
环境:
windows 10
PyCharm 2016.3.2
遇到问题:
刚开始学python,想用BeautifulSoup解析网页,但出现报错:
UserWarning: No parser was explicitly specified, so I'm using the best available HTML parser for this system ("lxml"). This usually isn't a problem, but if you run this code on another system, or in a different virtual environment, it may use a different parser and behave differently.
The code that caused this warning is on line 4 of the file C:/Users/excalibur/PycharmProjects/learn/getMyIP.py. To get rid of this warning, change code that looks like this:
BeautifulSoup([your markup])
to this:
BeautifulSoup([your markup], "lxml")
markup_type=markup_type))然后根据提示和官网的文档加上:BeautifulSoup(markup, "html.parser")
结果出现了这样的报错:

在Google搜了下,都是说要导入路径,但是在 Settings -> Project -> Project Interpreter 里是这样的
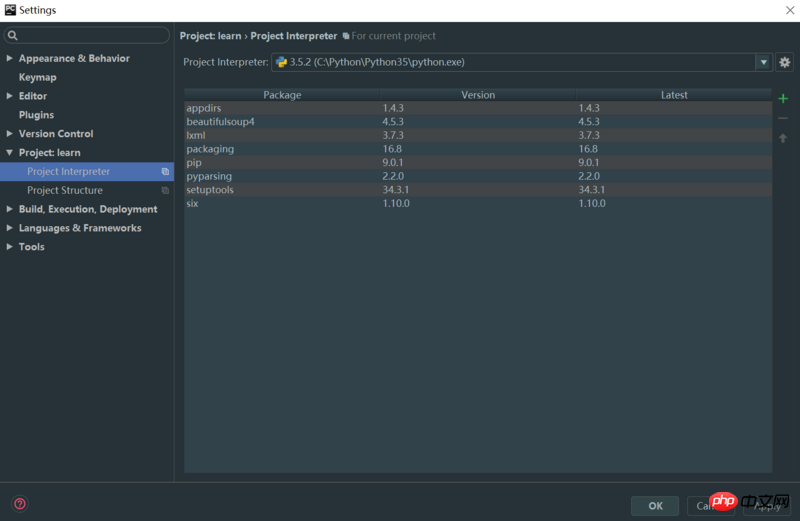
显示BeautifulSoup已经导入了
请问我要怎么做才能解决这个问题呢?
万分感谢!

阿神2017-04-18 10:27:19
找了其他人的程式碼來看,終於知道是什麼問題
並不是路徑的問題,而是傳參的問題
markup 其實是要解析的內容,例如:
soup = BeautifulSoup("<html>data</html>", "lxml")或
markup = "<html>data</html>"
soup = BeautifulSoup(markup, "lxml")PS. 在文件中沒有函數參數列表之類的,不知道是不是找的位置錯了...
