的文件夹,如图所示;3.在spo


热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

SublimeText3汉化版
中文版,非常好用

PhpStorm Mac 版本
最新(2018.2.1 )专业的PHP集成开发工具

EditPlus 中文破解版
体积小,语法高亮,不支持代码提示功能

螳螂BT
Mantis是一个易于部署的基于Web的缺陷跟踪工具,用于帮助产品缺陷跟踪。它需要PHP、MySQL和一个Web服务器。请查看我们的演示和托管服务。

适用于 Eclipse 的 SAP NetWeaver 服务器适配器
将Eclipse与SAP NetWeaver应用服务器集成。

