
能不能实现这种:
aItem的数据由aPipeline处理
bItem的数据由bPipeline处理

天蓬老师2017-04-18 09:51:55
目的是不是這樣呢,
比如你items.py有以下幾個item
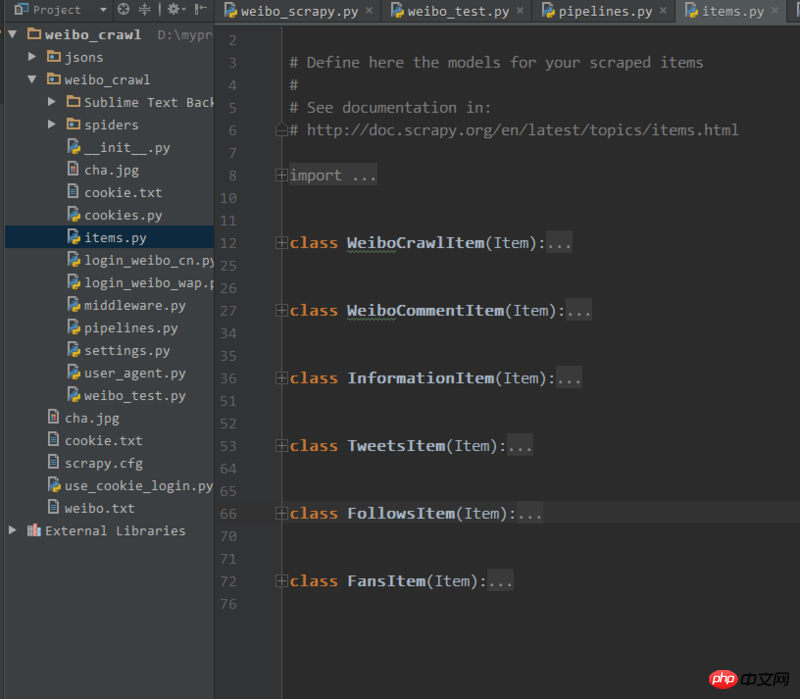
然後在pipelines.py中的process_item函數裡可以如下操作
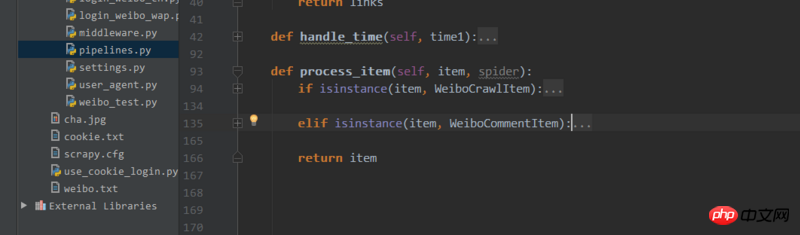
這樣就可以把不同的資料分開處理了,
天蓬老师2017-04-18 09:51:55
你可以在 pipeline 裡判斷是哪個爬蟲的結果:
def process_item(self, item, spider):
if spider.name == 'news':
#这里写存入 News 表的逻辑
news = News()
...(省略部分代码)
self.session.add(news)
self.session.commit()
elif spider.name == 'bsnews':
#这里写存入 News 表的逻辑
bsnews = BsNews()
...(省略部分代码)
self.session.add(bsnews)
self.session.commit()
return item
對於這種多個爬蟲在一個工程裡的,需要不同爬蟲在 pipeline 裡使用不同邏輯的問題 scrapy 的作者是這麼解釋的。
去看看

