
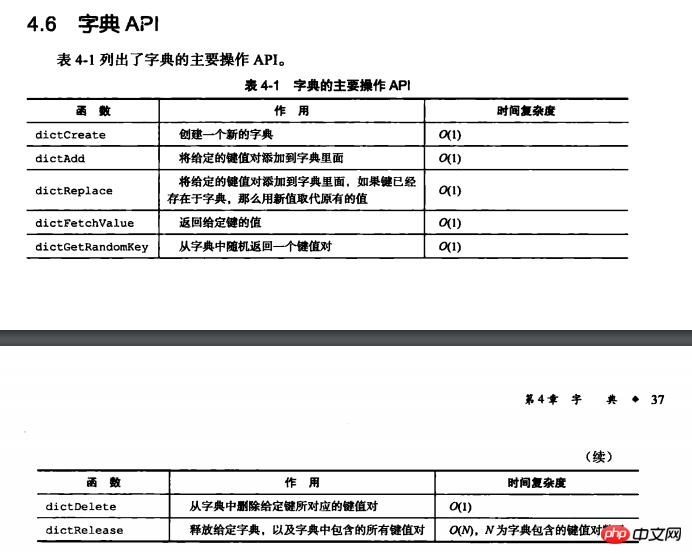
最近在看redis的設計與實作一書,看到字典這一章節時,發現redis字典的增刪改查操作的複雜度都是O(1):
對此不太懂,看了它的資料結構,感覺不應該是O(1)的複雜度,給定一個key,去查value的話如果不是定長並且有序的儲存結構,怎麼可能是O (1)的複雜度?

伊谢尔伦2017-04-24 16:02:29
下圖是Hash Table的示意圖:
主要是優化Hash Function,尽可能的减少冲突。也就是防止不同的key映射到相同的value上了,雖說即使衝突了也沒什麼。 。 。
參考:
http://www.tutorialspoint.com/data_structures_algorithms/hash_data_structure.htm 不確定是否需要翻牆。
PS:演算法導論可以看看。 。 。
仅有的幸福2017-04-24 16:02:29
看來題主是不知道什麼是hash啊,建議把資料結構的基礎先打好,再去研究redis基於資料結構的應用。
當然,hash的複雜度O(1)是指的平均複雜度,同時也是最理想狀態下的,最壞情況下是O(n)
